Google stellt neues Gemini-2.5-Modell vor und erweitert Zugang
Google veröffentlicht die stabilen Versionen von Gemini 2.5 Flash und Pro. Außerdem startet das Unternehmen die Vorschau auf ein neues Modell mit besonders hoher Effizienz und Geschwindigkeit.
Google hat die KI-Modelle Gemini 2.5 Flash und Gemini 2.5 Pro offiziell als "generally available" eingestuft. Damit gelten sie als stabil und für den produktiven Einsatz geeignet. Zuvor liefen beide Modelle in einer Vorschauversion, erzielten aber bereits in Benchmarks starke Ergebnisse und schnitten auch in realen Anwendungsszenarien als einige der derzeit leistungsfähigsten Modelle ab.
Parallel zur Freigabe der bestehenden Modelle stellt Google mit Gemini 2.5 Flash-Lite ein neues Modell in der Vorschau bereit. Laut Google ist es das bislang schnellste und kosteneffizienteste Modell der 2.5-Reihe.
Die Vorschauversion von Flash-Lite ist ab sofort in Google AI Studio und Vertex AI verfügbar. Die stabilen Versionen von Flash und Pro sind ebenfalls über diese Plattformen sowie über die Gemini-App zugänglich. Darüber hinaus bietet Google angepasste Varianten von Flash und Flash-Lite auch in der Google-Suche an.
Flash-Lite: Schneller und günstiger als alle bisherigen Gemini-Modelle
Gemini 2.5 Flash-Lite übertrifft laut Google die Vorgängerversion 2.0 Flash-Lite in Benchmarks zu Programmierung, Mathematik, Naturwissenschaften, logischem Denken und multimodalen Aufgaben. In Tests wie GPQA (Science), AIME (Mathematik) oder LiveCodeBench (Codegenerierung) erzielt Flash-Lite deutlich höhere Werte als frühere Lite-Modelle und schließt in einigen Bereichen zu den größeren Modellen auf.
Beim Pricing unterscheidet Google dabei nicht zwischen der Version mit aktiviertem "Thinking"-Modus und der ohne. Beide Varianten kosten 0,10 US-Dollar pro Million Input-Tokens und 0,40 US-Dollar pro Million Output-Tokens. Reasoning-Modelle wie die "Thinking"-Varianten erzeugen allerdings viel mehr Token, um bessere Ergebnisse zu erzielen – was sie im praktischen Einsatz grundsätzlich teurer macht.
Gemini 2.5 Flash-Lite eignet sich laut Google besonders für Aufgaben mit hohem Anfragevolumen und geringen Latenzanforderungen, etwa Übersetzungen und Klassifikationen. Die Benchmarkwerte in Bereichen wie FACTS Grounding (86,8 %) und Multilingual MMLU (84,5 %) bestätigen diese Einschätzung. Auch bei visuellen Aufgaben wie MMMU (72,9 %) oder Bildverständnis (57,5 %) liegt Flash-Lite auf einem soliden Niveau.
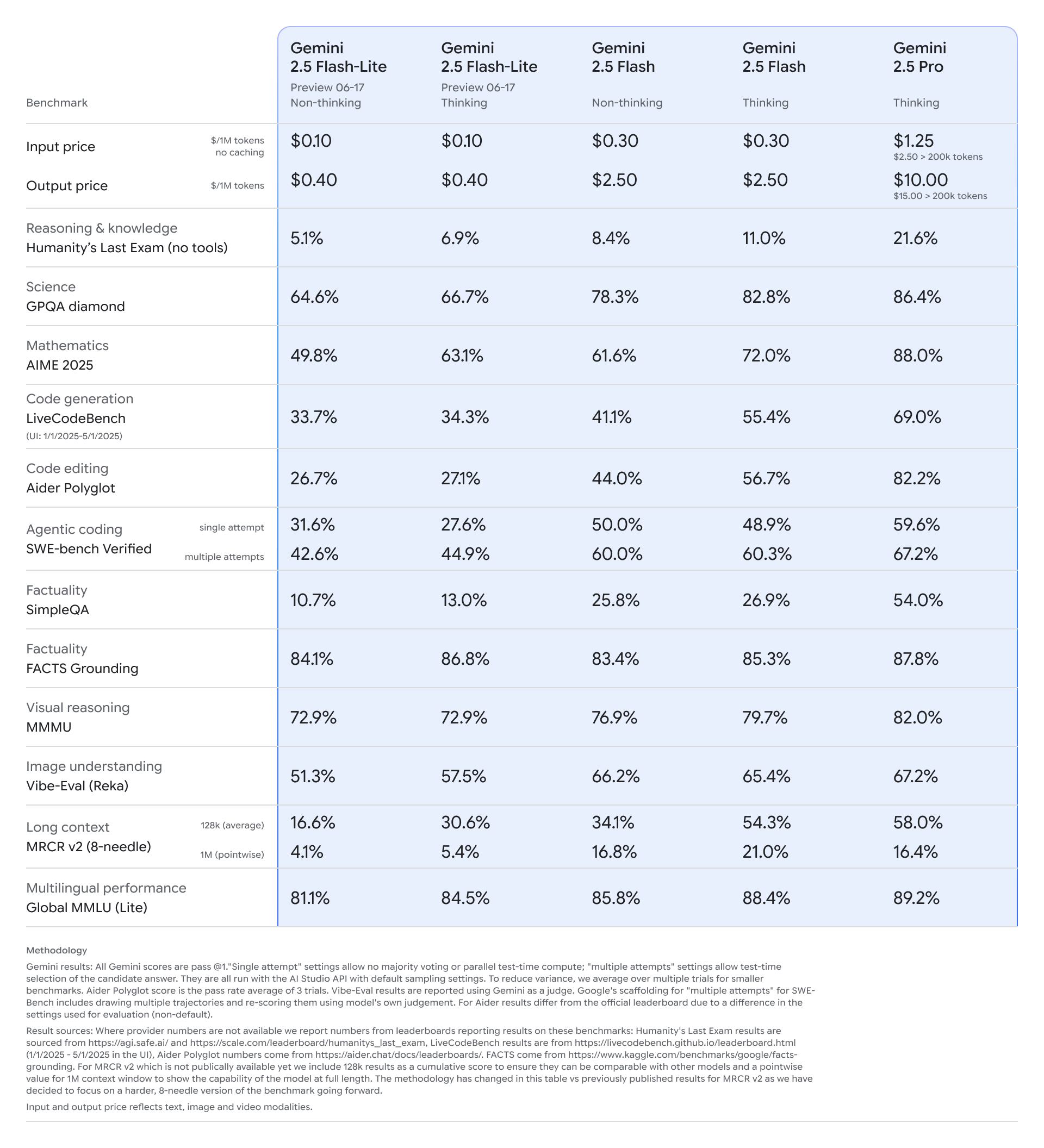
Flash-Lite bietet ansonsten dieselben Funktionen wie die übrigen 2.5-Modelle: Es unterstützt multimodale Eingaben, kann mit Tools wie der Google-Suche oder Codeausführungsumgebungen verbunden werden und verarbeitet Kontextfenster mit bis zu einer Million Tokens.
Die Gemini-2.5-Reihe wurde generell als Modellfamilie mit hybriden Schlussfolgerungsfähigkeiten konzipiert, die hohe Leistung bei gleichzeitig niedrigen Kosten und geringer Latenz versprechen. Die Modelle positionieren sich laut Google an der sogenannten Pareto-Front für Effizienz und Performance.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.