Googles Open-Source-Modell MedGemma analysiert Röntgenbilder und Hautfotos

Google Research und Deepmind haben mit MedGemma eine neue Kollektion medizinisch spezialisierter KI-Modelle veröffentlicht. Die Open-Source-Modelle sollen die Entwicklung von KI-Anwendungen im Gesundheitswesen beschleunigen.
Die auf Gemma 3 basierende MedGemma-Kollektion umfasst verschiedene Varianten: ein 4B-Modell, das Text, Bilder oder beides verarbeiten kann, sowie ein 27B-Modell in Text- und multimodaler Ausführung. Google hatte die Veröffentlichung auf der diesjährigen I/O angekündigt.
Die Modelle decken verschiedene medizinische Bereiche ab, darunter Radiologie, Dermatologie, Histopathologie (Gewebeuntersuchung) und Ophthalmologie (Augenheilkunde). Laut den Entwickler:innen sollen sie als Grundlage für die Entwicklung von KI-Anwendungen im Gesundheitswesen dienen und sowohl eigenständig als auch in agentischen Frameworks eingesetzt werden können.
Erhebliche Leistungssteigerungen gegenüber Standardmodellen
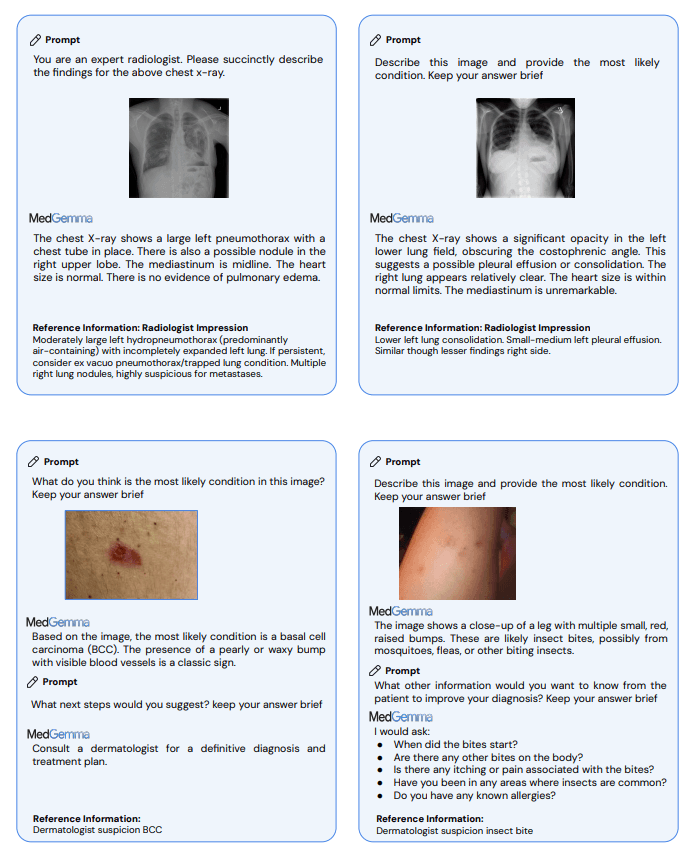
Laut dem technischen Bericht übertreffen die medizinisch spezialisierten Modelle vergleichbar große Foundation-Modelle erheblich. Bei speziellen medizinischen Aufgaben erreichen sie Verbesserungen von 2,6 bis 10 Prozent bei multimodalen Frage-Antwort-Systemen, 15,5 bis 18,1 Prozent bei der Klassifikation von Röntgenbefunden und 10,8 Prozent bei komplexeren agentischen Evaluierungen.
In standardisierten Tests zeigt sich dieser Fortschritt konkret: Bei MedQA, einem Test mit medizinischen Prüfungsfragen, erreicht das 4B-Modell 64,4 Prozent Genauigkeit gegenüber 50,7 Prozent des Basismodells. Das größere 27B-Modell erreicht sogar 87,7 Prozent gegenüber 74,9 Prozent.
