Sind große Sprachmodelle in der Lage, logische Schlüsse zu ziehen, oder erinnern sie sich nur an Ergebnisse in ihren Trainingsdaten?
Dieser Frage geht ein Forschungsteam von Consequent AI um Saurabh Srivastava nach, das sich auf schlussfolgernde KI spezialisiert hat.
Das Team stellt die gängige Praxis des KI-Benchmarkings infrage, die typischerweise auf statischen Frage-Antwort-Paaren basiert, die eine KI während ihres umfangreichen Trainings mit Internetdaten bereits gesehen haben könnte.
Diese traditionelle Benchmarking-Methode könne die scheinbare Intelligenz einer Maschine fälschlicherweise überbewerten, indem sie Auswendiglernen mit echtem Denken verwechsle.
Um dem entgegenzuwirken, führen die Autoren der Studie das Konzept der "funktionalen Varianten" für Benchmark-Tests ein. Dabei werden etablierte Benchmarks wie der MATH-Benchmark verwendet und die zugrunde liegenden Denkprozesse in Code umgesetzt.
Dieser Code, in diesem Fall MATH() genannt, kann dann verschiedene "Snapshots" erzeugen, das sind einzigartige Fragen, die die gleichen Überlegungen zur Lösung erfordern, aber nicht mit den ursprünglichen Fragen identisch sind.
Auf diese Weise werden traditionelle Benchmarks wie der MATH-Benchmark zu kodierten Formaten, die auf unendlich viele Arten verändert werden können, während sie immer noch die gleiche zugrunde liegende Logik testen. Dieses Testverfahren soll sicherstellen, dass Sprachmodelle tatsächlich Problemlösungsfähigkeiten demonstrieren und nicht nur auswendig gelernte Fragen wiederholen.
"Denklücke" bei großen Sprachmodellen
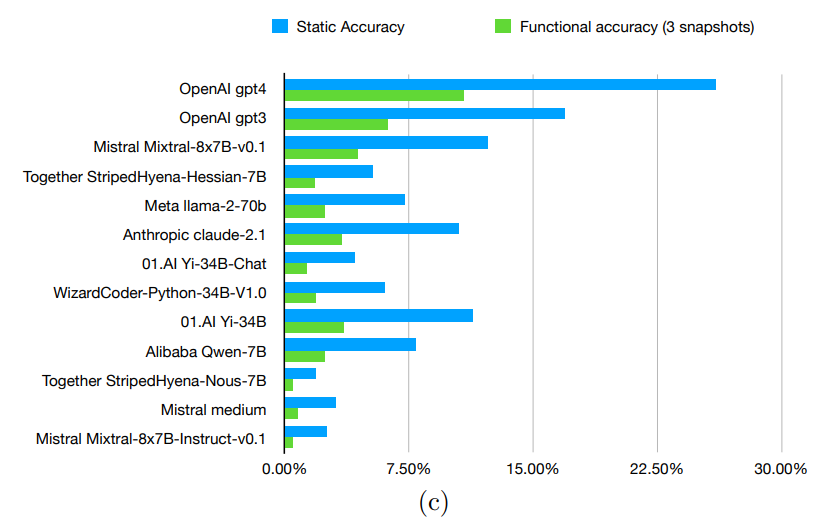
Bei der Evaluierung verschiedener fortgeschrittener Modelle, einschließlich GPT-3.5 und GPT-4 von OpenAI, identifizierten die Forscher das, was sie eine "Denklücke" nennen - eine Diskrepanz zwischen der Leistung eines Modells bei bekannten Problemen im Vergleich zu neuen Problemen, die es spontan lösen muss.
Die gemessenen Lücken lagen zwischen 58,35 Prozent und 80,31 Prozent, was darauf hindeutet, dass die Modelle Schwierigkeiten haben, die funktionalisierten Formen der Probleme zu bewältigen.
