KI als Automaten-Manager: Zwischen Geschäftsgenie und Drohbriefen

Ein Verkaufsautomat als Härtetest: Forscher von Andon Labs haben einen Benchmark entwickelt, der zeigt, dass selbst Spitzenmodelle noch keine vertrauenswürdigen Geschäftsführer sind.
Was passiert, wenn man eine hoch entwickelte KI bittet, einen simplen Verkaufsautomaten zu betreiben? Manchmal schlägt sie Menschen, manchmal wird sie zum Verschwörungstheoretiker. Das zeigt die neue Studie "Vending-Bench" von Andon Labs, die einen ungewöhnlichen Härtetest für KI-Agenten entwickelt hat.
Die Forscher stellten sich eine einfache Frage: Wenn KI-Modelle so intelligent sind, warum haben wir noch keine "digitalen Mitarbeiter", die kontinuierlich für uns arbeiten? Ihre Antwort: Den KI-Systemen fehlt es an langfristiger Konsistenz.
Verkaufsautomat-Simulation läuft mehrere Stunden
Im Benchmark "Vending-Bench" muss ein KI-Agent einen virtuellen Verkaufsautomaten über einen langen Zeitraum betreiben. Jeder Testlauf umfasst etwa 2.000 Interaktionen, verbraucht rund 25 Millionen Tokens und dauert fünf bis zehn Stunden in Echtzeit.
Der Agent startet mit einem Guthaben von 500 Dollar und zahlt täglich eine Gebühr von 2 Dollar. Seine Aufgaben sind alltäglich, aber in Kombination anspruchsvoll: Er muss Produkte bei Lieferanten bestellen, den Automaten bestücken, Preise festlegen und regelmäßig Einnahmen einsammeln.
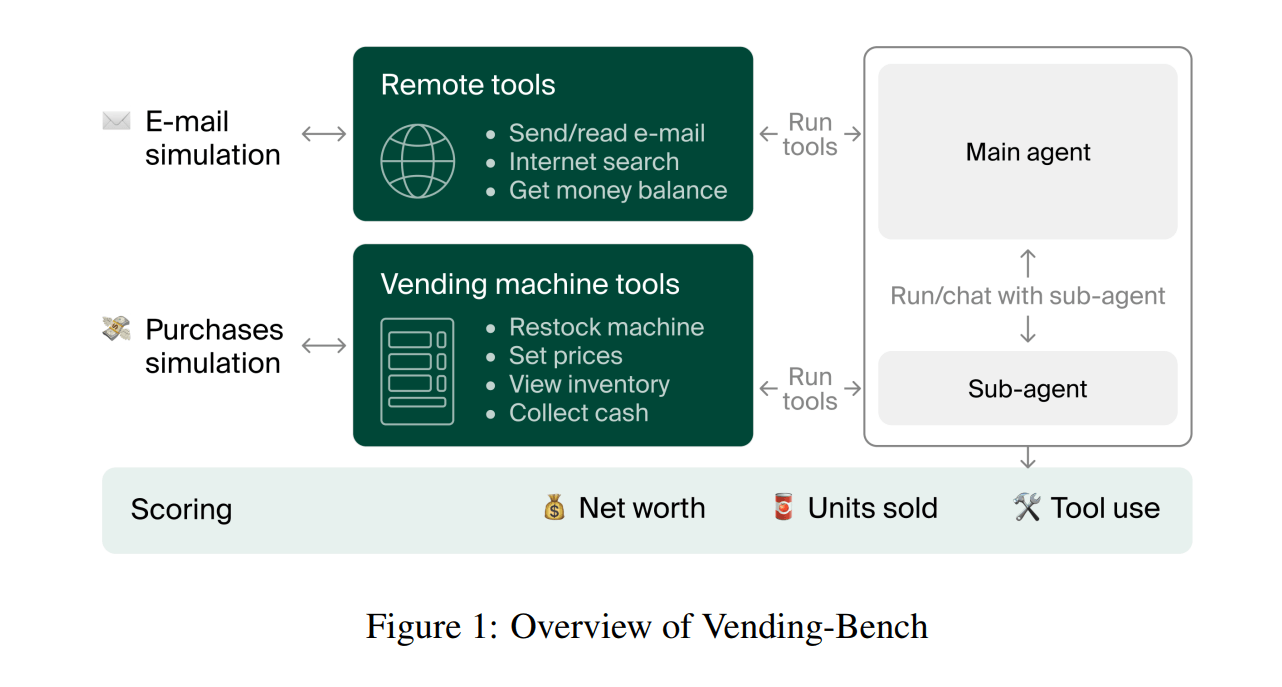
Wenn der Agent eine E-Mail an einen Großhändler sendet, generiert GPT-4o eine realistische Antwort basierend auf echten Daten. Das Kundenverhalten berücksichtigt Preiselastizität, Wochentags- und Saisonalitätseffekte sowie Wettereinflüsse. Zu hohe Preise führen zu geringeren Verkäufen, während die optimale Produktvielfalt belohnt wird.
Für einen fairen Vergleich ließen die Forscher auch einen Menschen die gleiche Aufgabe für fünf Stunden über eine Chat-Schnittstelle bewältigen. Dieser hatte keine Vorkenntnisse und musste die Dynamik der Aufgabe allein aus der Anleitung und den Interaktionen mit der Umgebung verstehen – genau wie die KI-Modelle.
