
Meta AI stellt Emu Video und Emu Edit für die textbasierte Bild- und Videobearbeitung vor. Das Modell basiert auf dem Bildmodell Emu.
Das neue Video-Modell von Meta kann aus Text und Bildern viersekündige Videos generieren. Qualitativ soll es kommerziellen Angeboten wie Runway Gen-2 und Pika Labs überlegen sein. Diese Aussagen treffen die Forschenden auf der Basis von menschlichen Bewertungen der generierten Videos.
Emu Video macht aus Texten Bilder, und aus Text und Bild dann Videos
Grundlage für Emu Video ist das Bildmodell Emu, das Meta auf der Connect 2023 im Herbst vorstellte. Emu Video verwendet eine einheitliche Architektur für Video-Generierungsaufgaben und verarbeitet Text- und Bild-Prompts oder kombinierte Prompts.
Der Prozess gliedert sich in zwei Schritte: Zuerst werden Bilder auf der Basis eines Text-Prompts generiert, dann wird ein Video auf der Basis sowohl des Textes als auch des generierten Bildes erzeugt.
Dadurch kann das Modell die visuelle Vielfalt und den Stil des Text-Bild-Modells beibehalten, was laut Meta AI die Erstellung von Videos erleichtert und die Qualität der Ausgabe verbessert.
"The American flag waving during the moon landing with the camera panning." | Video: Meta AI
"a ship driving off the harbor." | Video: Meta AI
Dieser "faktorisierte" Ansatz ermöglicht es Meta, Videogenerierungsmodelle effizient zu trainieren und direkt hochauflösende Videos zu generieren. Das Modell verwendet zwei Diffusionsmodelle, um 512x512 vier Sekunden lange Videos mit 16 Bildern pro Sekunde zu erzeugen. Die Forscherinnen und Forscher haben bereits mit Videos von bis zu acht Sekunden Länge experimentiert und gute Ergebnisse erzielt.
Für die menschliche Bewertung der Videos entwickelte das Team das Bewertungssystem JUICE (JUstify their choICE). Bei diesem Ansatz müssen die Bewerter ihre Entscheidungen beim Vergleich der Videoqualität anhand vorformulierter Kriterien begründen, was die Zuverlässigkeit des Bewertungsprozesses erhöhen soll.
Die Qualitätsfaktoren sind: Pixelschärfe, flüssige Bewegung, erkennbare Objekte/Szenen, Bildkonsistenz und Bewegungsumfang. Für die Prompt-Treue sind es die räumliche und zeitliche Anordnung der Motive im Video.
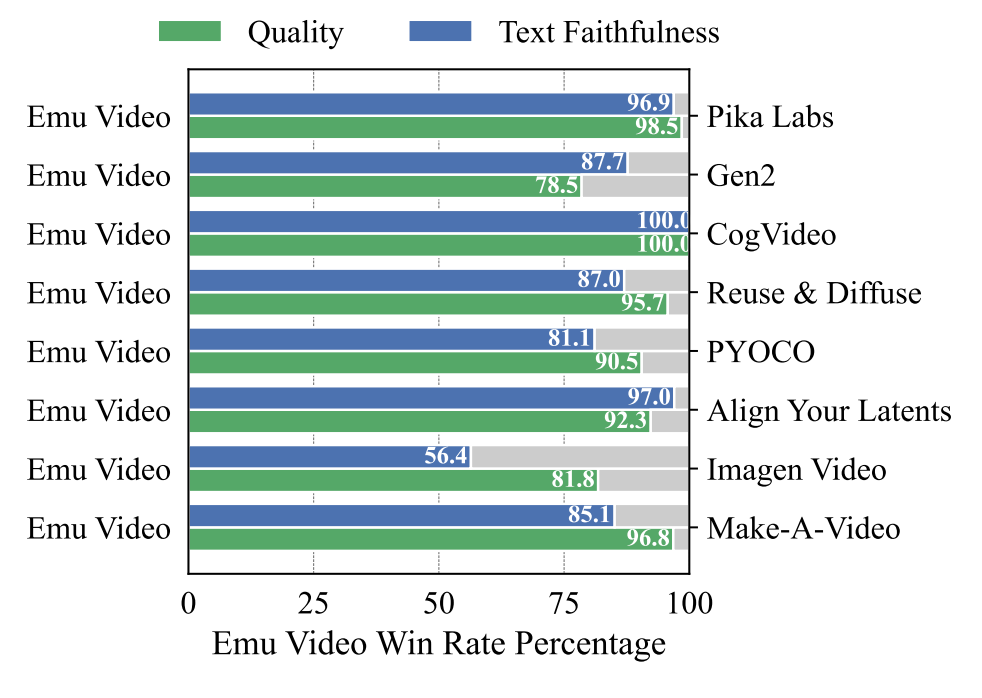
Nach diesem Messverfahren übertrifft Emu Video alle bisherigen Prompt-to-Video-Modelle deutlich: In menschlichen Evaluationen wurden die mit dem Meta-Modell generierten Videos in mehr als 95 Prozent der Fälle qualitativ und quantitativ den mit Pika Labs generierten Videos vorgezogen.
