Jenseits der Wortvorhersage: So könnte die Zukunft von KI-Sprachmodellen aussehen

Forschende zeigen, dass die Vorhersage mehrerer Token beim Training von KI-Sprachmodellen die Leistung, Kohärenz und Schlussfolgerungsfähigkeit verbessert. Liegt die Zukunft großer Sprachmodelle jenseits der einfachen Tokenvorhersage?
Große Sprachmodelle wie GPT-4 werden in der Regel mit der „Next-Token-Prediction" trainiert. Dabei lernt das KI-System, immer nur das nächste Wort in einem Satz vorherzusagen. Wissenschaftler von Meta AI, CERMICS (Ecole des Ponts ParisTech) und LISN (Université Paris-Saclay) schlagen nun vor, die Modelle stattdessen mehrere Wörter auf einmal vorhersagen zu lassen. Sie nennen diese Methode „Multi-Token-Prediction".
Konkret sagt das Modell an jeder Stelle des Trainingstextes die nächsten Wörter parallel voraus, indem es einen gemeinsamen Modellteil (Trunk) und mehrere unabhängige Ausgabeköpfe (Output Heads) verwendet. Im Vergleich zum herkömmlichen Verfahren kann so die Trainingseffizienz gesteigert werden.
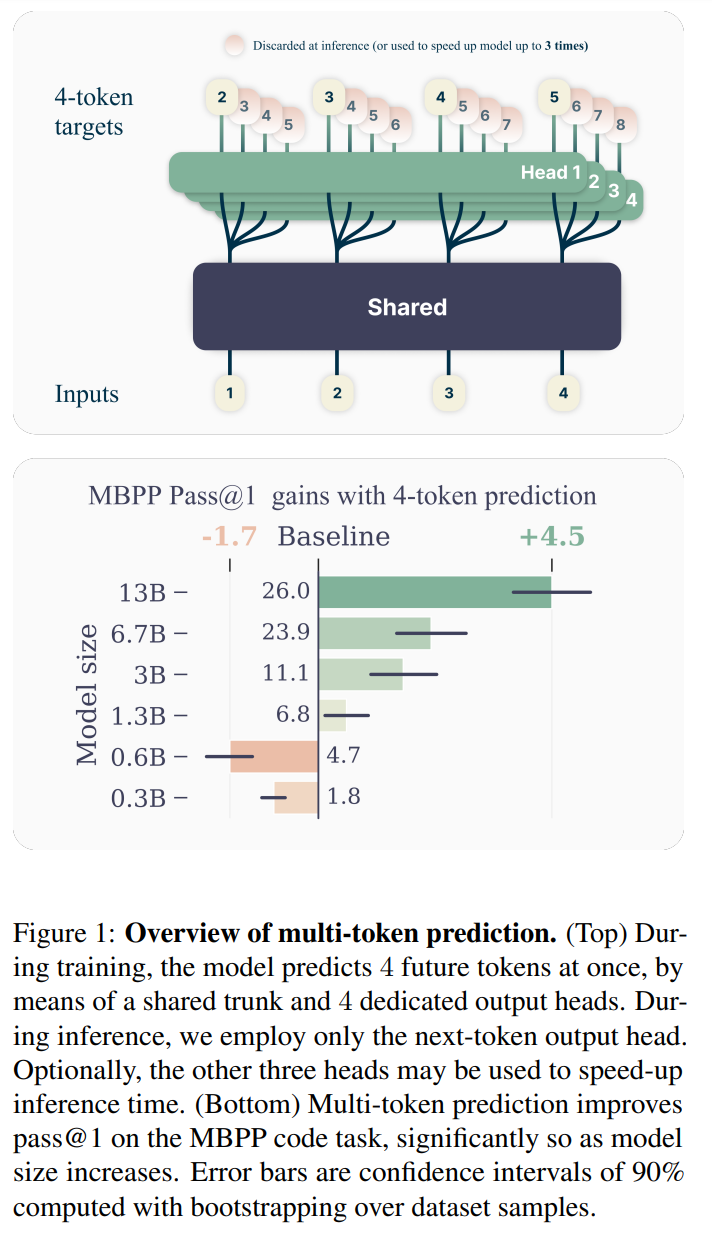
Um den Speicherbedarf gering zu halten, werden die Berechnungen der Ausgabeköpfe nacheinander ausgeführt und die Zwischenergebnisse nach jedem Schritt gelöscht. Auf diese Weise steigt der Speicherbedarf nicht mit der Anzahl der vorhergesagten Wörter.