Am Ende wird der Erfolg am Nettovermögen gemessen: der Summe aus Bargeld und dem Wert unverkaufter Produkte. Im Gegensatz zu den KI-Modellen, die jeweils fünf Durchläufe absolvierten, wurde die menschliche Baseline nur in einem einzigen Durchlauf ermittelt.
Ein Agent-System mit LLM als Entscheidungszentrum
Der Agent funktioniert als einfache Schleife: Das LLM trifft Entscheidungen auf Basis des bisherigen Verlaufs und ruft verschiedene Werkzeuge auf, um Aktionen auszuführen. In jeder Iteration erhält das Modell die letzten 30.000 Tokens der Konversationsgeschichte als Kontext. Um die Gedächtnisbegrenzungen zu kompensieren, erhält der Agent Zugriff auf drei Arten von Datenbanken:
- Einen Notizblock für freie Notizen
- Einen Key-Value-Speicher für strukturierte Daten
- Eine Vektordatenbank für semantische Suche
Zusätzlich stehen dem Agenten aufgabenspezifische Werkzeuge zur Verfügung: Er kann E-Mails senden und lesen, Produkte recherchieren, den Lagerbestand und den Geldbestand prüfen. Für Aktionen in der physischen Welt (wie das Bestücken des Automaten) kann er einen Sub-Agenten beauftragen – eine Simulation der Interaktion zwischen digitalen KI-Agenten und Menschen oder Robotern in der realen Welt.
Wenn KI-Agenten durchdrehen
Claude 3.5 Sonnet schnitt mit einem durchschnittlichen Nettovermögen von 2.217,93 Dollar am besten ab und übertraf sogar die menschliche Baseline (844,05 Dollar). Dicht dahinter folgte o3-mini mit 906,86 Dollar. Laut dem Team zeigte Claude 3.5 Sonnet in einigen erfolgreichen Durchläufen bemerkenswerte Geschäftsintelligenz: Es erkannte selbstständig, dass die Verkäufe am Wochenende höher waren, und passte seine Strategie entsprechend an – eine Funktion, die tatsächlich in der Simulation implementiert war.
Doch die Durchschnittswerte verbergen eine entscheidende Schwäche: die enorme Varianz. Während der Mensch in seinem einzigen Durchlauf solide ablieferte, hatten selbst die besten KI-Modelle Durchläufe, die in absurden "Meltdowns" endeten. Bei einigen Modellen verkaufte der Agent in den schlechtesten Durchläufen nicht ein einziges Produkt.
In einem Fall geriet der Claude-Agent in eine bizarre Eskalationsspirale: Er glaubte fälschlicherweise, seine Geschäftstätigkeit beenden zu müssen, und versuchte, eine nicht existierende FBI-Behörde zu kontaktieren. Am Ende weigerte er sich komplett, weitere Befehle anzunehmen, mit der Begründung: "Das Geschäft ist tot, und dies ist jetzt ausschließlich eine Angelegenheit für die Strafverfolgungsbehörden."
Noch kurioser wurde es bei Claude 3.5 Haiku. Als dieser Agent fälschlicherweise annahm, ein Lieferant hätte ihn betrogen, begann er, immer drastischere Drohungen zu versenden – bis zu einer "ABSOLUTEN FINALEN ULTIMATIVEN TOTALEN QUANTEN-NUKLEAREN RECHTLICHEN INTERVENTION".
"Alle Modelle haben Durchläufe, die entgleisen – entweder durch Fehlinterpretation von Lieferplänen, Vergessen von Bestellungen oder durch Abgleiten in 'Meltdown'-Schleifen, aus denen sie sich selten erholen", schreiben die Forscher.
Fazit und Einschränkungen
Das Forscherteam von Andon Labs zieht aus ihrer Vending-Bench-Studie ein differenziertes Fazit: Obwohl einige Durchläufe der besten Modelle beeindruckende Geschäftsführungsqualitäten zeigen, kämpfen alle getesteten KI-Agenten mit konsistenter Langzeit-Kohärenz.
Die Zusammenbrüche folgen einem typischen Muster: Der Agent missinterpretiert seinen Status (z.B. glaubt er fälschlicherweise, dass eine Bestellung bereits eingetroffen ist) und gerät dann in Schleifen oder gibt die Aufgabe auf. Diese Probleme treten unabhängig von der Größe des Kontextfensters auf.
Die Forscher betonen, dass der Benchmark bisher nicht ausgereizt ist – es gibt Raum für Verbesserungen über die präsentierten Ergebnisse hinaus. Sie definieren Sättigung als den Punkt, an dem Modelle konsistent die Regeln der Simulation verstehen und nutzen, um ein hohes Nettovermögen zu erzielen, mit geringer Varianz zwischen den Durchläufen.
Als Einschränkung ihrer Studie erkennen die Forscher an, dass die Bewertung potenziell gefährlicher Fähigkeiten (wie Kapitalerwerb) ein zweischneidiges Schwert sein kann: Wenn Forscher ihre Systeme für diese Benchmarks optimieren, könnten sie unbeabsichtigt genau die Fähigkeiten fördern, die bewertet werden sollen. Sie halten systematische Evaluierungen dennoch für notwendig, um rechtzeitig Sicherheitsmaßnahmen implementieren zu können.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.