Googles Genie kann jedes Bild in eine spielbare 2D-Welt verwandeln
DeepMind-Forschende haben mit Genie ein Modell entwickelt, das aus Bildern Welten erschafft und darin selbstständig Videospielfiguren bewegt. Das klingt nach einer Spielerei, könnte aber der Grundstein für etwas viel Größeres sein.
"Was wäre, wenn wir mit einem großen Korpus von Videos aus dem Internet nicht nur Modelle trainieren könnten, die neue Bilder oder Videos generieren, sondern ganze interaktive Erlebnisse?" Diese Frage trieb die Forschenden von Google DeepMind bei der Entwicklung ihres neuen KI-Modells Genie (Generative Interactive Environments) an.
Video: Google DeepMind
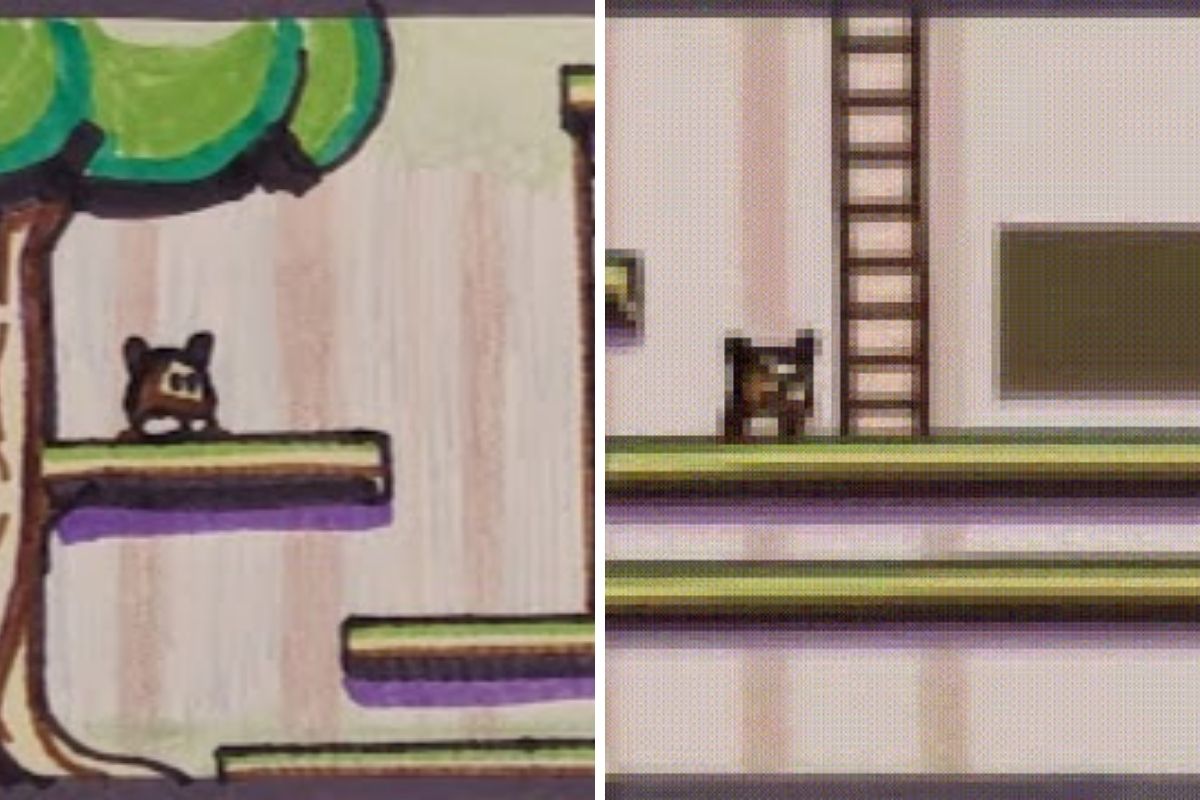
Verschiedene Arten von Bild-Prompts kann Genie in virtuelle Welten verwandeln und darin Spielfiguren logisch bewegen. Das ist auf den ersten Blick vor allem für Videospiele interessant. Die Wissenschaftler:innen glauben aber, dass ihr Ansatz bei Genie ein wichtiger Schritt hin zu grundlegenden Weltmodellen für Roboter-Anwendungen sein könnte.
Foundation Model für 2D-Platformer
Genie ist in seiner größten Ausprägung ein KI-Modell mit elf Milliarden Parametern, das im Bereich der 2D-Platformer die Eigenschaften eines Foundation Models aufweist: Aus einem dem Modell zuvor völlig unbekannten Bildprompt und einer von einem Menschen vorgegebenen Aktion, die etwa dem Drücken eines Gamepad-Buttons entspricht, erzeugt Genie eine virtuelle Welt, in der die Aktion ausgeführt wird.