Die Experimente zeigen, dass der Vorteil der Multi-Token-Prediction mit der Größe des Modells zunimmt. Ein Modell mit 13 Milliarden Parametern löste auf dem HumanEval-Datensatz 12% und auf dem MBPP-Datensatz 17% mehr Programmieraufgaben als ein vergleichbares Next-Token-Modell.
Auch bei der Ausführungsgeschwindigkeit punktet der neue Ansatz: Mit spekulativer Decodierung, die die zusätzlichen Vorhersageköpfe nutzt, können die Modelle bis zu dreimal schneller ausgeführt werden.
Warum funktioniert die Multi-Token-Prediction so gut? Die Forscher vermuten, dass sich Next-Token-Modelle zu sehr auf die unmittelbare Vorhersage konzentrieren, während Multi-Token-Modelle auch längerfristige Abhängigkeiten berücksichtigen. Sie hoffen daher, dass ihre Arbeit das Interesse an neuartigen Hilfsaufgaben beim Training von Sprachmodellen über die reine Next-Token-Prediction hinaus wecken wird, um deren Leistung, Kohärenz und Schlussfolgerungsfähigkeit zu verbessern. Als Nächstes wollen sie Methoden entwickeln, die im Embedding-Raum operieren - eine Idee die Metas KI-Chef Yann LeCun als zentral für die Zukunft der KI ansieht.
Menschliches Gehirn leistet mehr als Next-Token-Prediction
Die Initiative ist Teil einer Reihe neuerer Entwicklungen, die darauf abzielen, KI-Sprachmodelle der Funktionsweise des menschlichen Gehirns anzunähern. LeCun forscht beispielsweise an der "Joint Embedding Predictive Architecture" (JEPA) für autonome künstliche Intelligenzen. Deren zentrales "Weltmodell-Modul" soll eine hierarchische und abstrakte Repräsentation der Welt lernen, mit der sich Vorhersagen auf verschiedenen Abstraktionsebenen treffen lassen - vergleichbar mit dem menschlichen Gehirn.
Denn Studien deuten darauf hin, dass das Gehirn beim Sprachverstehen weiter vorausdenkt als heutige KI-Modelle. Statt nur das nächste Wort vorherzusagen, sagt es gleich mehrere Folgewörter voraus. Zudem nutzt es neben syntaktischen auch semantische Informationen für weitergehende und abstraktere Vorhersagen.
Für den Wissenschaftler Jean-Rémi King vom französischen Forschungszentrum CNRS, der ebenfalls für Meta forscht, ergibt sich aus diesen Erkenntnissen ein Forschungsauftrag an die KI: "Für bessere Sprachalgorithmen brauchen wir die Vorhersage hierarchischer Repräsentationen zukünftiger Eingaben."
Eine genaue Vorhersage langer Wortfolgen sei aufgrund der kombinatorischen Möglichkeiten schwierig. Abstraktere Repräsentationen wie die Bedeutung von Wortfolgen erlaubten aber zuverlässigere Vorhersagen.
Dieser Logik folgend rückt mit Multi-Token-Prediction und zukünftigen Ansätzen, die über die reine Wortvorhersage hinausgehen, die Vision von KI-Modellen näher, die viele Schwächen heutiger Modelle wie GPT-4 hinter sich lassen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.