
I-JEPA zeigt, wie Metas KI-Chef Yann LeCun die Zukunft der KI sieht - und die beginnt wieder mit ImageNet-Benchmarks.
Vor knapp einem Jahr stellte der KI-Pionier und Meta AI-Chef Yann LeCun eine neue KI-Architektur vor, die die Grenzen heutiger Systeme wie Halluzinationen und logische Schwächen überwinden soll.
Mit I-JEPA präsentiert nun ein Team aus Meta AI (FAIR), McGill University, Mila, Quebec AI Institute und New York University eines der ersten KI-Modelle, das dieser "Joint Embedding Predictive Architecture" folgt. Unter den Forschenden ist neben Erstautor Mahmoud Assran auch Yann LeCun.
Das auf Vision Transformer basierte Modell erreicht in Benchmarks von der linearen Klassifikation bis zur Objektzählung und Tiefenvorhersage eine hohe Leistung und ist recheneffizienter als andere weit verbreitete Computer-Vision-Modelle.
I-JEPA lernt mit abstrakten Repräsentationen
I-JEPA wird selbstüberwacht auf die Vorhersage von Details der nicht sichtbaren Teile eines Bildes trainiert. Dazu werden einfach große Blöcke dieser Bilder maskiert, deren strukturellen Inhalt I-JEPA vorhersagen soll. Andere Verfahren setzen oft auf deutlich aufwändiger augemtierte Trainingsdaten.
Damit I-JEPA semantische, übergeordnete Repräsentationen von Objekten lernt und nicht auf Pixel- oder Token-Ebene operiert, setzt Meta eine Art Filter zwischen Vorhersage und Originalbild.
Neben einem Context-Encoder, der die sichtbaren Teile eines Bildes verarbeitet, und einem Predictor, der die Ausgabe des Context-Encoders verwendet, um die Darstellung eines Zielblocks im Bild vorherzusagen, besteht I-JEPA aus einem Target-Encoder. Dieser Target-Encoder wird zwischen das vollständige Bild, das als Trainingssignal dient, und den Predictor geschaltet.
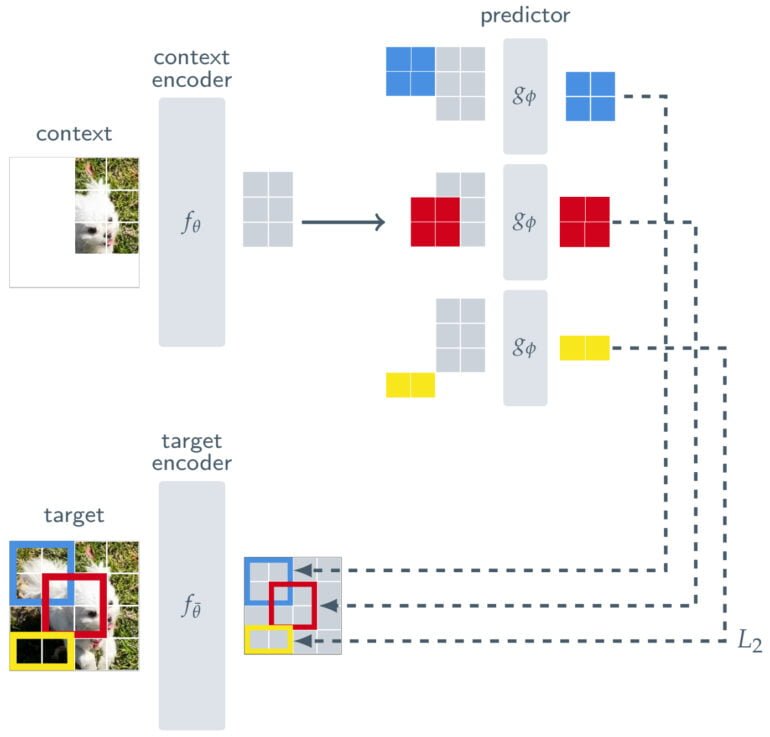
Die Vorhersage von I-JEPA erfolgt so nicht auf Pixelebene, sondern auf der Ebene abstrakter Repräsentationen, da das Bild durch den Target-Encoder verarbeitet wird. Dadurch können unnötige Details auf Pixelebene entfernt werden und das Modell lernt mehr semantische Merkmale, also die übergeordnete Repräsentation von Objektteilen, ohne deren lokalisierte Positionsinformation im Bild zu vernachlässigen.
