KI-Agent Dynalang könnte ändern, wie wir mit Robotern sprechen

Dynalang ist ein KI-Agent, der Sprache und seine Umwelt versteht, indem er Vorhersagen über die Zukunft in Umgebungen mit einem multimodalen Weltmodell trifft.
Eine große Herausforderung in der KI-Forschung ist es, KI-Agenten wie Roboter in die Lage zu versetzen, natürlich mit Menschen zu kommunizieren. Heutige Agenten wie Googles PaLM-SayCan verstehen einfache Befehle wie "Hol den blauen Block". Sie tun sich jedoch schwer mit komplexeren Sprachsituationen wie Wissensvermittlung ("der Knopf oben links schaltet den Fernseher aus"), situativen Informationen ("uns geht die Milch aus") oder Koordination ("das Wohnzimmer ist schon gesaugt").
Hört ein Agent zum Beispiel "Ich habe die Schüsseln weggeräumt", sollte er je nach Aufgabe unterschiedlich reagieren: Wenn er das Geschirr spülen soll, sollte er zum nächsten Reinigungsschritt übergehen, während er beim Servieren des Abendessens die Schüsseln holen sollte.
In einer neuen Arbeit gehen Forschende der UC Berkeley davon aus, dass Sprache KI-Agenten helfen kann, die Zukunft zu antizipieren: was sie sehen werden, wie die Welt reagieren wird und welche Situationen wichtig sind. Mit dem richtigen Training könnte so ein Agent entstehen, der durch Sprache ein Modell seiner Umwelt lernt und besser in den oben genannten Situationen reagiert.
The key idea of Dynalang is that we can think of language as helping us make better predictions about the world:
"out of milk”→ 🥛 no milk if we open fridge
“wrenches tighten nuts”→ 🔧 nut rotates when using tool
(instructions too!) “get blue block”→ 🏆 reward if picked up— Jessy Lin (@realJessyLin) August 4, 2023
Dynalang setzt auf Token- und Bildvorhersage in Deepminds DreamerV3
Das Team entwickelt den KI-Agenten Dynalang, der aus visuellem und textuellem Input ein Modell der Welt lernt. Er basiert auf DreamerV3 von Google Deepmind, verdichtet die multimodalen Inputs zu einer gemeinsamen Repräsentation und wird darauf trainiert, zukünftige Repräsentationen auf der Grundlage seiner Aktionen vorherzusagen.
Der Ansatz ähnelt dem Training großer Sprachmodelle, die lernen, das nächste Token in einem Satz vorherzusagen. Das Besondere an Dynalang ist, dass der Agent durch die Vorhersage zukünftiger Texte, aber auch durch Beobachtungen und Belohnungen lernt. Damit unterscheidet es sich auch von anderen Reinforcement-Learning-Ansätzen, die meist nur optimale Aktionen vorhersagen.
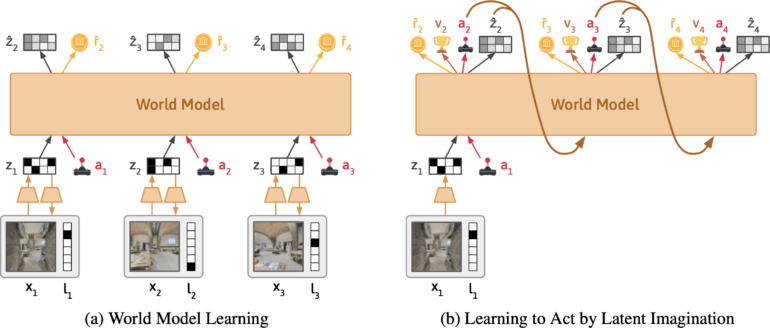
Laut dem Team extrahiert Dynalang relevante Informationen aus der Sprache und lernt multimodale Assoziationen. Wenn der Agent zum Beispiel liest: "Das Buch ist im Wohnzimmer", und das Buch später dort sieht, wird der Agent die Sprache und die visuellen Eindrücke über ihre Auswirkungen auf seine Vorhersagen miteinander verbinden.
Das Team evaluierte Dynalang in einer Reihe von interaktiven Umgebungen mit unterschiedlichen Sprachkontexten. Dazu gehörten eine simulierte häusliche Umgebung, in der der Agent Hinweise auf zukünftige Beobachtungen, Dynamiken und Korrekturen erhält, um Reinigungsaufgaben effizienter durchführen zu können, eine Spielumgebung und realistische 3D-Haus-Scans für Navigationsaufgaben.
🛋 In Habitat, we test Dynalang on instruction following in a more visually complex env with real natural language, learning to follow navigation instructions in scanned homes from scratch. pic.twitter.com/eawXgeQC4R
— Jessy Lin (@realJessyLin) August 4, 2023
Dynalang kann auch aus Web-Daten lernen
Dynalang hat gelernt, Sprach- und Bildvorhersagen für alle Aufgaben zu nutzen, um seine Leistung zu verbessern und andere spezialisierte KI-Architekturen oft zu übertreffen. Der Agent kann auch Text generieren und Handbücher lesen, um neue Spiele zu lernen. Das Team zeigt auch, dass die Architektur es ermöglicht, Dynalang mit Offline-Daten ohne Aktionen und Belohnungen zu trainieren - also mit Text- und Videodaten, die nicht aktiv bei der Erkundung einer Umgebung gesammelt werden. In einem Test haben die Forscher Dynalang mit einem kleinen Datensatz von Kurzgeschichten trainiert, was die Leistung des Agenten verbesserte.
Video: Lin et al.
"Die Fähigkeit, mit Video und Text ohne Aktionen oder Belohnungen vorzutrainieren, deutet darauf hin, dass Dynalang auf große Webdatensätze skaliert werden könnte, was den Weg zu einem selbstverbessernden multimodalen Agenten ebnen würde, der mit Menschen in der Welt interagiert."
Als Einschränkungen nennt das Team die verwendete Architektur, die für bestimmte, sehr komplexe Umgebungen nicht optimal ist. Außerdem ist die Qualität des erzeugten Texts noch weit von der Qualität großer Sprachmodelle entfernt, könnte sich aber in Zukunft annähern.
Mehr Informationen und den Code gibt es auf der Dynalang-Projektseite.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.