Google neues Gemini 3.1 Flash TTS-Modell macht KI-Stimmen flexibler und dynamischer
Google rollt sein neues Text-to-Speech-Modell basierend auf Gemini 3.1 Flash aus. Es bietet laut Google die bisher natürlichste und ausdrucksstärkste Sprachausgabe des Unternehmens. Neu sind sogenannte Audio-Tags: Entwickler können per Textbefehle Stil, Tempo, Tonfall und Akzent der Sprachausgabe steuern. Das Modell unterstützt mehr als 70 Sprachen und ermöglicht Dialoge mit mehreren Sprechern.
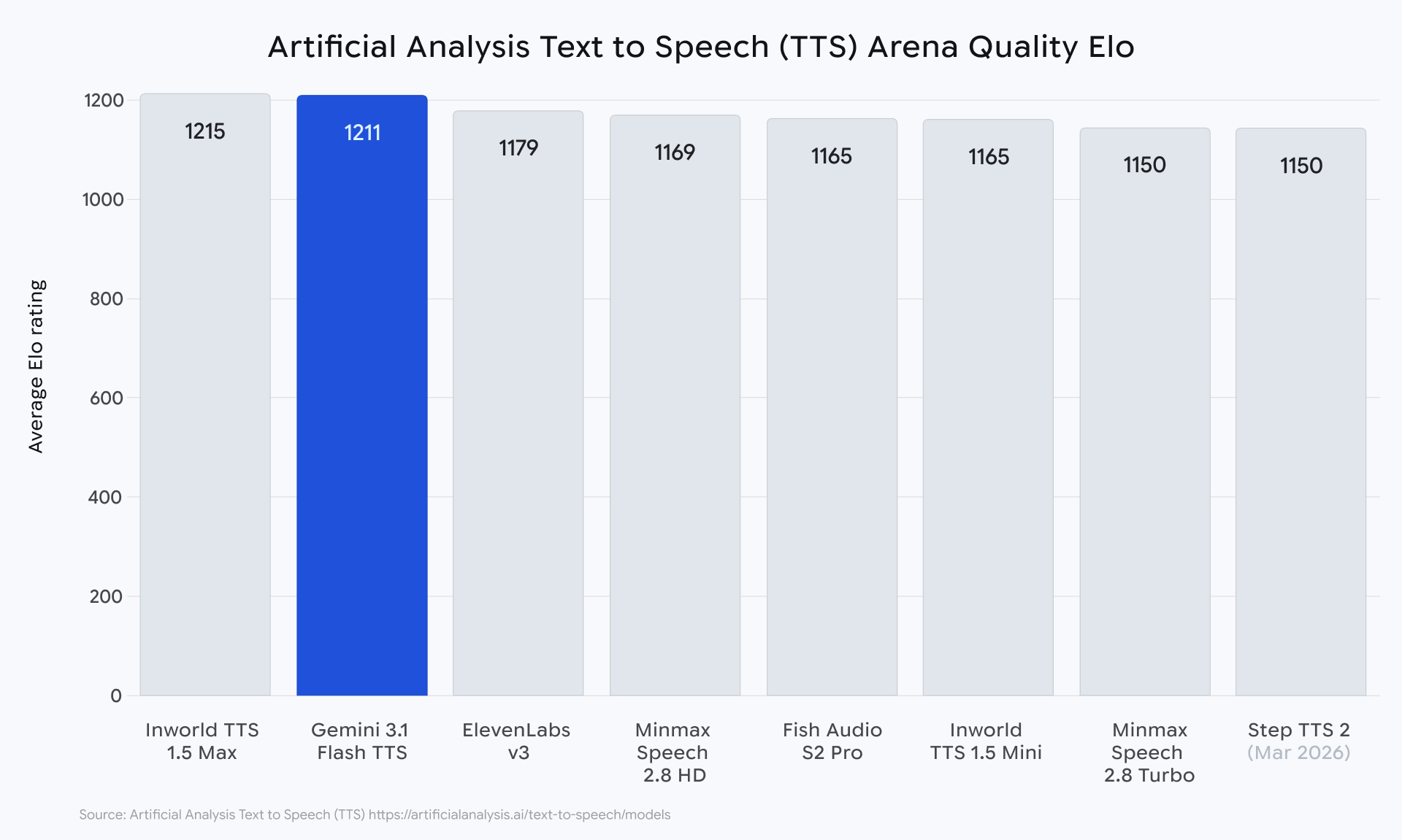
Auf der Rangliste von Artificial Analysis erreicht das Modell einen Elo-Wert von 1.211 und wird dort als besonders gutes Verhältnis von Qualität und Preis eingestuft. Bei der Qualität insgesamt liegt es vor Elevenlabs v3 und knapp hinter Inworld 1.5 Max.
Gemini 3.1 Flash TTS bietet eine kostenlose Stufe, bei der Google die Daten zur Produktverbesserung nutzen darf. In der kostenpflichtigen Stufe kostet die Texteingabe 1,00 Dollar pro Million Token, die Audioausgabe 20,00 Dollar pro Million Token. Im Batch-Modus halbieren sich die Preise auf 0,50 Dollar (Texteingabe) und 10,00 Dollar (Audioausgabe). Bei der bezahlten Stufe werden die Daten nicht zur Produktverbesserung verwendet.
Gemini 3.1 Flash TTS ist ab sofort als Vorschau über die Gemini-API, Vertex AI für Unternehmen und Google Vids für Workspace-Nutzer verfügbar. Kostenlos testen kann man es in Googles AI Studio. Alle erzeugten Audiodateien werden mit Googles SynthID-Wasserzeichen versehen, um KI-generierte Inhalte erkennbar zu machen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren