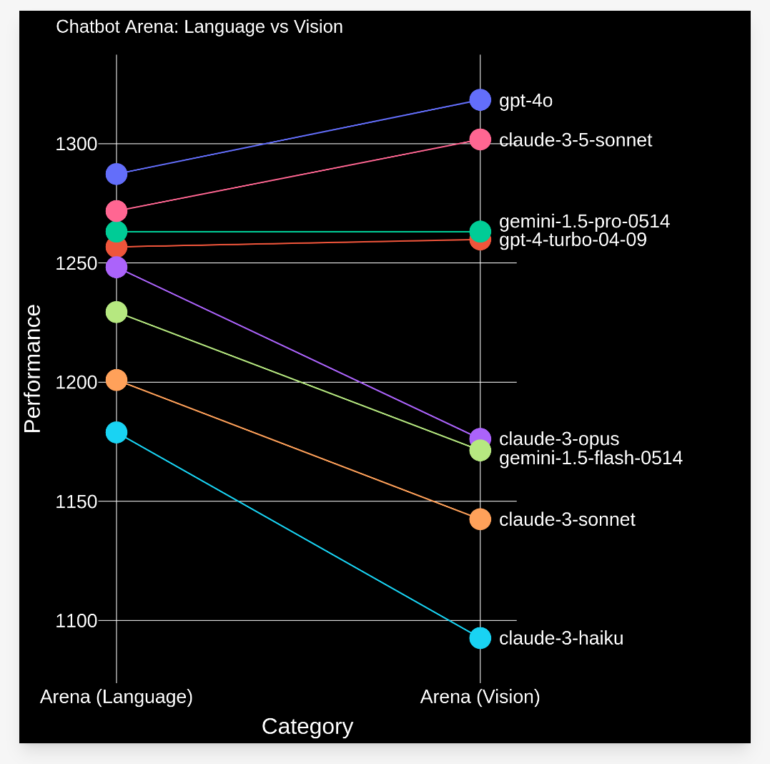
LMSYS Org hat die Chatbot Arena um Bilderkennung erweitert, um Vision-Language-Modelle (VLMs) von OpenAI, Anthropic, Google und anderen KI-Anbietern zu vergleichen. In zwei Wochen wurden über 17.000 Nutzerpräferenzen in mehr als 60 Sprachen gesammelt. GPT-4o und Claude 3.5 Sonnet schneiden bei Bilderkennung deutlich besser ab als Gemini 1.5 Pro und GPT-4 Turbo. Während Claude 3 Opus bei Sprachmodellen besser ist als Gemini 1.5 Flash, sind beide bei VLMs ähnlich gut. Das Open-Source-Modell Llava-v1.6-34b übertrifft knapp Claude-3-Haiku. Die gesammelten Daten zeigen häufige Anwendungen wie Bildbeschreibung, Matheaufgaben, Dokumentenverständnis, Meme-Erklärung und Geschichtenschreiben. Als nächstes plant das Team die Unterstützung mehrerer Bilder sowie von PDFs, Videos und Audio. Large Model Systems Organization (LMSYS Org) ist eine offene Forschungsorganisation, die von Studenten und Dozenten der UC Berkeley in Zusammenarbeit mit der UCSD und der CMU gegründet wurde.

![Black Forest Labs bringt KI-Bildmodell FLUX.1 Kontext [dev] für private Nutzung heraus](https://the-decoder.de/wp-content/uploads/2025/07/blackforestlabs_examples-375x207.png)



