Factorio als Benchmark: Viele LLMs scheitern an komplexen Aufgaben des Aufbauspiels

Manche Computerspiele eignen sich, um die Fähigkeiten von Sprachmodellen zu testen. Jetzt haben Forschende KI-Modelle auf das anspruchsvolle Aufbauspiel Factorio losgelassen.
Das Factorio Learning Environment (FLE) bietet zwei Hauptmodi: "Lab-Play" umfasst 24 strukturierte Aufgaben mit definierten Zielen und begrenzten Ressourcen. In ersterem reichen die Aufgaben vom Bau einfacher Strukturen mit zwei Maschinen bis zu Fabriken mit fast 100 Maschinen. Im "Open-Play"-Modus wird der KI-Agent auf einer prozedural generierten Karte platziert und hat das offene Ziel, die größtmögliche Fabrik zu bauen.
Agenten interagieren mit dem FLE über eine Python-API. Sie generieren Code, um Aktionen auszuführen und den Spielstatus abzufragen. Diese Art der Interaktion soll es den LLMs ermöglichen, ihre Fähigkeiten in der Programmsynthese und im Umgang mit komplexen Systemen unter Beweis zu stellen. Die API bietet Funktionen zum Platzieren und Verbinden von Entitäten, zum Verwalten von Ressourcen und zum Überwachen des Produktionsfortschritts.
Die Leistung der Agenten wird anhand von zwei Metriken bewertet: Dem "Production Score", der den Gesamtwert der produzierten Objekte misst und exponentiell mit der Komplexität der Produktionsketten skaliert, und "Milestones", die wichtige Fortschritte wie die Herstellung neuer Objekte oder die Erforschung neuer Technologien markieren. Die Simulation von Factorio berücksichtigt Faktoren wie Ressourcenknappheit und Produktionseffizienz.
Claude 3.5 Sonnet zeigt beste Leistung, aber löst nicht alle Aufgaben
Das Paper der drei Forschenden, von denen einer bei Anthropic arbeitet, evaluiert mehrere aktuelle Sprachmodelle in FLE: Claude 3.5 Sonnet, GPT-4o und GPT-4o mini, DeepSeek-V3, Gemini 2.0 Flash sowie Llama-3.3-70B-Instruct.
Die Ergebnisse zeigen, dass selbst die fortschrittlichsten Modelle Schwierigkeiten haben, komplexe Aufgaben zu bewältigen. Insbesondere beim räumlichen Denken, der Langzeitplanung und der Fehlerkorrektur zeigten sich Schwächen. Die Agenten hatten etwa Probleme, Maschinen und Strukturen effizient anzuordnen und zu verbinden, was zu suboptimalen Layouts und Engpässen führt.
Sie konzentrierten sich oft auf kurzfristige Ziele und vernachlässigten langfristige Strategien. Und obwohl sie einfache Fehler beheben können, scheiterten sie oft an der Diagnose und Behebung komplexerer Probleme, was zu wiederholten Fehlern und ineffizienten Debugging-Schleifen führte.
Sonnet 3.5 baut eine möglichst große Factorio-Fabrik. | Video: Hopkins et al.
Claude 3.5 Sonnet zeigte in den Experimenten die beste Leistung, konnte aber auch nicht alle Herausforderungen von FLE meistern. Im Lab-Play löste Claude 15 von 24 Aufgaben, während die anderen Modelle maximal 10 Aufgaben bewältigten. Im Open-Play erreichte Claude einen Production Score von 2.456 Punkten, gefolgt von GPT-4o mit 1.789 Punkten.
Claude 3.5 Sonnet zeigt bemerkenswerte Factorio-Fähigkeiten, indem es sich schnell auf komplexe Produktionsprozesse konzentrierte und in die Forschung investierte. Ab einer bestimmten Stufe aktiviert es den Einsatz von Elektrobohrern, was zu einem deutlichen Anstieg der Produktion von Eisenplatten führt, wie der steile Anstieg der entsprechenden Kurve zeigt (siehe Grafik unten rechts). Im Gegensatz dazu beschränken sich die anderen Modelle im dargestellten Zeitraum auf die Herstellung einfacher Produkte.