Im Vergleich zu RunwayML Gen-2 wurde Emu Video in rund 88 Prozent der Fälle in der Prompt-Genauigkeit und in 78,5 Prozent der Fälle in der Qualität vorgezogen. Lediglich Imagen Video von Google wird bei der Prompt-Genauigkeit nicht ganz abgehängt, liegt aber immer noch weit zurück (56,4 %).
Viele weitere Videobeispiele und eine interaktive Demo gibt es auf der Emu-Video-Webseite.
Emu Edit: Textbasierte Bildbearbeitung
Emu Edit zielt darauf ab, verschiedene Bildmanipulationsaufgaben zu vereinfachen und die Bildbearbeitungsfähigkeiten zu verbessern.
Das Modell bietet freie Videobearbeitung nur durch Prompting in natürlicher Sprache, einschließlich lokaler und globaler Bearbeitung, Entfernen und Hinzufügen eines Hintergrunds, Farb- und Geometrietransformationen, Erkennung und Segmentierung und mehr.
Der Schwerpunkt liegt darauf, nur die Pixel zu verändern, die für die Editieranfrage relevant sind. Pixel im Video, die nicht vom Prompt adressiert werden, bleiben laut Meta unberührt.
Für das Training des Modells hat Meta einen Datensatz mit zehn Millionen synthetisierten Beispielen für 16 Bildverarbeitungsaufgaben entwickelt, die jeweils ein Eingabebild, eine Beschreibung der auszuführenden Aufgabe und das gewünschte Ausgabebild enthalten. Ferner verwendet das Modell erlernte Task-Embeddings, die den Generierungsprozess in Richtung des richtigen Bearbeitungstyps lenken.
Emu Edit ist auch in der Lage, neue Aufgaben wie Image Inpainting, Super Resolution und Kombinationen von Editing-Aufgaben mit nur wenigen beschrifteten Beispielen zu verallgemeinern. Diese Fähigkeit ist besonders nützlich in Szenarien, in denen qualitativ hochwertige Beispiele selten sind.
Die Forscher stellten außerdem fest, dass Computer-Vision-Aufgaben die Editierleistung deutlich verbessern und dass die Leistung von Emu Edit mit der Anzahl der Trainingsaufgaben steigt.
In Evaluationen zeigte Emu Edit eine überlegene Leistung gegenüber aktuellen Methoden und erreichte neue Spitzenwerte in qualitativen und quantitativen Bewertungen für eine Vielzahl von Bildverarbeitungsaufgaben.
Das Modell soll bestehende Modelle bei der Einhaltung der Editieranweisungen und der Erhaltung der visuellen Qualität des Originalbildes deutlich übertreffen. Die Forscher planen, Emu Edit weiter zu verbessern und seine Anwendungsmöglichkeiten zu erforschen.
Die Einsatzmöglichkeiten von Emu Video und Emu Edit sind vielfältig und reichen von der Erstellung animierter Sticker oder GIFs bis hin zur Bearbeitung von Fotos und Bildern - technische Vorkenntnisse sind nicht erforderlich. Derzeit sind Emu Video und Emu Edit jedoch noch reine Forschungsarbeiten.
Wie bei anderen KI-Modellen wird Meta versuchen, die Fähigkeiten dieser generativen Modelle in seine eigenen Kommunikationsprodukte wie Instagram und WhatsApp zu integrieren, um den Nutzern mehr Interaktions- und Ausdrucksmöglichkeiten zu bieten.