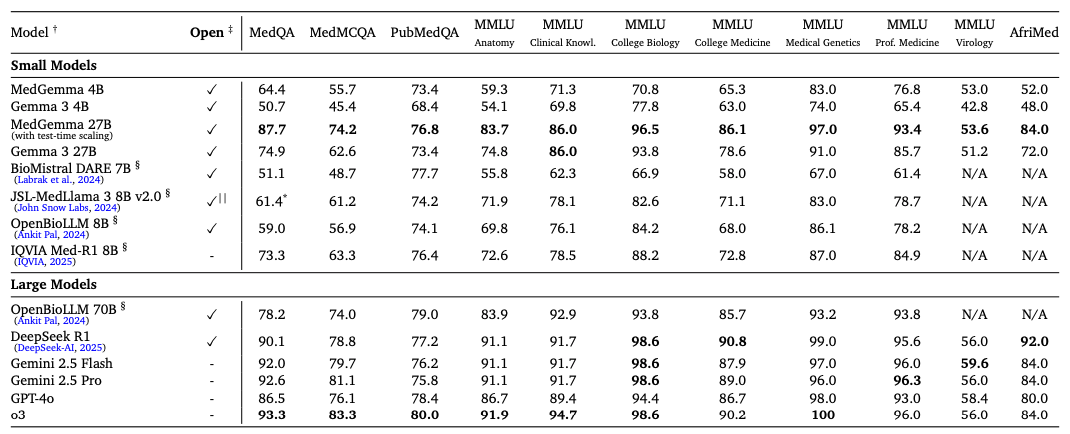
Bei der medizinischen Bildanalyse übertrifft MedGemma die Gemma 3-Baselines und zeigt auch überlegene Leistung im Vergleich zu deutlich größeren kommerziellen Modellen. Bei Tests mit dem MIMIC-CXR-Datensatz, einer Sammlung von Röntgenbildern mit zugehörigen Berichten, erreicht das Modell einen Makro-F1-Wert von 88,9 im Vergleich zu 81,2 beim 4B-Modell von Gemma 3. Der F1-Wert misst dabei die Genauigkeit bei der Erkennung verschiedener Krankheitsbilder.
MedSigLIP als spezialisierter Bildencoder
Für die Bildverarbeitung stellen die Forschenden zusätzlich MedSigLIP vor, einen medizinisch angepassten Bildencoder mit 400 Millionen Parametern. Dieser basiert auf SigLIP, einem von Google entwickelten System zur Verknüpfung von Bildern und Text. SigLIP steht für "Sigmoid Loss for Language Image Pre-training" und ist darauf spezialisiert, Bilder und deren Beschreibungen miteinander zu verknüpfen.
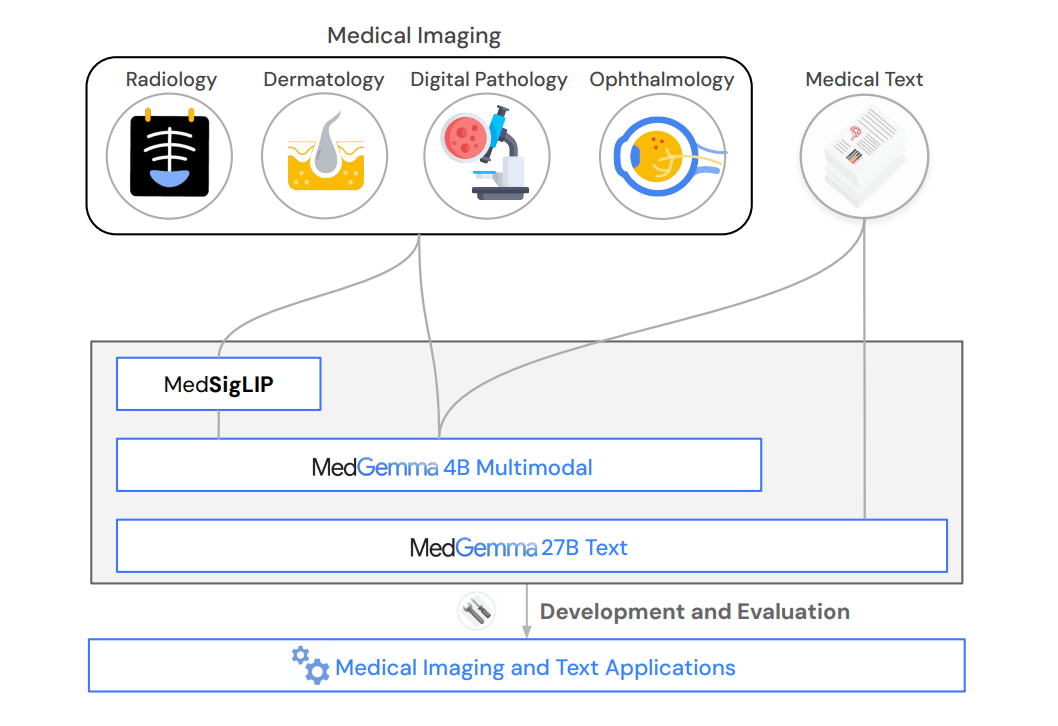
MedSigLIP erweitert diese Grundfunktion um medizinische Fähigkeiten und ermöglicht MedGemma die Interpretation medizinischer Bilder. Als eigenständiger Encoder erreicht er nach Angaben der Entwickler eine Leistung, die mit spezialisierten medizinischen Bildencodern vergleichbar oder besser ist. Dabei arbeitet MedSigLIP mit einer Auflösung von 448 x 448 Pixeln, was effizienter ist als die 896 x 896 Pixel der in MedGemma integrierten Version.
