
Google DeepMind hat RoboVQA (Robot Visual Question Answering) entwickelt, einen neuen Ansatz zur Datenerhebung, mit dem schnell große Datenmengen aus Interaktionen in der realen Welt gesammelt werden können. Damit soll die Fähigkeit von Robotern verbessert werden, komplexere Aufgaben erfolgreich zu bewältigen.
RoboVQA verwendet einen "crowd-sourced botom-up"-Ansatz zur Datenerhebung. Konkret werden Daten, einschließlich egozentrischer Videos, für eine Vielzahl von Aufgaben von Menschen, Robotern und Teleoperatoren gesammelt.
RoboVQA lernt von Mensch, Maschine und Teleoperatoren
Der Prozess beginnt mit detaillierten Anweisungen für Haushaltsaufgaben wie "Mach mir einen Kaffee" oder "Räum das Büro auf". Anschließend führten Roboter, Menschen und Menschen mit Robotergreifarmen die Aufgaben in drei Bürogebäuden aus.
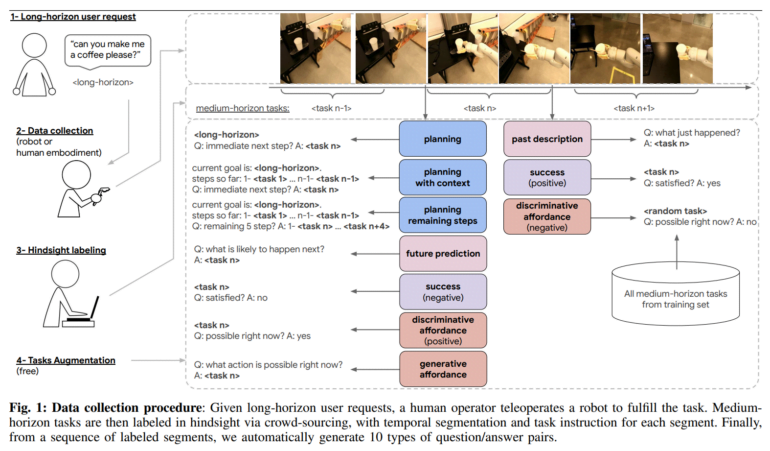
Bild: Google Deepmind
Im Nachhinein unterteilten die Crowdworker anhand der Videos die umfangreichen Aufgaben in kürzere Segmente mit natürlichsprachlichen Beschreibungen wie "Nimm die Kaffeebohnen" oder "Schalte die Kaffeemaschine ein". Auf diese Weise entstanden mehr als 829.502 Videos mit detaillierten Anleitungen. Im Vergleich zu anderen Methoden, die nicht auf Crowdsourcing setzen, ermöglicht diese Methode laut Deepmind eine deutlich schnellere Datenerhebung.
RoboVQA-VideoCoCa übertrifft andere Roboter-Modelle
Die Forscher zeigten auch, dass die gesammelten Daten tatsächlich einen Mehrwert bieten. Das Team trainierte das RoboVQA-VideoCoCa-Modell, das eine Vielzahl von Aufgaben in realistischen Umgebungen deutlich besser erledigte als andere Ansätze, die auf anderen Sprach-Bild-Modellen (VLM) basieren. Im Vergleich zu diesen benötigten die Roboter 46 Prozent weniger menschliches Eingreifen. Das sei ein deutlicher Fortschritt, zeige aber auch, dass für den praktischen Einsatz noch viele Daten gesammelt werden müssten, so das Team.
Video: Google Deepmind
In einem weiteren Test zeigte das Team zudem, dass sich die Fehler des Modells um knapp 20 Prozent reduzieren lassen, wenn man statt eines VLMs, das nur Einzelbilder analysiert, ein Video-VLM verwendet.
Unterdessen hat ein anderes Team von KI-Forschern mit RoboGen eine Methode vorgestellt, mit der Trainingsdaten für Roboter in Simulationen automatisch erzeugt werden können.
Alle Informationen und Daten sind auf GitHub verfügbar.





