Forscher definieren einheitlich, was ein Weltmodell ist – und was nicht

Kurz & Knapp
- Was genau ein World Model ist, war bisher Auslegungssache. Ein internationales Team will das mit einem neuen Framework klären.
- Als Weltmodelle gelten Systeme, die ihre Umgebung wahrnehmen, mit ihr interagieren und sich Dinge merken. Text-zu-Video-Modelle wie Sora fallen bewusst raus, da ihnen die Rückkopplung mit der realen Welt fehlt.
- Das zugehörige Open-Source-Projekt OpenWorldLib vereint fünf Module für Eingabeverarbeitung, Synthese, Reasoning, 3D-Rekonstruktion und Gedächtnis.
Ein internationales Forschungsteam will mit OpenWorldLib Ordnung in die zerstreute World-Model-Forschung bringen. Text-zu-Video-Modelle wie Sora fallen dabei ausdrücklich nicht unter die Definition.
Der Begriff "World Model" ist in der KI-Forschung allgegenwärtig, doch was genau darunter fällt, war bisher Auslegungssache. Ein Team um die Peking University, Kuaishou Technology (verantwortlich u. a. für den Videogenerator Kling), die National University of Singapore, Tsinghua und weitere Institutionen will das mit OpenWorldLib ändern. Das zugehörige Paper schlägt sowohl eine standardisierte Definition als auch ein einheitliches Open-Source-Framework vor, das verschiedene World-Model-Aufgaben unter einem Dach vereint.
Ein World Model muss laut den Forschern auf Wahrnehmung aufbauen, mit seiner Umgebung interagieren können und sich dabei Dinge langfristig merken, um die Dynamiken einer komplexen Welt zu verstehen und vorherzusagen. Entscheidend sei nicht, was das Modell ausgibt, sondern ob es multimodale Eingaben aus der echten Welt nutzt, um seine Umgebung zu analysieren und darauf zu reagieren.
Sora ist laut den Forschern kein World Model
Die wohl provokanteste Abgrenzung betrifft die Text-to-Video-Generierung. Als OpenAI sein mittlerweile eingestelltes Videomodell Sora vorstellte, wurde es vielfach als "World Simulator" bezeichnet. Auch Deepmind-CEO Demis Hassabis sah im Google-Videomodell Veo einen Schritt hin zu Weltmodellen.
Die Autoren widersprechen ausdrücklich und schließen sich damit der Meinung von Persönlichkeiten wie Yann LeCun an: Zwar zeige Videogenerierung ein gewisses Verständnis physikalischer Zusammenhänge, doch fehle die entscheidende Rückkopplung mit der realen Welt. Ein Modell, das nur aus Text Videos erzeugt, nimmt seine Umgebung nicht wahr und interagiert nicht mit ihr. Text-zu-Video bleibe daher "außerhalb der Kernaufgaben von World Models", so das Paper.
Ebenso schließen die Forscher Code-Generierung, Web-Suche und Avatar-Video-Generierung aus der Definition aus. Avatar-Videos etwa fokussierten auf Unterhaltung und hätten wenig mit dem Verstehen der physischen Welt zu tun.

Interaktion statt bloße Generierung
Statt passiver Medienerzeugung rücken die Forscher drei Aufgabenbereiche in den Mittelpunkt:
- Bei der interaktiven Videogenerierung sagt ein Modell auf Basis vorheriger Frames und Nutzereingaben den nächsten Frame voraus. Anders als bei Text-to-Video reagiert es dabei auf Aktionen wie Steuerbefehle oder Kamerabewegungen.
- Multimodales Reasoning beschreibt die Fähigkeit, aus Bildern, Videos und Audio räumliche, zeitliche und kausale Zusammenhänge abzuleiten, etwa um zu verstehen, welches Objekt sich wo befindet oder warum etwas passiert ist.
- Und bei Vision-Language-Action leitet das Modell aus visuellen Eindrücken und Sprachanweisungen konkrete Bewegungsbefehle für Roboterarme oder autonome Fahrzeuge ab.
