Googles ReCapture kann in Videos nachträglich zoomen, neigen und schwenken

Ein Forschungsteam von Google hat eine neue Methode namens ReCapture vorgestellt, mit der die Kameraführung in Videos nachträglich angepasst werden kann. Ziel ist es, auch Laien eine professionelle Nachbearbeitung ihrer Videos zu ermöglichen.
Die nachträgliche Änderung der Kameraperspektive in bestehenden Videos ist eine schwierige Aufgabe. Bestehende Verfahren haben oft Probleme, verschiedene Videotypen zu verarbeiten und gleichzeitig komplexe Bewegungen und Details beizubehalten.
Anstatt den Zwischenschritt über eine explizite 4D-Darstellung zu gehen, nutzt ReCapture das Vorwissen über Bewegungsabläufe, das in generativen Videomodellen enthalten ist. Die Aufgabe wird als Video-zu-Video-Übersetzung mit Hilfe von Stable Video Diffusion umformuliert.
Video: Zhang et al.
Zweistufiges Verfahren mit Zeit- und Ort-Schichten
ReCapture arbeitet in zwei Schritten: Zunächst wird ein sogenanntes Ankervideo erstellt - eine erste Annäherung an das gewünschte Ergebnis mit der neuen Kameraführung. Dieses Video kann noch zeitliche Unstimmigkeiten und Bildfehler enthalten.
Für die Erstellung des Ankervideos können beispielsweise Diffusionsmodelle wie CAT3D zum Einsatz kommen, die ein Video aus mehreren Blickwinkeln erzeugen. Alternativ lässt sich das Ankervideo auch über eine Frame-für-Frame-Tiefenschätzung und Punktwolken-Rendering generieren.
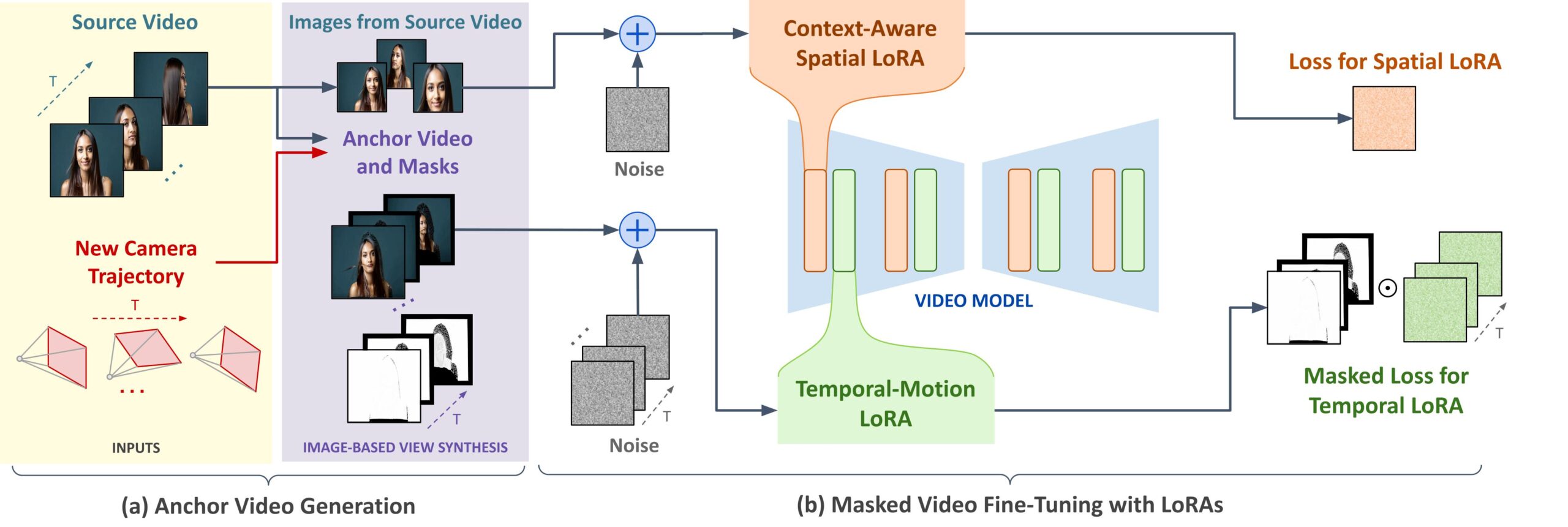
Im zweiten Schritt kommt die Technik des maskierten Video-Feintunings zum Einsatz. Dabei wird ein generatives Videomodell verwendet, das aus vorhandenen Videos gelernt hat, realistische Bewegungen und zeitliche Veränderungen zu erzeugen.
Um das Modell optimal an das Eingangsvideo anzupassen, wird eine zeitliche LoRA-Schicht (Low-Rank Adaptation) verwendet. Diese Schicht ist speziell dafür verantwortlich, zeitliche Veränderungen im Video zu erkennen und zu lernen.
