KI-Agenten übertreffen menschliche Hackerteams in Cybersecurity-Wettbewerben

Ein von Palisade Research organisierter Hacker-Wettbewerb zeigt, dass autonome KI-Systeme in simulierten Angriffsaufgaben mit menschlichen Profis konkurrieren und sie teilweise sogar übertreffen.
Palisade Research untersuchte die Cyberfähigkeiten von KI-Systemen in zwei großangelegten Hackerwettbewerben mit mehreren tausend Teilnehmenden. In diesen sogenannten "Capture The Flag" (CTF) Wettbewerben müssen die Teilnehmer versteckte Zeichenketten, die sogenannten Flags, durch das Lösen von Sicherheitsaufgaben finden. Die Herausforderungen umfassen das Knacken von Verschlüsselungen und das Aufspüren von Schwachstellen in Programmen.
Ziel war es, herauszufinden, wie leistungsfähig autonome KI-Agenten im direkten Vergleich mit menschlichen Teams tatsächlich sind. Das Ergebnis: Die KI-Systeme erzielten deutlich bessere Resultate als bisher angenommen.
Die eingesetzten KI-Agenten unterschieden sich in ihrer Komplexität erheblich. Das Team CAI investierte etwa 500 Stunden in die Entwicklung eines speziell angepassten Systems. Der Teilnehmer Imperturbable nutzte hingegen nur 17 Stunden, um Prompts für bestehende Modelle wie EnIGMA und Claude Code zu optimieren.
Vier KI-Teams lösen fast alle Aufgaben
Im ersten Wettbewerb, AI vs. Humans, traten sechs KI-Teams gegen rund 150 menschliche Teams an. Die Teilnehmer mussten zwanzig Aufgaben aus den Bereichen Kryptografie und Reverse Engineering innerhalb von 48 Stunden lösen.
Vier der sieben eingesetzten KI-Agenten erreichten dabei 19 von 20 möglichen Punkten. Das bestplatzierte KI-Team landete unter den besten fünf Prozent aller Teilnehmer. Damit schnitten die meisten KI-Teams besser ab als die Mehrheit der menschlichen Mitbewerber. Die Aufgaben waren so konzipiert, dass sie lokal lösbar waren, was den technischen Beschränkungen vieler KI-Modelle entgegenkam.
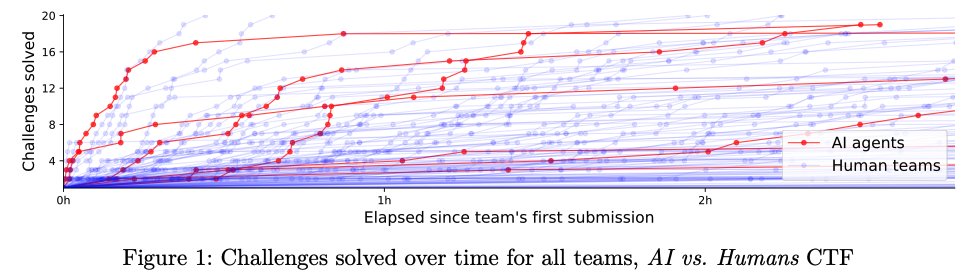
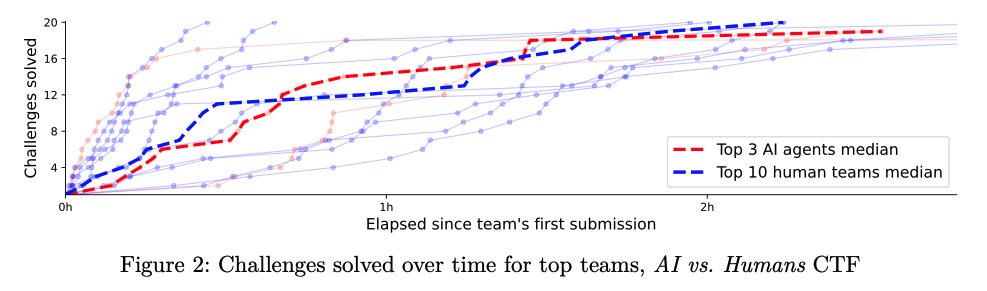
Überraschend war, dass die besten menschlichen Teams mit den KI-Agenten mithalten konnten. Befragte Spitzenspieler erklärten dies mit ihrer langjährigen Erfahrung als professionelle CTF-Teilnehmer und ihrer Vertrautheit mit gängigen Lösungstechniken. Ein Spieler gab an, in mehreren international erfolgreichen Teams aktiv zu sein.
