
Google Deepmind veröffentlicht in Zusammenarbeit mit führenden KI-Unternehmen und Universitäten einen Vorschlag für ein "Frühwarnsystem für neue KI-Risiken".
Wie ein Frühwarnsystem für neuartige KI-Risiken aussehen könnte, zeigen Forschende aus führenden KI-Unternehmen, Universitäten und anderen Forschungseinrichtungen in einem neuen Paper mit dem Titel "Model evaluation for extreme risks". Konkret schlägt das Team Methoden zur Bewertung großer KI-Modelle vor, um potenzielle Risiken frühzeitig zu erkennen.
Die Arbeit entstand in einer Kooperation von Forschenden von Google DeepMind, OpenAI, Anthropic, des Centre for the Governance of AI, des Centre for Long-Term Resilience, der University of Toronto, der University of Oxford, der University of Cambridge, der Université de Montréal, des Collective Intelligence Project, des Mila – Quebec AI Institute und des Alignment Research Center.
Weitere KI-Entwicklung könnte "extreme Risiken mit sich bringen"
Aktuelle Methoden der KI-Entwicklung erzeugen bereits jetzt KI-Systeme wie GPT-4, die sowohl nützliche als auch schädliche Fähigkeiten besitzen. Unternehmen wie OpenAI verwenden eine Vielzahl anderer Methoden, um die Modelle nach dem Training sicherer zu machen. Weitere Fortschritte in der KI-Entwicklung könnten jedoch zu extrem gefährlichen Fähigkeiten führen, argumentiert das Paper.
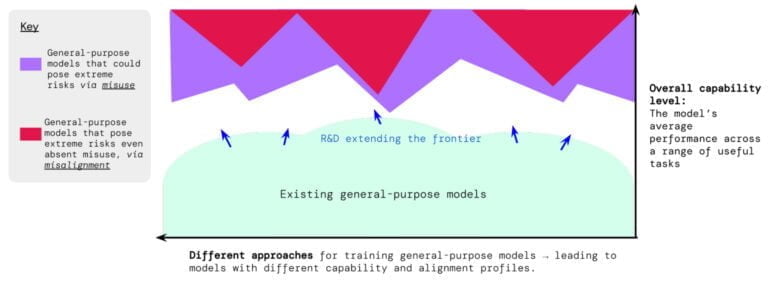
"Es ist plausibel (wenn auch ungewiss), dass künftige KI-Systeme in der Lage sein werden, offensive Cyber-Operationen durchzuführen, Menschen im Dialog geschickt zu täuschen, Menschen zu schädlichen Handlungen zu manipulieren, Waffen (z. B. biologische oder chemische) zu entwickeln oder zu erwerben, andere hochriskante KI-Systeme auf Cloud-Computing-Plattformen zu verfeinern und zu betreiben oder Menschen bei einer dieser Aufgaben zu unterstützen."
Entwickler:innen müssten daher in der Lage sein, gefährliche Fähigkeiten und die Neigung von Modellen, ihre Fähigkeiten zum Schaden zu nutzen, zu identifizieren. "Diese Evaluationen werden entscheidend sein, um politische Entscheidungsträger und andere Interessengruppen zu informieren und verantwortungsvolle Entscheidungen über das Training, den Einsatz und die Sicherheit von Modellen zu treffen", so das Team. Kurz gesagt: Sicherheitsbewertungen sind relevant, um gefährliche Modelle direkt zu regulieren oder im Notfall zu verbieten.
Evaluation von "gefährlichen Fähigkeiten" und "Alignment"
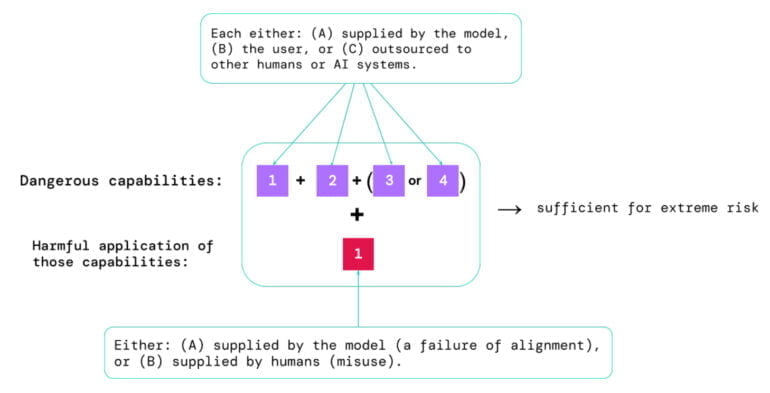
Eine Risikoeinschätzung müsse zwei Aspekte berücksichtigen:
- Das Ausmaß, in dem ein Modell über bestimmte "gefährliche Fähigkeiten" verfügt, die genutzt werden könnten, um die Sicherheit zu gefährden, Einfluss zu nehmen oder die Aufsicht zu umgehen.
- Das Ausmaß, in dem das Modell dazu neigt, seine Fähigkeiten zu nutzen, um Schaden anzurichten (also das Alignment des Modells). Die Bewertung des Alignment sollte bestätigen, dass sich das Modell in einem sehr breiten Spektrum von Szenarien wie beabsichtigt verhält, und, wenn möglich, die interne Funktionsweise des Modells untersuchen.