Ergänzend sehen die Forscher 3D-Rekonstruktion und Simulatoren als wichtige Bausteine. Sie liefern eine überprüfbare Umgebung, in der physikalische Regeln strikt eingehalten werden können. Reine Videovorhersage liefert dagegen nur eine visuelle Schätzung der Zukunft, ohne dass sich physikalische Konsistenz garantieren ließe.

Fünf Module unter einer Pipeline
Das Softwareprojekt OpenWorldLib bündelt diese Fähigkeiten in einer modularen Architektur. Ein Operator-Modul bringt verschiedenste Eingaben wie Text, Bilder oder Sensordaten in ein einheitliches Format. Das Synthesis-Modul erzeugt Bilder, Videos, Audio und Steuerbefehle. Das Reasoning-Modul verarbeitet räumliche, visuelle und akustische Zusammenhänge. Ein Representation-Modul erstellt 3D-Rekonstruktionen und Simulationsumgebungen. Und das Memory-Modul speichert Interaktionsverläufe, damit das System über mehrere Schritte hinweg konsistent bleibt.
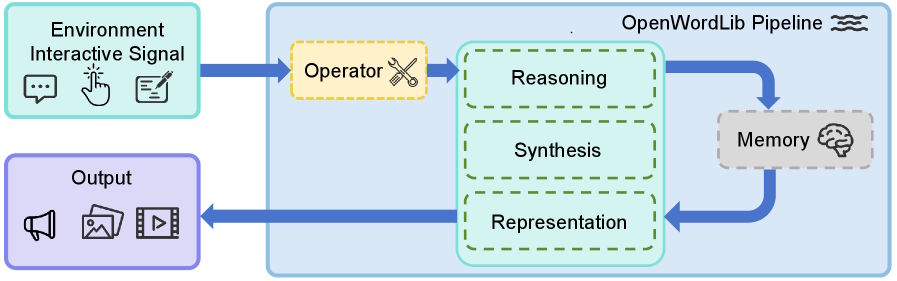
Eine übergeordnete Pipeline orchestriert alle Module und bietet eine einheitliche Schnittstelle. Forscher sollen so verschiedene Modelle und Methoden innerhalb desselben Frameworks vergleichen können, statt jedes Mal eigene Infrastruktur aufzubauen.
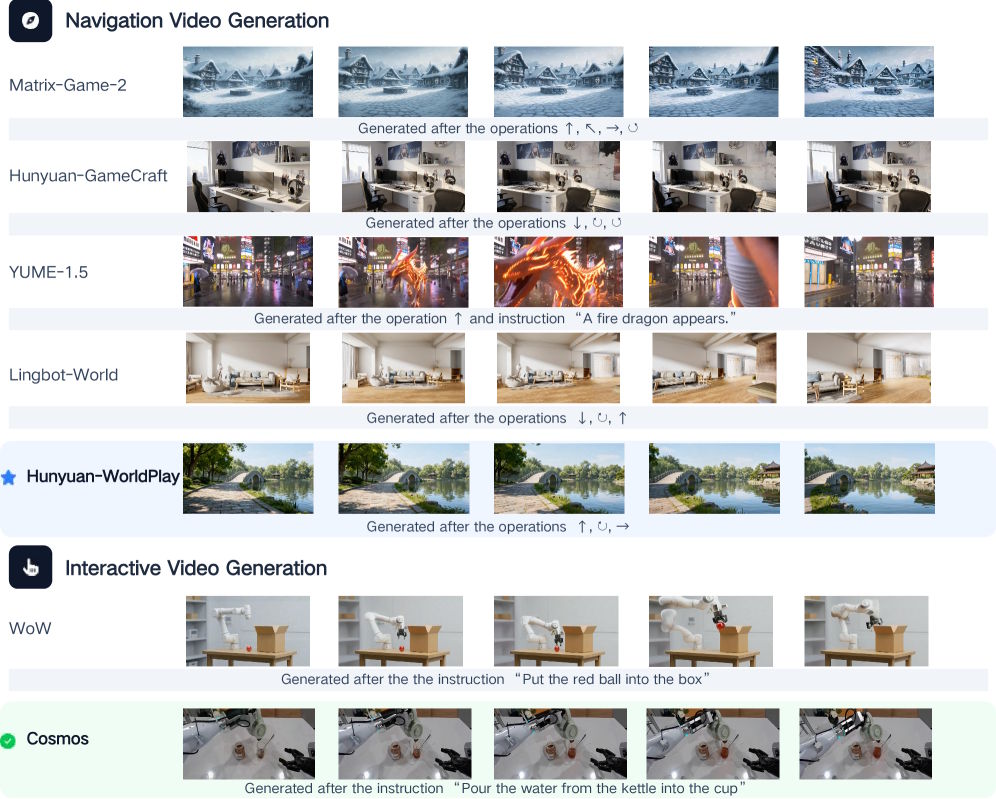
Hunyuan-WorldPlay und Cosmos führen bei ersten Tests
In Evaluierungen auf Nvidias A800- und H200-GPUs verglichen die Forscher bestehende Modelle innerhalb ihres Frameworks. Bei interaktiver Videogenerierung für Navigationsszenen erzielte Hunyuan-WorldPlay die beste visuelle Qualität. Nvidias Cosmos lag bei komplexen interaktiven Szenarien vorn, in denen das Modell auf vielfältige Nutzereingriffe reagieren musste. Frühere Ansätze wie Matrix-Game-2 generierten zwar schnell, zeigten aber deutliche Farbverschiebungen bei längeren Sequenzen.
