GLM-Image: Offenes Bildmodell von Zhipu AI für exakte Prompts und starke Textdarstellung

Das chinesische KI-Unternehmen Zhipu AI setzt auf eine Kombination aus autoregressivem Sprachmodell und Diffusions-Decoder. Das Modell mit insgesamt 16 Milliarden Parametern soll besonders bei Text in Bildern und wissensintensiven Inhalten überzeugen.
Die Architektur teilt die Bilderzeugung in zwei spezialisierte Module auf. Ein autoregressives Modul mit 9 Milliarden Parametern, das auf dem Sprachmodell GLM-4 basiert, generiert zunächst eine semantische Repräsentation des Bildes.
Es arbeitet nach dem Prinzip der Wortvorhersage in Sprachmodellen: Token für Token entsteht eine Struktur, die Inhalt und Layout des Bildes festlegt. Ein Diffusions-Decoder mit 7 Milliarden Parametern übernimmt anschließend die Verfeinerung zu einem hochauflösenden Bild zwischen 1024 und 2048 Pixeln.

Semantische Bildbausteine statt reiner Pixelrekonstruktion
Eine zentrale Designentscheidung betrifft die Art, wie GLM-Image Bilder zerlegt. Statt klassischer VQVAE-Tokens (Vector Quantized Variational Autoencoder), die primär auf visuelle Rekonstruktion optimiert sind, verwendet das Modell semantische Tokens. Die tragen nicht nur Farbinformationen, sondern auch Bedeutung, etwa ob ein Bereich Text, ein Gesicht oder einen Hintergrund darstellt. Laut Zhipu AI lernt das Modell damit schneller und zuverlässiger.
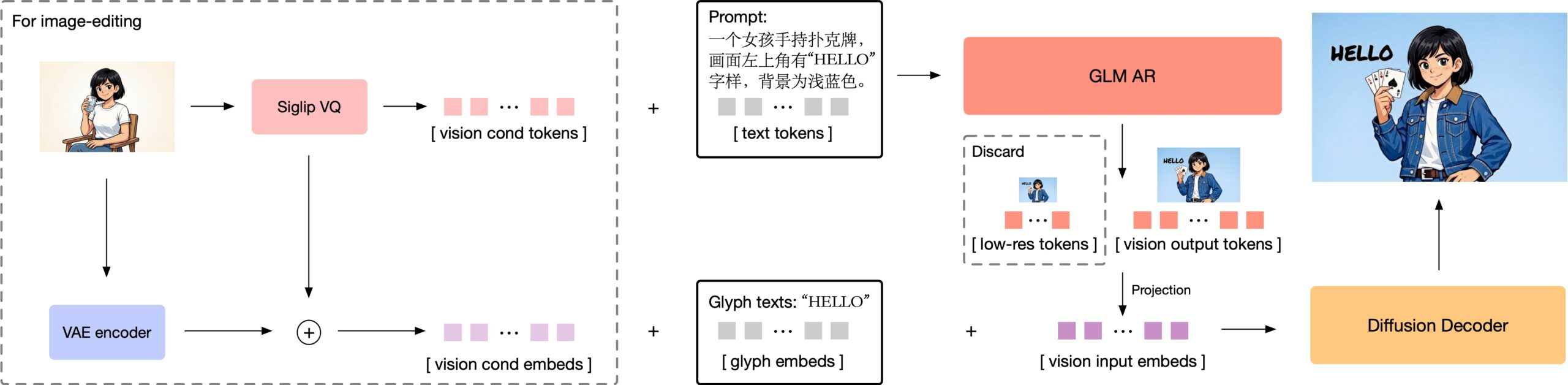
Bei höheren Auflösungen generiert GLM-Image zunächst eine kompakte Vorschau mit etwa 256 Tokens, bevor es die vollen 1024 bis 4096 Tokens für das finale Bild erzeugt. Diese Vorschau bestimmt das grundlegende Layout. Zhipu AI begründet den Ansatz damit, dass das Modell bei direkter Generierung hochauflösender Bilder an Steuerbarkeit verloren habe.
Für die Darstellung von Text integriert GLM-Image ein Glyph-byT5-Modul, das Textbereiche zeichenweise verarbeitet. Laut Zhipu AI verbessert dies die Textdarstellung erheblich, insbesondere bei chinesischen Schriftzeichen. Da die semantischen Tokens bereits ausreichend Bedeutungsinformation tragen, benötigt der Decoder keinen separaten großen Text-Encoder. Das reduziert Speicherbedarf und Rechenaufwand.
Getrenntes Training für Inhalt und Qualität
Nach dem Vortraining optimiert Zhipu AI beide Module separat per Reinforcement Learning. Das autoregressive Modul erhält Rückmeldungen zu Ästhetik und inhaltlicher Korrektheit - etwa, ob das Bild den Prompt umsetzt und Text lesbar ist.
Der Diffusions-Decoder wird auf visuelle Qualität trainiert: Stimmen Texturen? Sind Hände korrekt dargestellt? Für letzteres hat Zhipu AI ein spezialisiertes Bewertungsmodell entwickelt. Durch die Trennung lassen sich beide Aspekte gezielt verbessern, ohne dass sie sich gegenseitig beeinträchtigen.