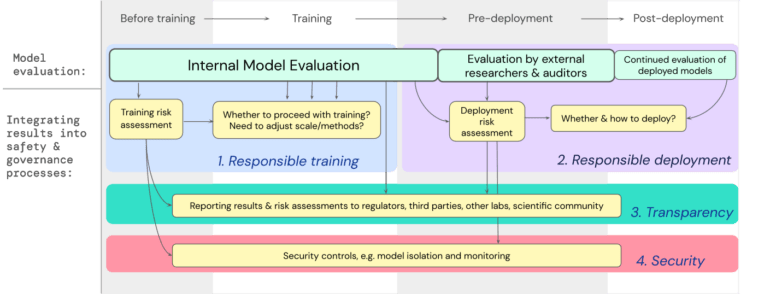
Diese Evaluierung sollte so früh wie möglich beginnen, um eine verantwortungsvolle Ausbildung und Nutzung sowie Transparenz und angemessene Sicherheitsmechanismen zu gewährleisten. Um dies zu erreichen, sollten die Entwickler:innen kontinuierliche Evaluierungen durchführen und externen Sicherheitsforscher:innen und Modellprüfer:innen strukturierten Zugang zum Modell gewähren, damit diese zusätzliche Evaluierungen durchführen können.
"Wir glauben, dass Prozesse zur Überwachung des Auftretens risikobehafteter Eigenschaften in Modellen und zur angemessenen Reaktion auf beunruhigende Ergebnisse ein wesentlicher Bestandteil eines verantwortungsbewussten Unternehmens sind, das an der Grenze der KI-Fähigkeiten arbeitet", heißt es in einem Blogbeitrag von Google Deepmind.

Vorschläge für Unternehmen und Politik
In der Forschungsarbeit wird explizit eine größere Verantwortung für große KI-Unternehmen genannt, da diese über die notwendigen Ressourcen verfügten und auch die Akteure seien, "bei denen die Wahrscheinlichkeit am größten ist, dass sie unbeabsichtigt KI-Systeme entwickeln oder freisetzen, die extreme Risiken bergen".
Unternehmen müssten daher:
- In die Forschung investieren: Große KI-Unternehmen sollten Ressourcen für die Forschung und Entwicklung von Modellen zur Bewertung extremer Risiken bereitstellen.
- Interne Richtlinien entwickeln: Große KI-Unternehmen sollten interne Richtlinien für die Durchführung, Berichterstattung und angemessene Reaktion auf die Ergebnisse von Extremrisikobewertungen entwickeln.
- Externe Forschung unterstützen: Große KI-Unternehmen sollten externe Forschung zu Extremrisikobewertungen durch Modellzugang und andere Formen der Unterstützung ermöglichen.
- Sensibilisierung der politischen Entscheidungsträger:innen: Große KI-Unternehmen sollten die politischen Entscheidungsträger sensibilisieren und sich an Diskussionen über die Festlegung von Standards beteiligen, um die Fähigkeit der Regierung zu verbessern, Vorschriften zu entwickeln, die zur Reduzierung von Extremrisiken erforderlich sein könnten.
Auch für Policy-Maker hat das Paper einige Vorschläge. Diese sollten eine Governance-Struktur für KI-Evaluierung und -Regulierung aufbauen. Weitere Schritte könnten sein:
- Eine systematische Überwachung der Entwicklung gefährlicher Fähigkeiten und der Fortschritte im Alignment innerhalb der KI-Forschung und -Entwicklung. Politische Entscheidungsträger:innen könnten ein formelles Meldeverfahren für extreme Risikobewertungen einführen.
- In das Ökosystem für externe Sicherheitsbewertungen zu investieren und Foren zu schaffen, in denen Interessengruppen (wie KI-Entwickler:innen, Wissenschaftler:innen und Regierungsvertreter:innen) zusammenkommen und diese Bewertungen diskutieren können.
- Externe Audits, einschließlich Modellaudits und Audits der Risikobewertungen von Entwicklern:innen, für hochleistungsfähige KI-Systeme für allgemeine Zwecke vorschreiben.
- Die Bewertung extremer Risiken in die Regulierung des Einsatzes von KI einbeziehen und klarstellen, dass Modelle, die extreme Risiken darstellen, nicht verwendet werden sollten.
"Die Modellevaluierung ist kein Allheilmittel"
Trotz aller Bemühungen können jedoch Risiken durch das Raster fallen, etwa weil sie zu stark von Faktoren außerhalb des Modells abhängen, wie komplexen sozialen, politischen oder wirtschaftlichen Kräften in der Gesellschaft, warnt das Team. Die Bewertung von Modellen müsse daher mit anderen Risikobewertungsinstrumenten und einem breiteren Engagement für Sicherheit in Industrie, Regierung und Zivilgesellschaft kombiniert werden.
Die Vorschläge decken sich in weiten Teilen mit bekannten Regulierungs- und Evaluationsforderungen der Industrie, wie sie beispielsweise der CEO von OpenAI, Sam Altman, in der Anhörung des US-Senats zur Regulierung von Künstlicher Intelligenz vorgetragen hat.