I-JEPA glänzt in ImageNet
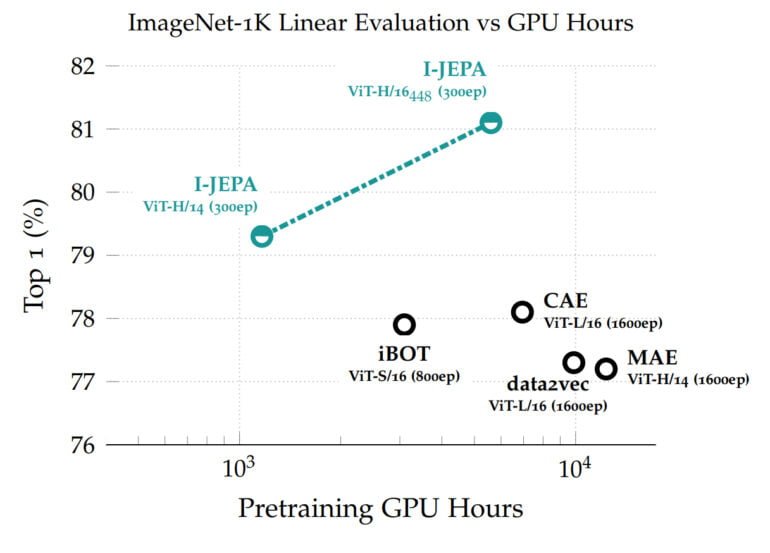
Die gelernten Repräsentationen können dann für verschiedene Aufgaben wiederverwendet werden, so erreicht I-JEPA in ImageNet Bestwerte mit nur 12 gelabelten Beispielen pro Klasse. Das Modell mit 632 Millionen Parametern wurde auf 16 Nvidia A100-GPUs in weniger als 72 Stunden trainiert. Andere Methoden benötigen in der Regel zwei- bis zehnmal so viele GPU-Stunden und erreichen schlechtere Fehlerraten, wenn sie mit der gleichen Datenmenge trainiert werden.

In einem Experiment visualisiert das Team mithilfe eines generativen KI-Modells die Repräsentationen von I-JEPA und zeigt, dass das Modell wie erwartet gelernt hat.

I-JEPA ist eine Machbarkeitsstudie für die vorgeschlagene Architektur, deren Kernelement eine Art Filter zwischen Vorhersage und Trainingsdaten ist, der wiederum abstrakte Repräsentationen ermöglicht. Laut LeCun könnten solche Abstraktionen KI-Modelle erlauben, die dem menschlichen Lernen ähnlicher sind, logische Schlussfolgerungen ziehen und das Halluzinationsproblem in der generativen KI lösen können.
JEPA soll Weltmodelle ermöglichen
Ziel der JEPA-Modelle ist also es nicht, Bilder zu erkennen oder Texte zu generieren - LeCun will umfassende Weltmodelle ermöglichen, die als Teil einer autonomen künstlichen Intelligenz funktionieren. Dazu schlägt er vor, JEPA hierarchisch zu stapeln, um Vorhersagen auf einer höheren Abstraktionsebene auf Basis von Vorhersagen niedrigerer Module zu ermöglichen.
"Es wäre besonders interessant, JEPA weiterzuentwickeln, um allgemeinere Weltmodelle aus reichhaltigeren Modalitäten zu lernen, etwa um räumliche und zeitliche Vorhersagen über zukünftige Ereignisse in einem Video aus einem kurzen Kontext zu machen und diese Vorhersagen mit Audio- oder Textanweisungen zu konditionieren", so Meta.
JEPA soll daher auf andere Bereiche angewandt werden wie Bild-Text-Paare oder Videodaten. "Dies ist ein wichtiger Schritt auf dem Weg zur Anwendung und Skalierung selbstüberwachender Methoden zum Lernen eines allgemeinen Modells der Welt", heißt es im Blog.
Einen Einblick in die Motivation, Entwicklung und Funktionsweise von JEPA gibt LeCun in einem Vortrag am Institute for Experiential AI der Northeaster University.
Weitere Informationen gibt es im Meta-Blog zu I-JEPA. Das Modell und Code gibt es auf GitHub.