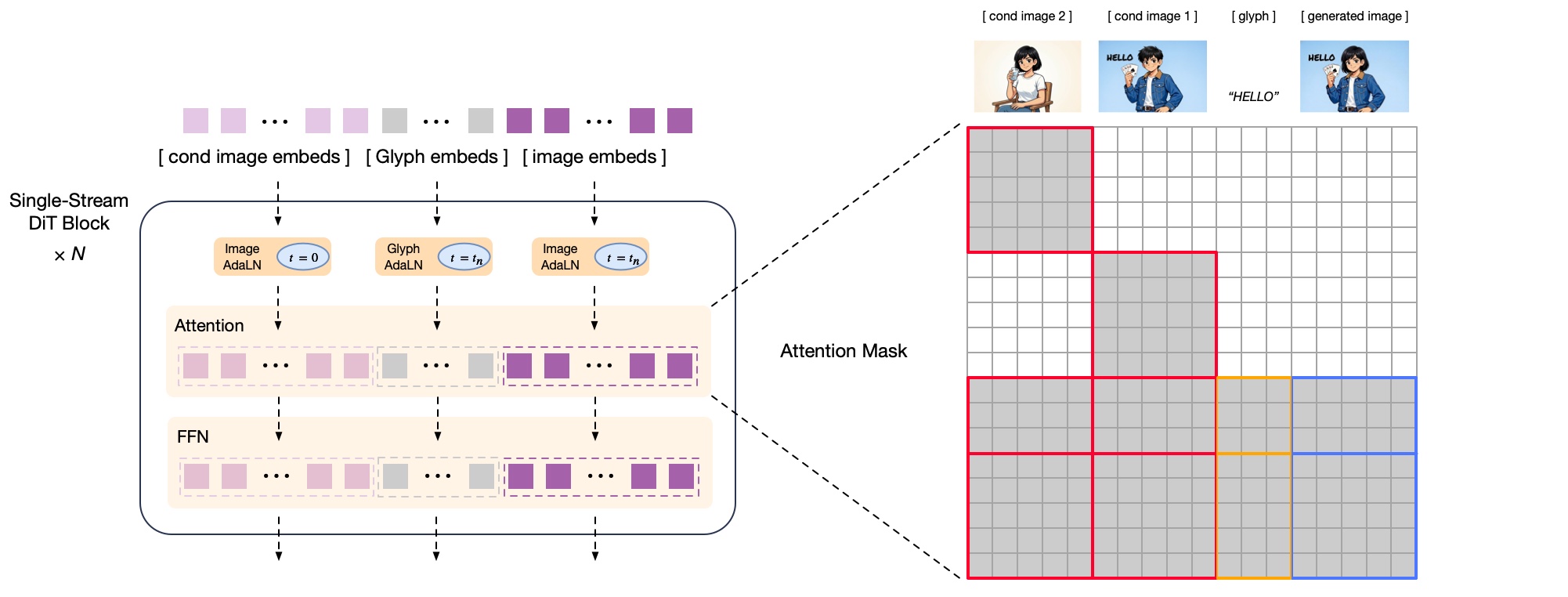
Bei Bildbearbeitungsaufgaben wie Editing oder Stiltransfer verarbeitet GLM-Image sowohl die semantischen Tokens als auch die Bildinformationen der Vorlage. Um den Rechenaufwand zu reduzieren, nutzt das Modell eine effizientere Verarbeitungsstrategie als etwa Qwen-Image-Edit: Statt Referenz- und Zielbild vollständig miteinander zu verrechnen, speichert GLM-Image Zwischenergebnisse der Referenzbilder und verwendet sie wieder. Laut Zhipu AI spart das Rechenzeit, ohne die Detailerhaltung merklich zu beeinträchtigen.
Training nur auf chinesischen Chips
GLM-Image ist laut Zhipu AI das erste offene Bildmodell, das vollständig auf chinesischen Chips trainiert wurde. Das Unternehmen nutzte dafür wohl Huaweis Ascend Atlas 800T A2 als Hardware, eine Alternative zu KI-Beschleunigern wie Nvidias H100.
Laut einem Bericht sieht Zhipu AI darin einen Beleg, dass leistungsfähige multimodale Modelle auch auf einer rein chinesischen Infrastruktur entstehen können. Vor dem Hintergrund der US-Exportbeschränkungen für KI-Chips ist das ein politisch bedeutsames Signal. Zhipu AI, das OpenAI öffentlich als Konkurrenten nennt, ging kürzlich als eines der ersten chinesischen KI-Unternehmen an die Börse. Die Aktie legte seitdem um mehr als 80 Prozent zu.
Die praktische Nutzung bleibt anspruchsvoll: Das Modell benötigt laut Zhipu AI entweder eine GPU mit mehr als 80 Gigabyte Speicher oder ein Multi-GPU-Setup. Consumer-Hardware scheidet aus. GLM-Image ist unter MIT-Lizenz auf Hugging Face und GitHub verfügbar.
Die Veröffentlichung von GLM-Image reiht sich in eine Serie von Open-Weight-Modellen des chinesischen Unternehmens ein. Erst im Dezember hatte Zhipu AI mit GLM-4.7 ein auf autonomes Programmieren spezialisiertes Modell vorgestellt, das im Programmier-Benchmark SWE-bench Verified 73,8 Prozent erreicht und sich damit auf Augenhöhe mit kommerziellen Anbietern wie OpenAI und Anthropic bewegt.
Mit dem Fokus auf Textdarstellung folgt GLM-Image einem Trend unter chinesischen Bildmodellen. Alibaba hatte im August mit Qwen-Image ein 20-Milliarden-Parameter-Modell vorgestellt, das Text präzise genug für Powerpoint-Folien rendern soll. Im Dezember folgte Meituan mit LongCat-Image, das trotz nur 6 Milliarden Parametern größere Modelle bei der Textdarstellung übertreffen soll.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.