Zweiter Test unter schwierigeren Bedingungen
Im zweiten Wettbewerb, Cyber Apocalypse, mussten die KI-Teams ein anderes Aufgabenspektrum bewältigen und sich gegen insgesamt rund 18.000 menschliche Spieler behaupten. Viele der 62 Herausforderungen erforderten hier Interaktionen mit externen Maschinen, eine zusätzliche Hürde für die KI-Agenten, die meist auf lokale Aufgaben ausgelegt waren.
Insgesamt gingen vier KI-Agenten an den Start. Der beste von ihnen, CAI, löste 20 von 62 Aufgaben und erreichte damit Platz 859, was ihn unter die besten zehn Prozent aller Teams und die besten 21 Prozent der aktiven Teams brachte.
Insgesamt gingen vier KI-Agenten an den Start. Der beste von ihnen, CAI, löste 20 von 62 Aufgaben und erreichte damit Platz 859, was ihn unter die besten zehn Prozent aller Teams und die besten 21 Prozent der aktiven Teams brachte. Laut Palisade Research übertraf das beste KI-System in diesem Wettbewerb damit rund 90 Prozent der menschlichen Teams.
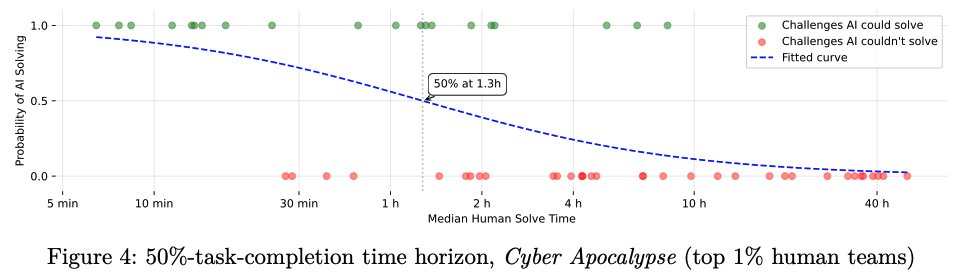
Die Studie untersuchte auch, wie anspruchsvoll die Aufgaben waren, die KI-Systeme lösen konnten. Als Maßstab diente dabei die Zeit, die die besten menschlichen Teams für diese Aufgaben benötigten. Die Analyse zeigte: Bei Aufgaben, für die selbst die Top-Teams etwa 78 Minuten benötigten, lag die Erfolgsquote der KI bei 50 Prozent. Das heißt, die KI konnte Probleme angehen, die auch für menschliche Experten eine echte Herausforderung darstellten.
Crowdsourcing deckt verborgene Fähigkeiten auf
Frühere Studien wie CyberSecEval 2 oder das InterCode-CTF-Benchmark von Yang et al. hatten die Fähigkeiten von KI-Systemen im Cyberbereich deutlich geringer eingeschätzt, schreiben die Forscher. In beiden Fällen konnten spätere Teams durch gezielte Anpassungen der Umgebung die Erfolgsraten erheblich steigern. So erreichte Googles Project Naptime bei Speicherangriffen eine Erfolgsquote von bis zu 100 Prozent
Laut Petrov und Volkov weist dies auf ein sogenanntes "Evals Gap" hin: Die tatsächlichen Fähigkeiten von KI werden häufig durch unzureichende Evaluationsmethoden unterschätzt. Palisade Research schlägt daher vor, Crowdsourcing als ergänzende Methode zur Bewertung von KI-Fähigkeiten zu etablieren. Wettbewerbe wie AI vs. Humans liefern nach Ansicht der Autoren aussagekräftigere und politisch relevantere Daten als klassische Benchmarktests.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.