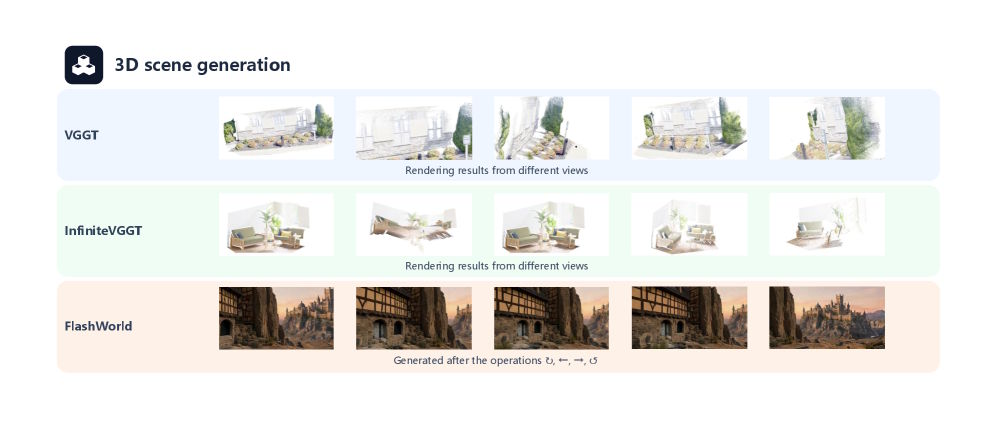
Bei der 3D-Szenenrekonstruktion offenbarten Modelle wie VGGT und InfiniteVGGT Schwächen. Sobald sich die Kamera stark bewegte, traten geometrische Inkonsistenzen und unscharfe Texturen auf. Die Forscher sehen 3D-Generierung dennoch als fundamental für die Weiterentwicklung von World Models.
Heutige Chips bremsen World Models aus
Über die reine Framework-Arbeit hinaus formulieren die Autoren eine grundsätzliche Kritik an der aktuellen Hardware. Heutige Computerchips sind auf die Verarbeitung einzelner Tokens optimiert. Selbst wenn ein Modell ganze Videoframes vorhersagen soll, werden die Daten intern Stück für Stück als Tokens verarbeitet. Das sei ineffizient für die datenintensive Wahrnehmung, die ein echtes World Model leisten müsse. Nötig seien neue Chiparchitekturen und möglicherweise eine Abkehr vom Transformer, der derzeit fast allen großen KI-Modellen zugrunde liegt.
Als pragmatische Zwischenlösung sehen die Autoren aktuelle Vision-Language-Modelle und verweisen auf Bagel, das mit der Qwen-Architektur sowohl multimodales Reasoning als auch Bildgenerierung beherrscht. Das zeige, dass auf Internetdaten vortrainierte Sprachmodelle prinzipiell alle nötigen Fähigkeiten mitbringen könnten, auch wenn der Weg zum vollständigen World Model noch weit sei.
OpenWorldLib ist als Open-Source-Projekt auf GitHub verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren