Forscher zweifeln an "Reasoning"-Modellen: Effizienter ja, intelligenter nein

Update –
Das unten besprochene Paper wurde auf der Fachkonferenz NeurIPS (Neural Information Processing Systems) mit der bestmöglichen Punktzahl ausgezeichnet. Die NeurIPS gilt als eine der führenden wissenschaftlichen Konferenzen zum Thema maschinelles Lernen.
Kritiker des Papers entgegnen, dass die Ergebnisse durch die sehr hohen Durchläufe in den LLM-Tests (pass@k mit großem k) nicht messen, wie gut oder verständlich ein Modell denkt, sondern nur, ob es irgendwann zufällig richtig liegt. Zudem könne man die größere Konsistenz von RL‑trainierten Modellen nicht zwangsläufig als Nachteil, sondern auch als Zeichen tieferer „intelligenter“ Fokussierung interpretieren.
Eine aussagekräftigere Evaluation wäre daher nicht nur zu prüfen, ob ein Modell irgendwann eine korrekte Lösung erzeugt, sondern ob es systematisch korrekte Reasoning-Schritte vollzieht und häufiger zu einer richtigen Schlussfolgerung gelangt.
Die Autoren geben zu, dass pass@1024 bei Aufgaben mit wenigen möglichen Antworten wie AIME durch Zufall beeinflusst werden kann. Sie betonen jedoch, dass sie das gleiche Muster auch bei schwierigeren Aufgaben gesehen haben – zum Beispiel bei Programmier- und Mathematiktests –, bei denen reines Raten nicht funktioniert.
Ihre manuelle Analyse zeige zudem, dass Basismodelle in vielen Fällen korrekte logische Lösungswege hervorbringen. Damit sehen sie ihre These bestätigt, dass große, vortrainierte Basismodelle über ein bislang unterschätztes Reasoning-Potenzial verfügen.
Gleichzeitig kündigen sie an, in zukünftigen Arbeiten explizite Zufalls-Baselines einzuführen, um den Einfluss von Glückstreffern methodisch kontrollieren zu können.
Die Autoren betonen auch, dass ihr Paper nicht aussagt, dass Reinforcement Learning grundsätzlich kein besseres oder über das Basismodell hinausgehendes Reasoning auslösen kann. Sie wollen mit weiteren Experimenten herausfinden, ob und wie RL die Denkfähigkeiten großer Sprachmodelle verbessern kann. Außerdem schließen sie nicht aus, dass sich die Ergebnisse ändern könnten, wenn Modelle oder Trainingsdaten größer werden.
Artikel vom 22. April 2025:
Eine neue Studie stellt infrage, ob Reinforcement Learning mit verifizierbaren Belohnungen (RLVR) tatsächlich die Denkfähigkeiten großer Sprachmodelle verbessert – oder lediglich dabei hilft, bekannte Lösungswege effizienter zu reproduzieren.
Forschende der Tsinghua University und der Shanghai Jiao Tong University zeigen in einer Studie, dass RLVR zwar die Wahrscheinlichkeit erhöht, beim ersten Versuch eine richtige Antwort zu generieren – das sogenannte pass@1 –, aber keine neuen Problemlösestrategien erschließt. Wenn das ursprüngliche Modell eine Aufgabe nicht lösen kann, gelingt es auch dem RLVR-Modell nicht.
Reinforcement Learning für Reasoning-Modelle kommt primär bei Aufgaben zum Einsatz, bei denen es objektiv richtige oder falsche Antworten gibt – etwa Mathematik oder Programmieren. Statt auf menschlichem Feedback basieren die Belohnungen hier auf automatisch überprüfbaren Kriterien, etwa korrekten Rechenergebnissen oder bestandenen Codetests. RLVR ist die technische Innovation beim Training von Reasoning-Modellen wie OpenAIs o-Serie oder Deepseek-R1.
"RLVR befähigt ein Modell nicht dazu, Aufgaben zu lösen, die es vorher nicht lösen konnte", schreibt Studienleiter Yang Yue auf X. Das Potenzial der Methode sei deutlich geringer als bisher angenommen.
RLVR fokussiert auf bekannte Pfade – auf Kosten neuer Lösungen
Die Studie legt nahe, dass RLVR die Vielfalt der erzeugten Antworten – in der Fachsprache: die Entropie – verringert. Die Modelle konzentrieren sich nach dem Training stärker auf eine kleine Anzahl häufig belohnter Lösungspfade. Das verbessert die Trefferquote bei einzelnen Versuchen, schränkt aber die Vielfalt der Lösungsansätze bei mehreren Durchläufen ein.
