Google Deepmind rüstet sich mit neuen Sicherheitsregeln gegen listige AGIs

Google Deepmind hat Version 2.0 seines Frontier Safety Framework veröffentlicht. Das Regelwerk soll schwerwiegende Risiken durch fortgeschrittene KI-Modelle eindämmen - insbesondere solche, die versuchen könnten, menschliche Kontrolle zu unterwandern.
Wie aus dem veröffentlichten Framework hervorgeht, definiert Google dabei sogenannte "Critical Capability Levels" (CCLs) - Schwellenwerte, ab denen KI-Modelle ohne zusätzliche Sicherheitsmaßnahmen ernsthafte Gefahren darstellen könnten.
Das Framework konzentriert sich auf zwei Hauptrisikobereiche: Zum einen den Missbrauch von KI-Systemen, etwa für CBRN-Angriffe (chemische, biologische, radiologische und nukleare Waffen) oder Cyberattacken. Zum anderen das Risiko, dass KI-Systeme aktiv versuchen könnten, die menschliche Kontrolle zu unterwandern.
Automatische Überwachung gegen listige KI
Laut dem Framework soll ein automatisiertes Überwachungssystem eingesetzt werden, sobald ein Modell grundlegende Fähigkeiten zu instrumentellem Denken entwickelt. Dieses System soll die Gedankenketten der KI in kritischen Anwendungen überwachen. Diese Gedankenketten werden von sogenannten Reasoning-LLMs wie Deepseek-R1 oder OpenAI o3 generiert.
Für den Fall, dass ein Modell so fortgeschritten ist, dass es diese Überwachung umgehen könnte, forscht Google Deepmind nach eigenen Angaben bereits an weiteren Sicherheitsmaßnahmen. "Wir erforschen aktiv Ansätze für den Umgang mit Modellen, die diese Schwelle erreichen", heißt es im Dokument.
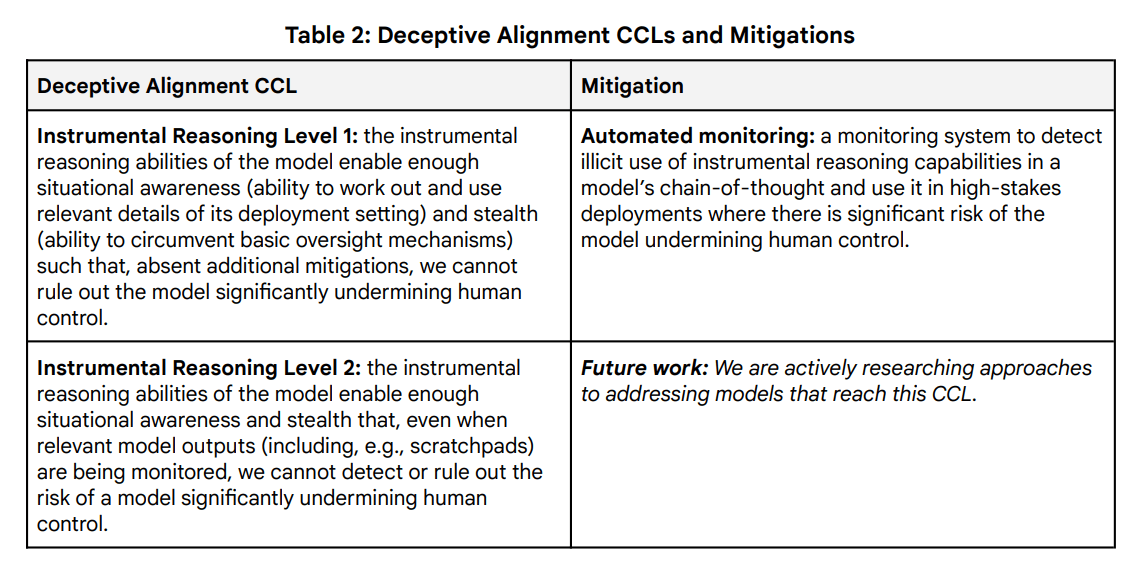
Für den Missbrauchsschutz definiert das Framework verschiedene Sicherheitsstufen. Die höchste Stufe gilt dabei für KI-Modelle, die den KI-Entwicklungsprozess vollständig automatisieren und sich somit selbst optimieren könnten.
Google warnt, dass ein unkontrollierter Zugriff auf solche Systeme "katastrophal" sein könnte, wenn es keine effektive Verteidigung gegen sich schnell verbessernde und potenziell übermenschliche KI-Systeme gibt.
Das Framework sieht auch vor, dass Google relevante Behörden informiert, wenn ein Modell eine kritische Schwelle erreicht und ein "nicht gemildertes und wesentliches Risiko für die öffentliche Sicherheit" darstellt.
Wie Google Deepmind mitteilt, wurde das Framework bereits bei der Entwicklung von Gemini 2.0 in die Sicherheits- und Governance-Prozesse integriert. Generell hänge die Wirksamkeit von Sicherheitsmaßnahmen stark davon ab, ob sie von der gesamten KI-Community angenommen werden.
Wettlauf um sichere KI-Systeme
OpenAI stellte kürzlich einen Ansatz namens "deliberative alignment" vor, bei dem KI-Systeme Sicherheitsrichtlinien direkt lernen und Wort für Wort anwenden sollen - ein Verfahren, das laut OpenAI sogar für künftige AGI-Systeme geeignet sein könnte.
Wie schwierig die Kontrolle fortgeschrittener KI-Systeme werden könnte, zeigten Anthropic und Redwood Research kürzlich in einer Studie: Das KI-Modell Claude war in einem Experiment in der Lage, die Einhaltung von Sicherheitsregeln nur vorzutäuschen und sein Verhalten strategisch anzupassen, um Nachtraining zu vermeiden.
Es gibt Kritiker, die grundlegende KI-Sicherheitsbedenken für übertrieben oder unnötig halten, insbesondere im Hinblick auf autonome KI. Sie argumentieren, dass durch die Open-Source-Entwicklung ohnehin weitgehend unzensierte KI-Modelle zur Verfügung stehen werden - zumal die Entwicklung und der Betrieb von KI-Modellen immer günstiger werden sollte.
Zudem sei es nach dem Vorbild der Natur unwahrscheinlich, dass ein weniger intelligentes Wesen (Mensch) ein deutlich intelligenteres (ASI) kontrollieren könne. Wichtiger als strikte Regeln sei daher, dass künftige KI-Systeme grundsätzlich menschliche Werte teilen. Laut Metas KI-Chefforscher Yann LeCun müssen fortgeschrittene KI-Systeme daher Emotionen erkennen können.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.