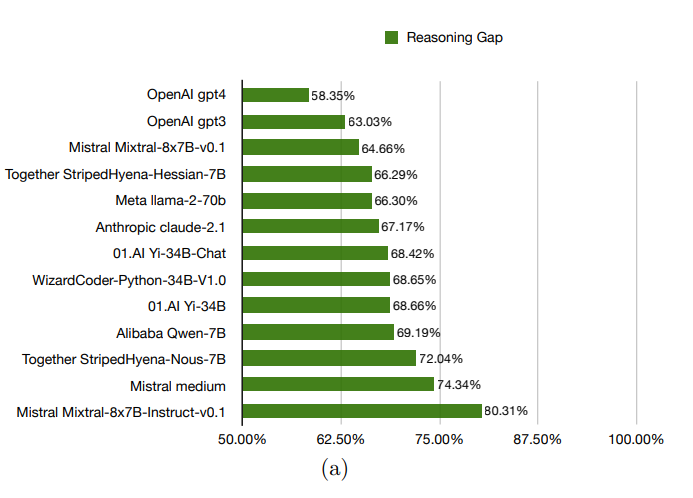
Das wiederum kann als Anzeichen dafür gewertet werden, dass die Modelle die Probleme nicht wirklich verstehen, sondern die Antworten aus ihren umfangreichen Trainingsdaten ziehen.
Die Forscher analysierten auch, welche Arten von Problemen die Modelle erfolgreich lösen konnten. Sie stellten fest, dass sie vorwiegend bei Aufgaben mit niedrigerem Schwierigkeitsgrad und bei Aufgaben aus den Bereichen Präalgebra und Algebra besser abschnitten.
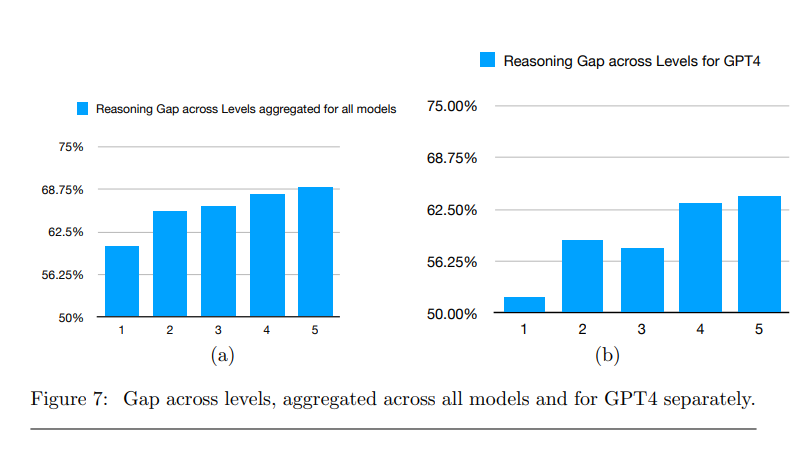
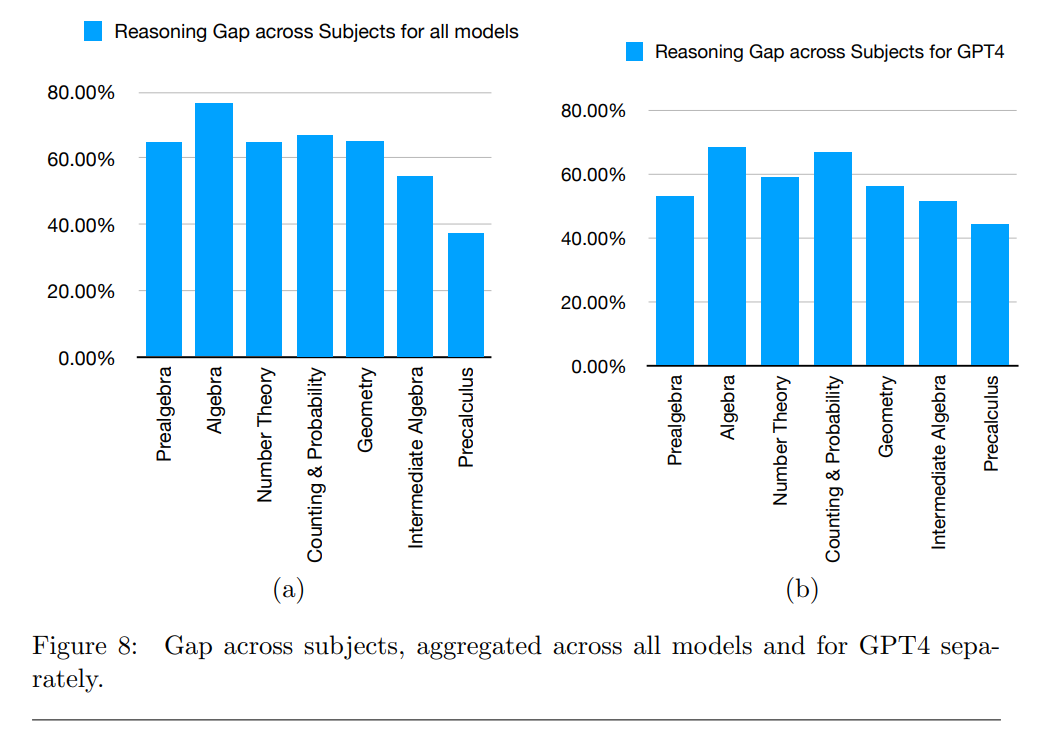
Als mögliche Einschränkungen der Ergebnisse nennen die Autoren verschiedene Faktoren, wie den potenziellen Einfluss von komplexeren Prompts oder die Verwendung von Rechenwerkzeugen während des Inferenzprozesses, die die Denklücke verringern könnten.
Das Team von Consequent AI hat bereits 41,2 Prozent des MATH-Benchmarks funktionalisiert und ihre Forschungsergebnisse, den Code sowie drei Snapshots des funktionalen MATH()-Benchmarks öffentlich zugänglich gemacht.
Bisher haben sie neun Open-Source-Modelle und vier geschlossene Modelle evaluiert. Das Paper und das GitHub Repository enthalten detaillierte Informationen über ihren Ansatz und ihre Ergebnisse.