Um die Wirkung von RLVR zu untersuchen, verglichen die Forschenden Basismodelle mit RLVR-Varianten anhand der pass@k-Metrik. Sie misst, ob unter mehreren generierten Antworten mindestens eine richtige dabei ist. Bei wenigen Versuchen schneiden RLVR-Modelle besser ab, da sie gezielt stark belohnte Lösungsmuster bevorzugen. Wenn man die Anzahl der Versuche erhöht, liefern die unbeeinflussten Basismodelle durch ihre größere Antwortvielfalt insgesamt mehr korrekte Ergebnisse – unabhängig vom konkreten Test oder Modelltyp.
Video: Yue et al.
Die Forschenden prüften den Effekt in drei Bereichen: Mathematik, Programmieren und visuelles Reasoning. In allen Fällen zeigte sich das gleiche Muster: RLVR-Modelle liefern bei einem einzelnen Versuch häufig korrekte Antworten, verlieren aber bei mehreren Versuchen an Vielfalt und Gesamtleistung.
Eine manuelle Überprüfung der Denkketten (CoTs) bestätigte zudem, dass die Basismodelle auch bei schwierigen Aufgaben, die zuvor nur RL-Modellen zugeschrieben wurden, durch vielfältige Lösungsansätze zum richtigen Ergebnis kommen können.
Visualisierungen der Antwortpfade zeigen: Die erfolgreichen Lösungsstrategien der RLVR-Modelle stammen alle aus dem bereits vorhandenen Verhaltensspektrum der Basismodelle. RLVR erhöht lediglich deren Wahrscheinlichkeit – es erschließt keine neuen Wege.
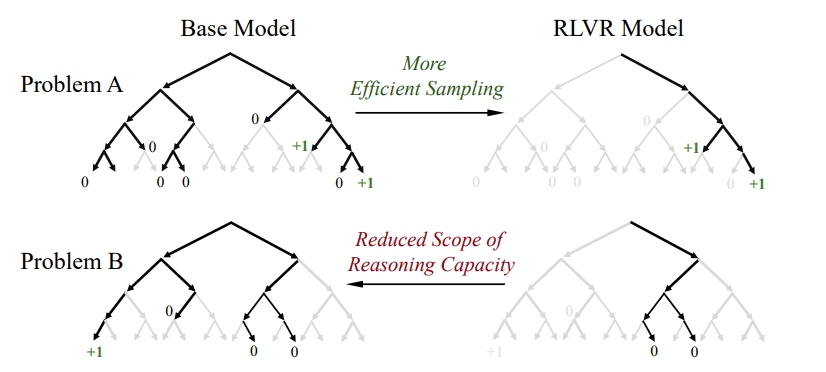
Während RLVR also die Effizienz bei der Lösungsfindung verbessert, führt es laut Studie nicht zu echtem Wissenszuwachs. Im Gegensatz dazu kann Wissensdistillation – das Lernen von stärkeren Modellen – neue Fähigkeiten tatsächlich ins Modell übertragen.
RLVR ist nützlich – aber nicht umfassend
Yang Yue betont, dass gerade die beschränkte Wirkung von RLVR der zentrale Punkt der Studie sei. Die Methode mache KI-Modelle nicht fähiger, sondern nur effizienter im Wiederholen bereits bekannter Lösungen.
Der KI-Forscher Nathan Lambert sieht die Ergebnisse im erwartbaren Rahmen. Reinforcement Learning sei darauf ausgelegt, gewünschte Verhaltensweisen gezielt zu verstärken – das verringere zwangsläufig die Antwortvielfalt. Dass Basismodelle bei vielen Versuchen besser abschneiden, sei eine direkte Folge davon.
Gleichzeitig weist Lambert auf methodische Einschränkungen der Studie hin: Das RL-Training wurde ausschließlich auf eng gefassten Datensätzen wie MATH und GSM8K durchgeführt. Diese eignen sich zwar gut für kontrollierte Vergleiche, erlauben aber keine Aussagen über die grundsätzlichen Grenzen von Reinforcement Learning. Entscheidend sei – so Lambert – das Skalieren von RL auf breitere Aufgabenbereiche. Genau das sei mit so eingeschränkten Trainingsdaten kaum möglich. OpenAI und andere hätten bereits gezeigt, dass Skalierung ein zentraler Erfolgsfaktor für leistungsfähige RL-Systeme sei.
Die Studie ist damit keine generelle Absage an Reinforcement Learning, sondern eine präzise Analyse seiner Wirkung im aktuellen technischen Rahmen. "Wir kommen gerade an den Punkt, an dem wir schwierige Dinge tun müssen. Schwierige Dinge sind interessanter, aber – Überraschung – sie sind schwierig und dauern länger", schreibt Lambert.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.