Gemini Diffusion: Google Deepmind stellt neue Sprachmodell-Technologie vor

Mit Gemini Diffusion testet Google Deepmind ein sprachbasiertes Diffusionsmodell, das Text schneller und kohärenter erzeugen soll.
Statt wie klassische Sprachmodelle Wörter nacheinander zu generieren, nutzt Gemini Diffusion ein Verfahren aus der Bild-KI: die schrittweise Verfeinerung von Rauschen. Dabei entstehen in mehreren Durchläufen aus Zufallsrauschen ganze Textabschnitte.
Der Prozess erlaubt laufende Korrekturen während der Generierung und soll laut Deepmind insbesondere bei Aufgaben wie Textbearbeitung oder Programmierung Vorteile bringen. Neben besserer Kontrolle verspricht der Ansatz auch deutlich höhere Geschwindigkeit.
Video: Google
Schnell und konkurrenzfähig
Gemini Diffusion verarbeitet ganze Abschnitte auf einmal – und das deutlich schneller als klassische autoregressive Modelle. Deepmind nennt eine Geschwindigkeit von 1.479 Token pro Sekunde (ohne Overhead), bei einer Anfangslatenz von 0,84 Sekunden. Brendan O'Donoghue, Forscher bei Deepmind, berichtet auf X sogar von bis zu 2.000 Token pro Sekunde inklusive Overheads wie Tokenisierung, Prefill und Sicherheitssysteme. Besonders bei Programmieraufgaben soll das Modell hier herausragen.
Oriol Vinyals, VP of Research & Deep Learning Lead bei Google Deepmind und Gemini-Co-Leiter, bezeichnete die Vorstellung von Gemini Diffusion als persönlichen Meilenstein: Es sei sein Ziel gewesen, die lineare "von links nach rechts"-Textgenerierung zu überwinden. Die Geschwindigkeit sei so hoch gewesen, dass man das Demovideo habe verlangsamen müssen.
Video: Google Deepmind
In Benchmarks schneidet Gemini Diffusion insgesamt ähnlich gut ab wie das Gemini 2.0 Flash-Lite-Modell. Bei Programmieraufgaben wie HumanEval (89,6 % vs. 90,2 %) und MBPP (76,0 % vs. 75,8 %) – zwei gängige Coding-Benchmarks – zeigen beide vergleichbare Ergebnisse. In LiveCodeBench (30,9 % vs. 28,5 %) und LBPP (56,8 % vs. 56,0 %) liegt Gemini Diffusion sogar leicht vorn.
Schwächer fällt das Modell dagegen im naturwissenschaftlichen Benchmark GPQA Diamond (40,4 % vs. 56,5 %) sowie im multilingualen Test Global MMLU Lite (69,1 % vs. 79,0 %) aus.
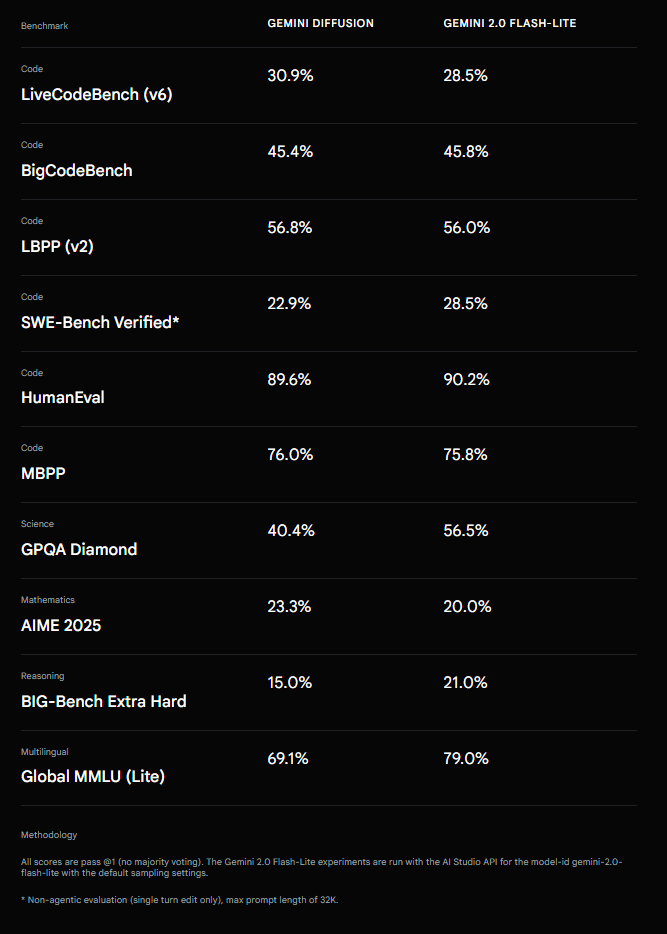
Jack Rae, Principal Scientist bei Google Deepmind, spricht angesichts der Resultate von einem "bemerkenswerten Moment": Autoregressive Modelle hätten bisher bei der Textqualität stets besser abgeschnitten als Diffusionsmodelle, und es sei unklar gewesen, ob sich diese Lücke überhaupt schließen lasse. Dass dies nun gelungen sei, sei das Resultat konsequenter Fokussierung und der Überwindung zahlreicher Forschungs- und Technikherausforderungen.
Derzeit ist Gemini Diffusion nur als experimentelle Demo verfügbar. Interessierte können sich auf eine Warteliste setzen lassen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.