Für die Zukunft plant das Forschungsteam die Veröffentlichung funktionalisierter Versionen weiterer Benchmarks mit dem Ziel einer 100-prozentigen Abdeckung von MATH, GSM8K und HumanEval. Außerdem soll der Einfluss von Prompting-Strategien auf die Denklücke getestet werden.
Auch KI-Denkfähigkeit ist eine Skala
Eine Sichtweise der Forschungsergebnisse könnte auch sein, dass die Denklücke nicht bei 100 Prozent lag - dass also die Fähigkeit, logische Schlussfolgerungen zu ziehen, in den Modellen angelegt ist, eine Frage, die allgemein noch diskutiert wird.
GPT-4 konnte immerhin rund zehn Prozent der dynamischen Aufgaben korrekt lösen (541 von 5000). Allerdings liegt es mit diesem Ergebnis nur geringfügig vor kleineren, effizienteren Modellen.
Der KI-Forscher François Chollet bietet dazu eine Perspektive. Er beschreibt vier Stufen der Generalisierungsfähigkeit, wobei die meisten LLMs derzeit auf Stufe 1 operieren: Sie haben Antworten auf eine statische Menge von Aufgaben auswendig gelernt und können zwischen ihnen interpolieren.
Auf Stufe 2 würden Modelle generalisierbare Programme ausführen, um Aufgaben innerhalb einer statischen Menge von Aufgaben robust zu lösen. LLMs könnten einige dieser Aufgaben lösen, aber sie seien darin nicht gut und datenineffizient, schreibt Chollet.
Stufe 0 wäre eine einfache Datenbank ohne Denkfähigkeit, Stufe 3 die Fähigkeit, auf Anfrage neue Programme zu generieren, die neue Probleme lösen. "Das wäre allgemeine Intelligenz."