Forschung zeigt: Hochwertige Bildungsdaten sind entscheidend für KI-Performance

Ein neuer Datensatz, FineWeb-Edu, zeigt, wie wichtig qualitativ hochwertige Lerninhalte für die Leistung großer Sprachmodelle sind.
Fineweb-Edu ist ein neuer, qualitativ hochwertiger Hugging-Face-Datensatz für das Training von Large Language Models (LLMs). Er basiert auf Fineweb, einem großen Web-Datensatz mit 15 Billionen Token, der aus 96 CommonCrawl-Snapshots gewonnen wurde.
Mit Hilfe eines Klassifikators, der mit den Ergebnissen der Bewertung von FineWeb-Artikeln durch ein Llama-3-70B-Instruct-Modell trainiert wurde, filterten die Forscherinnen und Forscher von Hugging Face Fineweb nach Bildungsinhalten und erstellten so Fineweb-Edu.
Nur Textdaten mit einem Bildungswert von mindestens 3 auf einer Skala von 1 bis 5 wurden in FineWeb-Edu aufgenommen. Dieser gefilterte Datensatz enthält noch 1,3 Billionen Token, weniger als ein Zehntel des ursprünglichen Datensatzes.
Die Wissenschaftler trainierten verschiedene LLMs mit 1,82 Milliarden Parametern auf jeweils 350 Milliarden Token mit FineWeb-Edu und anderen Datensätzen und verglichen die Leistung der Modelle in verschiedenen Benchmarks.
Das Ergebnis: FineWeb-Edu übertrifft den ungefilterten FineWeb-Datensatz und alle anderen öffentlichen Web-Datensätze deutlich, insbesondere bei Aufgaben, die Wissen und logisches Denken erfordern.
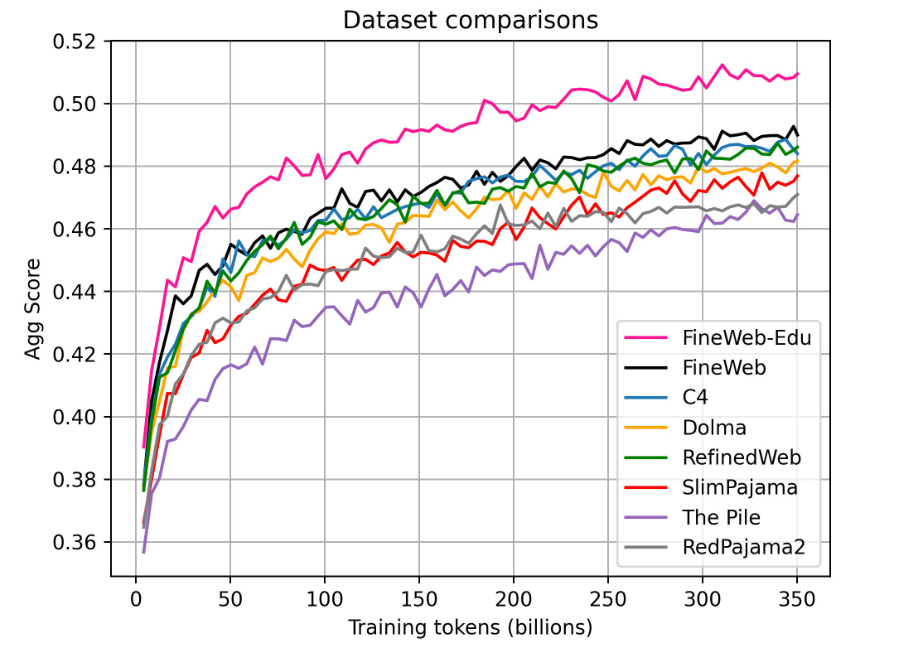
Um die gleiche Leistung wie FineWeb-Edu zu erreichen, benötigen andere Datensätze wie C4 oder Dolma bis zu zehnmal mehr Trainingsdaten. Das zeigt einmal mehr, wie effektiv es ist, sich auf qualitativ hochwertige Bildungsdaten zu konzentrieren.
Auch Microsoft hat mit der Forschungsarbeit "Textbooks is all you need" und den kleinen Phi-Modellen bereits gezeigt, dass qualitativ bessere Trainingsdaten die Leistung von Sprachmodellen verbessern können. Allerdings machte Microsoft seinen Klassifikator und Datensatz nicht öffentlich.
Datensätze für KI-Training: Qualität schlägt Quantität
Der KI-Experte Andrej Karpathy teilt diese Einschätzung: Die durchschnittliche Website im Internet sei so willkürlich und schrecklich, dass nicht einmal klar sei, wie frühere LLMs überhaupt etwas davon lernen konnten, so Karpathy.
"Man könnte meinen, dass es sich um zufällige Artikel handelt, aber das ist nicht der Fall. Es handelt sich um seltsamen Datenmüll, Werbespam und SEO, Terabytes von Börsenticker-Updates usw. Und dann sind da noch die Diamanten. Die Herausforderung besteht darin, sie herauszufiltern", schreibt Karpathy.
Die Forschenden hoffen, die Erkenntnisse aus FineWeb-Edu in Zukunft auch auf andere Sprachen anwenden zu können, um qualitativ hochwertige Webdaten für verschiedene Sprachräume zugänglich zu machen.
Neben dem nach Bildungswert gefilterten Datensatz mit 1,3 Billionen Token (sehr hoher Bildungsgehalt) stellen die Forschenden auch eine weniger stark gefilterte Variante mit 5,4 Billionen Token (hoher Bildungsgehalt) bei Hugging Face zur Verfügung. Beide Datensätze sind frei zugänglich, zudem beschreiben die Forschenden ausführlich ihre Systematik bei der Zusammenstellung des Datensatzes.
In Zukunft könnte beim KI-Training also Datenqualität und Vielfalt Priorität vor schierer Masse haben. Ergänzend könnten synthetische generierte Daten mit menschlicher Qualitätssicherung gezielt Lücken in den Datensätzen stopfen.
Diese Erkenntnis erklärt auch, warum OpenAI und andere LLM-Entwickler so sehr an Vereinbarungen mit etablierten Verlagen interessiert sind. Sie erhoffen sich dadurch Zugang zu hochwertigen Datenquellen wie Lehrbüchern, Zeitungsartikeln oder wissenschaftlichen Publikationen, die das Training ihrer Modelle verbessern können. Dieses Material wurde zum Teil bereits für GPT-4 und Co. verwendet, allerdings ohne Erlaubnis.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.