
Forscher der ETH Zürich und von Google Zürich haben eine neue Methode namens InseRF zum generativen Einfügen von Objekten in 3D-Szenen vorgestellt.
Die Methode verwendet einen Text-Prompt und eine 2D Bounding Box auf einem Referenzpunkt, um neue Objekte in einem NeRF zu generieren. Experimente zeigen, dass InseRF bestehende Methoden übertrifft und in der Lage ist, konsistente Objekte in NeRFs einzufügen, ohne dass explizite 3D-Informationen als Eingabe benötigt werden.
InseRF kombiniert Fortschritte auf dem Gebiet der NeRFs mit denen der generativen KI, die etwa die Umwandlung von Einzelbildern in 3D-Modelle oder die 3D-Bearbeitung ermöglichen.
InseRF setzt auf Diffusionsmodelle und NeRFs
Um neue 3D-Objekte in das NeRF zu integrieren, beginnt InseRF mit einem 2D-Bild der 3D-Szene, auf dem der Benutzer einen Bereich markieren kann, in dem eine Änderung vorgenommen werden soll. Die Änderung wird durch einen Textprompt beschrieben, etwa "eine Teetasse auf einem Tisch". InseRF erzeugt dann eine Teetasse in dieser 2D-Ansicht über ein Diffusionsmodell und schätzt die Tiefeninformation der so erzeugten Ansicht. Diese Daten werden dann verwendet, um das NeRF zu aktualisieren und die 3D-Tasse zu generieren.
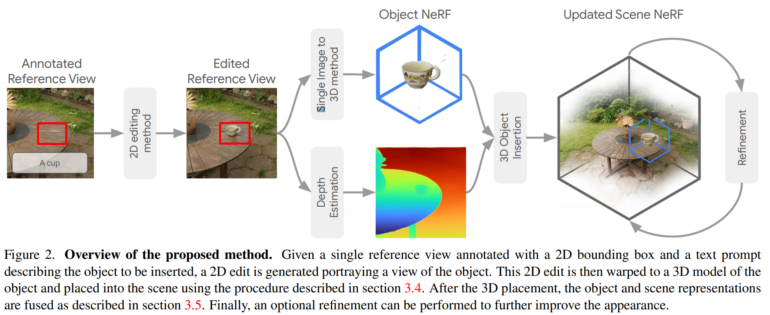
Dieser Prozess ermöglicht es, ein neues 3D-Objekt in einer Szene zu erzeugen, das über mehrere Ansichten hinweg konsistent ist und an jeder beliebigen Position platziert werden kann. Damit überwindet die Methode nach Angaben des Teams auch die Herausforderungen der 3D-konsistenten Erzeugung und Platzierung von Objekten in verschiedenen Ansichten, die bei generativen 2D-Modellen eine große Hürde darstellen.
InseRF hängt Alternativen deutlich ab
Die Forscher testen InseRF mit einigen realen Innen- und Außenszenen aus den Datensätzen von MipNeRF-360 und Instruct-NeRF2NeRF. Die Ergebnisse zeigen deutlich, dass InseRF in der Lage ist, die Szene lokal zu verändern und 3D-konsistente Objekte einzufügen.
Video: ETH Zürich / Google
Die Leistungsfähigkeit von InseRF wird jedoch durch die Fähigkeiten der zugrunde liegenden generativen 2D- und 3D-Modelle begrenzt. Zukünftige Verbesserungen dieser Modelle könnten jedoch leicht auf die InseRF-Pipeline übertragen werden. Das Team plant, in Zukunft weitere Methoden zu testen, etwa um die Schattenbildung zu verbessern und die Qualität des generierten Objekts und seiner Umgebung anzugleichen.
Weitere Beispiele und Informationen sind auf der InseRF-Projektseite zu finden.






