Google optimiert Gemini-KI-Modelle und senkt Preise deutlich

Google hat zwei aktualisierte Gemini-KI-Modelle veröffentlicht, die leistungsfähiger, schneller und günstiger als ihre Vorgänger sein sollen.
Google hat zwei aktualisierte Gemini-KI-Modelle veröffentlicht: Gemini-1.5-Pro-002 und Gemini-1.5-Flash-002. Laut Google sind die neuen Versionen leistungsfähiger, schneller und günstiger als ihre Vorgänger.

Die Preise für Gemini 1.5 Pro wurden für Input- und Output-Token um mehr als 50 Prozent gesenkt, die Ratenlimits für beide Modelle erhöht und die Latenz verringert. Laut Google haben sich die Modelle in verschiedenen Benchmarks verbessert, insbesondere in den Bereichen Mathematik, langer Kontext und Vision.
Neue Gemini-Modelle schneiden in Mathe-Benchmarks besser ab
Bei MMLU-Pro, einer anspruchsvolleren Version des beliebten MMLU-Benchmarks, sei eine Steigerung von etwa 7 Prozent zu verzeichnen. Bei den Mathematik-Benchmarks MATH und HiddenMath hätten sich beide Modelle um beachtliche 20 Prozent verbessert.
Auch bei Vision- und Code-Anwendungsfällen schnitten beide Modelle besser ab, mit Steigerungen zwischen 2 und 7 Prozent bei Evaluierungen des visuellen Verständnisses und der Generierung von Python-Code.
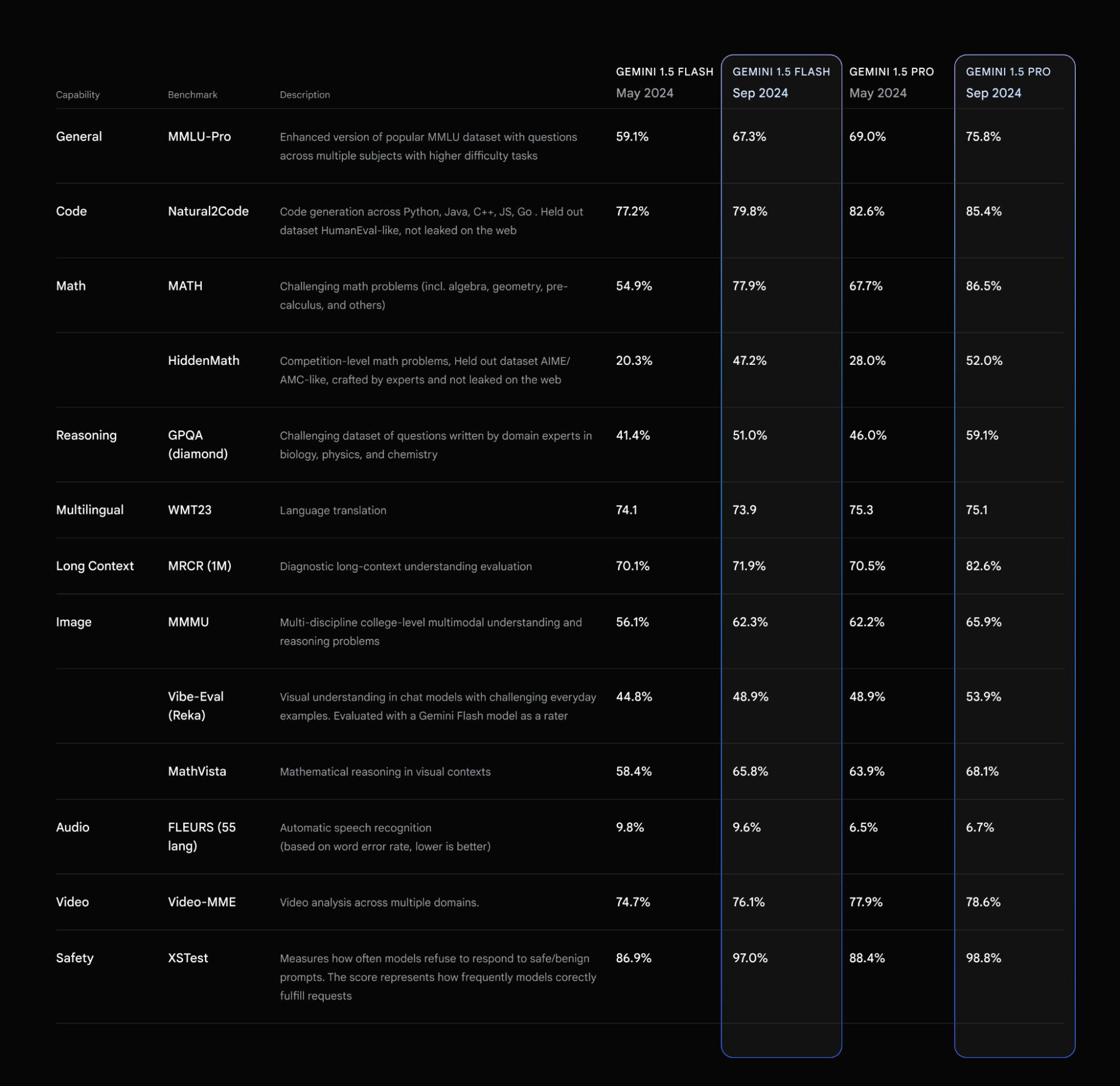
Die Antworten der Modelle seien insgesamt hilfreicher geworden, während sie weiterhin Googles Standards für die Sicherheit von Inhalten einhielten. Als Reaktion auf das Feedback der Entwickler hätten beide Modelle nun einen präziseren Stil, der sie einfacher und kostengünstiger in der Anwendung machen soll.
Google hat außerdem eine verbesserte Version des im August angekündigten experimentellen Modells Gemini 1.5 veröffentlicht. Diese Version "Gemini-1.5-Flash-8B-Exp-0924" soll signifikante Leistungssteigerungen sowohl bei Text- als auch bei multimodalen Anwendungsfällen bieten.
Die Gemini-Modelle sind über Google AI Studio, die Gemini API und für Google Cloud-Kunden auch auf Vertex AI verfügbar. Für Gemini Advanced-Nutzer stellt Google in Kürze eine für Chats optimierte Version von Gemini 1.5 Pro-002 in Aussicht.
Die neuen Preise gelten ab dem 1. Oktober 2024 für Prompts mit weniger als 128.000 Token. In Verbindung mit dem Context Caching sollen die Kosten für die Entwicklung mit Gemini weiter sinken.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.