Das Training erfolgte mit über 33 Millionen medizinischen Bild-Text-Paaren, darunter 635.000 Beispiele aus verschiedenen medizinischen Modalitäten und 32,6 Millionen Histopathologie-Patches. Um die bestehende Leistung von SigLIP zu erhalten, wurden die ursprünglichen Trainingsdaten beibehalten und medizinische Daten mit einem Gewicht von zwei Prozent hinzugefügt. Das ermöglicht es dem Encoder, sowohl allgemeine als auch medizinische Bildinhalte zu verstehen.
Fine-Tuning zeigt Potenzial für spezialisierte Anwendungen
Die Forschenden demonstrieren das Anpassungspotenzial von MedGemma durch Fine-Tuning-Experimente für spezifische Aufgaben. Bei der automatischen Generierung von Röntgenberichten verbessert sich der RadGraph F1-Score von 29,5 auf 30,3. RadGraph ist eine Metrik, die misst, wie gut ein KI-generierter Bericht die medizinisch relevanten Informationen aus dem ursprünglichen Arztbericht erfasst.
Video: Google
Bei der Erkennung von Pneumothorax, einem Kollaps der Lunge, steigt die Erkennungsgenauigkeit (F1-Score) von 59,7 auf 71,5. Bei der Klassifikation von Gewebeproben in der Histopathologie verbessert sich die gewichtete F1-Bewertung drastisch von 32,8 auf 94,5.
Bemerkenswert ist die Verbesserung bei der Analyse elektronischer Patient:innenakten. Nach der Anpassung mit Reinforcement Learning reduziert sich die Fehlerrate bei der Informationsabfrage um 50 Prozent. Dies könnte die Effizienz bei der Auswertung von Patient:innendaten erheblich steigern.
Die MedGemma-Kollektion ist über Hugging Face verfügbar. Das Modell darf laut Lizenz zu Forschungs-, Entwicklungs- und allgemeinen KI-Zwecken genutzt werden – jedoch nicht direkt für medizinische Diagnostik oder Behandlung ohne regulatorische Freigabe. Kommerzielle Nutzung ist grundsätzlich möglich, sofern sie nicht gegen die Nutzungsbeschränkungen verstößt.
Benchmark-Ergebnisse können nicht 1:1 in die Praxis übertragen werden
Google hatte bereits im letzten Jahr ein spezielles Medizinmodell vorgestellt, das jedoch auf der geschlossenen Gemini-Familie basierte. Die Open-Source-Grundlage von MedGemma mit seiner Möglichkeit zur Spezialisierung könnte eine weitere Verbreitung begünstigen.
Auch wenn ein Modell wie MedGemma in Benchmarks überzeugen kann, heißt das nicht, dass sich diese Fähigkeiten eins zu eins in die Praxis übertragen lassen. Eine Studie zeigte etwa, dass die Wirksamkeit im realen Einsatz möglicherweise durch Missverständnisse oder fehlerhafte Interaktionen mit Nutzer:innen eingeschränkt werden könnte.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.