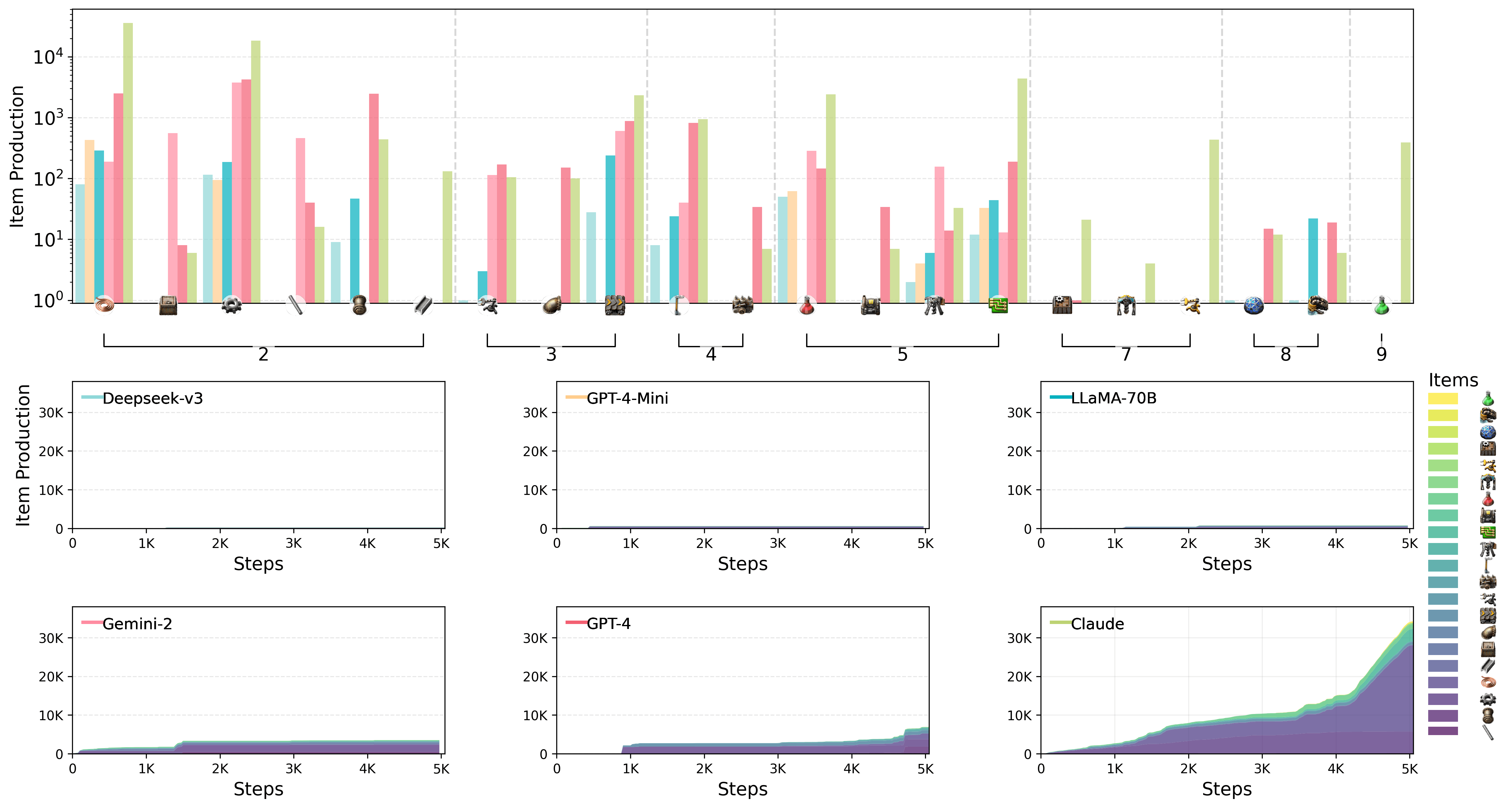
Die offene und skalierbare Natur von FLE soll laut den Wissenschaftler:innen die Umgebung auch für zukünftige, womöglich leistungsfähigere LLMs relevant machen. Reasoning-Modelle wurden noch nicht abgebildet. Mögliche Erweiterungen sind auch die Integration von Multi-Agenten-Szenarien und die Entwicklung einer menschlichen Baseline zur besseren Einordnung der KI-Leistung.
Computerspiele dienen immer wieder als Benchmark für KI-Modelle, etwa durch die Spielesammlung BALROG. Der kommende "MCBench" soll Modelle anhand von Minecraft-Bauten auf die Probe stellen. Auch OpenAI hat bereits fortgeschrittene Spiele-KIs gezeigt, die sogar ganze menschliche Profiteams schlagen konnten.
Korrektur: Angaben zu Factorio ergänzt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.