Sie ermöglicht es dem Modell, die spezifische Dynamik und Bewegungsabläufe des Ankervideos zu verstehen und nachzuahmen, ohne dass das gesamte Modell neu trainiert werden muss.
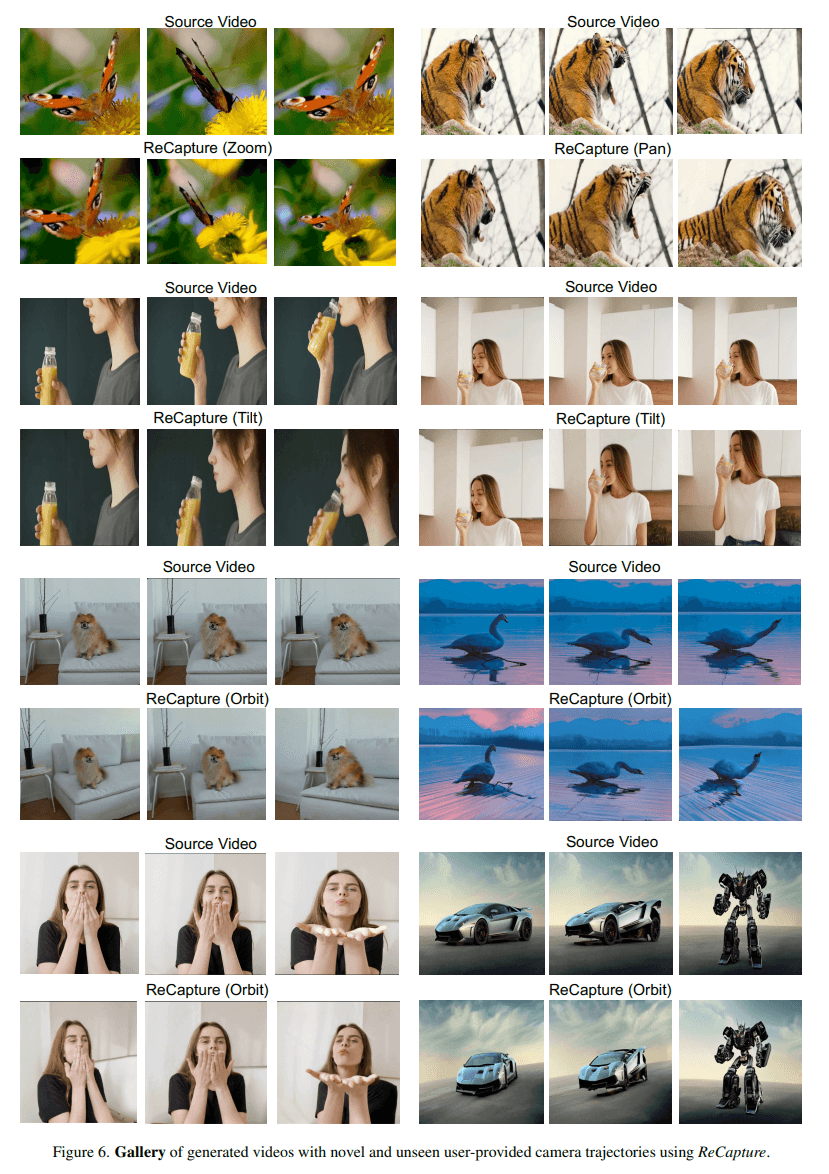
So kann das generative Videomodell mit der virtuellen Kamera zoomen, schwenken und kippen, während die charakteristischen Bewegungen des Originalvideos erhalten bleiben.
Zusätzlich kommt eine räumliche LoRA-Schicht zum Einsatz, die dafür sorgt, dass die Bildinhalte und Details erhalten bleiben und mit der neuen Kameraführung konsistent sind.
Weitere Details zur Funktionsweise von ReCapture finden sich auf der Projekt-Website und im Forschungspapier. Dort werden auch Nachbearbeitungstechniken wie SDEdit zur Verbesserung der Bildqualität und Reduzierung von Unschärfe beschrieben.
Tatsächlicher Nutzen noch weit entfernt
Die Forscher:innen sehen in ihrer Arbeit einen wichtigen Schritt in Richtung einer benutzerfreundlichen Videomanipulation. Bis jetzt handelt es sich bei ReCapture aber noch um ein Forschungsprojekt und längst kein kommerzielles Produkt. Google hat bisher keines seiner zahlreichen Video-KI-Projekte kommerzialisiert, steht mit Veo aber wohl kurz davor.
Bis dahin beherrschen vorwiegend Start-ups wie Runway den Markt der Video-KI, dessen jüngstes Modell Gen-3 Alpha im Sommer eingeführt wurde. Auch Meta hat mit Movie-Gen kürzlich ein vielversprechendes Modell vorgestellt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.