Dabei ist der eigentliche Akteur - also der schwertschwingende Held oder ein Ball in einer handgezeichneten Skizze - nicht festgelegt - das Modell hat durch Training gelernt, welche Elemente in einem Bild üblicherweise Aktionen ausführen und bewegt diese dann selbstständig. Eine weitere spannende Beobachtung: Genie berücksichtigt sogar den so genannten Parallaxeffekt, wenn sich Vorder- und Hintergrund in einem Spiel unterschiedlich schnell bewegen.

Unbeschriftete Gaming-Videos aus dem Internet als Trainingsmaterial
Die große Besonderheit des Modells ist, dass es ausschließlich aus Videos lernt - also während des Trainings keine weiteren Informationen wie Gamepad-Eingaben erfährt. Als Grundlage diente eine Sammlung von ursprünglich 200.000 Stunden frei zugänglicher Gaming-Videos aus dem Internet, die von den Forschenden auf 30.000 Stunden Material speziell für 2D-Plattformen gefiltert wurden.
Genie besteht aus drei Komponenten: einem Video-Tokenizer, der Tokens aus Frames generiert, einem Latent Action Model, das Aktionen zwischen Frames vorhersagt, und einem Dynamics Model, das den nächsten Frame des Videos vorhersagt. Für das Latent Action Model beschränkt das Team die Anzahl der vorhergesagten Aktionen auf eine kleine diskrete Menge von Codes, um die menschliche Spielbarkeit zu ermöglichen und die Kontrollierbarkeit weiter zu verbessern.

Genie nutzt für seine Komponenten sogenannte "Spatio-temporal (ST) Transformer", die etwa in der Bildgenerierung zum Einsatz kommen. Wie von Transformern gewöhnt, konnte das Team auch bei Genie eine konsistent bessere Leistung mit steigender Parameterzahl beobachten.

Genie weiß auch, wie sich Roboterarme bewegen
Das Team trainierte ein kleineres Modell mit 2,5 Milliarden Parametern mit Videos von Roboterarmen. Hier hat Genie eindrucksvoll bewiesen, dass es in der Lage ist, sich eine kohärente Umgebung vorzustellen und Eingaben wie bestimmte Bewegungsabläufe zu reproduzieren. Genie simuliert sogar die Verformung von Objekten.
Video: Tim Rocktäschel/X
Das Team ist der Ansicht, dass das Experiment zeigt, dass die Methode, die Genie zugrunde liegt, dazu verwendet werden kann, ein Foundation-Modell für die Robotik mit größeren Videodatensätzen zu trainieren. Auf diese Weise könnten Simulationen erzeugt werden, die sich auf niedriger Ebene steuern lassen und die für eine Vielzahl von Anwendungen genutzt werden könnten, etwa für das Training von Roboteragenten.
Forscher lassen Vorsicht walten
Genie legt so einen wichtigen Grundstein für die weitere Forschung. Dank seines generellen Ansatzes könnte das Modell auch auf einer noch größeren Menge an Internetvideos trainiert werden, um realistischere und kohärentere Umgebungen zu simulieren. Die Achillesferse des Modells ist derzeit ein sehr begrenzter Speicher von 16 Frames und eine Geschwindigkeit der neuen Generationen von nur einem Frame pro Sekunde.
Genie könnte es vielen Menschen ermöglichen, ihre eigenen spielähnlichen Erfahrungen zu generieren. Dies könnte sich positiv auf diejenigen auswirken, die ihre Kreativität auf neue Art und Weise ausdrücken wollen, z. B. Kinder, die ihre eigenen Fantasiewelten erschaffen und betreten können. Wir sind uns auch darüber im Klaren, dass es, wenn es zu bedeutenden Fortschritten kommen soll, von entscheidender Bedeutung sein wird, die Möglichkeiten zu erforschen, wie diese Technologie genutzt werden kann, um die bestehende menschliche Spielproduktion und Kreativität zu stärken, und die entsprechenden Industrien in die Lage zu versetzen, Genie zu nutzen, um der nächsten Generation die Entwicklung spielbarer Welten zu ermöglichen.
Aus dem Paper
Ähnlich wie OpenAIs Sora hat sich Google DeepMind entschieden, keinen Modellcode oder Gewichtungen zu veröffentlichen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.