Forscher zeigen, wie KI-Modelle menschliche Fähigkeiten übertreffen könnten

Forschende der Shanghai Jiao Tong University, der Fudan University, des Shanghai AI Laboratory und des Generative AI Research Lab haben eine Methode entwickelt, mit der stärkere KI-Modelle ihre Fähigkeiten zum logischen Schlussfolgern verbessern können - allein durch die Anleitung schwächerer Modelle.
Die Entwicklung von Superintelligenz, also von KI-Systemen, die menschliche kognitive Fähigkeiten übertreffen, bleibt ein zentrales Ziel im Bereich der Künstlichen Intelligenz.
Mit zunehmender Leistungsfähigkeit der KI-Modelle stoßen jedoch herkömmliche Feedbackmethoden und KI-Trainings an ihre Grenzen, da der Mensch darin eine entscheidende Rolle spielt.
Um dieses Problem anzugehen, stellt das Forschungsteam das "Weak-to-Strong"-Lernparadigma vor. Es soll starken Modellen helfen, ihr volles Potenzial zu entfalten, ohne auf menschliche Annotationen oder noch stärkere Modelle angewiesen zu sein.
Es handelt sich um einen zweistufigen Trainingsansatz, bei dem das starke Modell seine Trainingsdaten selbstständig verfeinert.
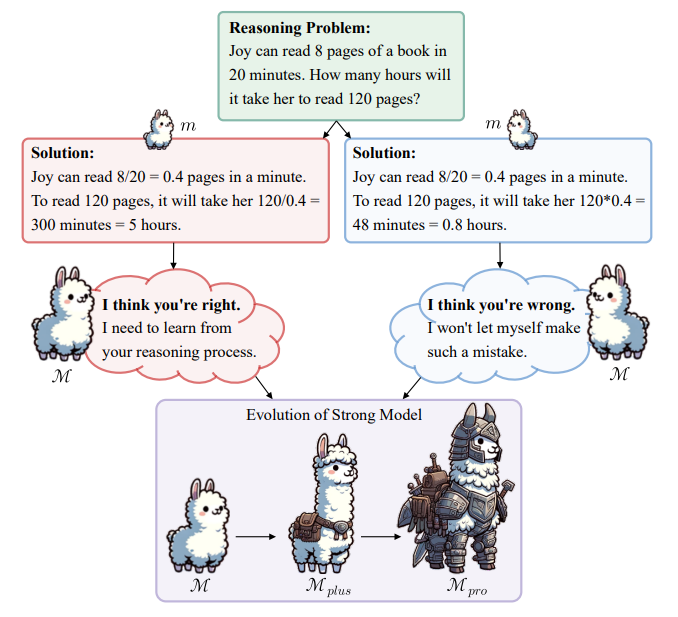
In der ersten Stufe kombinieren die Forscher vom schwachen Modell (Llama2-7b, Gemma-2b und Mistral-7b) generierte Daten mit Daten, die das starke Modell (Llama2-70b) selbst durch "In-Context Learning" (Generierung mit Beispielen) erzeugt. Damit kuratieren sie selektiv Datensätze für das nachfolgende überwachte Finetuning.
In der zweiten Stufe wird das starke Modell durch Präferenzoptimierung weiter verbessert, indem es aus den Fehlern des schwachen Modells lernt.
KI optimiert Trainingsdaten besser als Menschen
Erste Ergebnisse aus Experimenten zeigen, dass der neue Ansatz deutlich besser abschneidet als einfaches Finetuning auf unbearbeiteten Daten. Im GSM8K-Benchmark für mathematische Aufgaben konnte die Leistung des starken Modells, das nur vom schwachen Gemma-2b-Modell beaufsichtigt wurde, um bis zu 26,99 Punkte gesteigert werden.
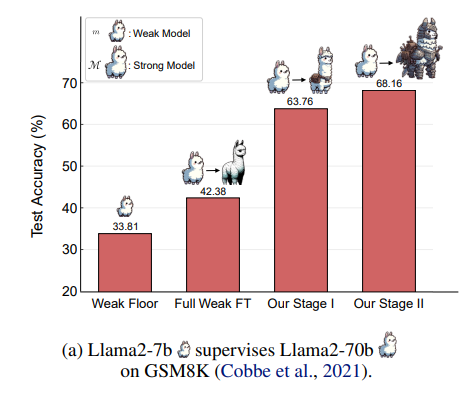
Eine weitere Verbesserung um 8,49 Punkte wurde durch die Präferenzoptimierung erreicht. Damit übertrifft die Methode sogar das Finetuning auf Goldstandard-Lösungen.
Die Forscher betonen, dass ihre Methode es dem starken Modell ermöglicht, seine mathematischen Fähigkeiten kontinuierlich zu erweitern, indem es seine Trainingsdaten selbstständig verfeinert. Diese selbstgesteuerte Verfeinerung der Daten sei entscheidend für die Skalierung und Verbesserung der Fähigkeiten der KI.
Die Methode ist interessant, weil sie einen Ansatz zeigt, wie KI durch selbstständige Verfeinerung von Trainingsdaten Aufgaben bewältigen kann, für die es noch keine vordefinierten Lösungen durch Menschen oder KI gibt und für die herkömmliche Methoden der Feinabstimmung versagen. Es zeigt, wie fortgeschrittene KI-Modelle auch dann noch verbessert werden können, wenn die menschliche Aufsicht an ihre Grenzen stößt.
Auch der ehemalige OpenAI-Forscher Andreji Karpathy sieht in der Verwendung von KI-Modellen zur Optimierung von Trainingsdaten einen möglichen nächsten Treiber für KI-Fortschritte. KI könne den "perfekten Datensatz" für KI entwickeln.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.