KI-Coding kann Entwickler langsamer machen – auch wenn sie sich schneller fühlen

Update –
- Einschätzung von Studienteilnehmer Quentin Anthony ergänzt
Update vom 13. Juli 2025:
Quentin Anthony, einer der 16 beteiligten Entwickler, meldete sich öffentlich zu Wort. Ihm gelang es, bei seinen Aufgaben mithilfe von KI eine Verkürzung der Bearbeitungszeit um 38 Prozent zu erreichen – eine Ausnahme im Gesamtergebnis.
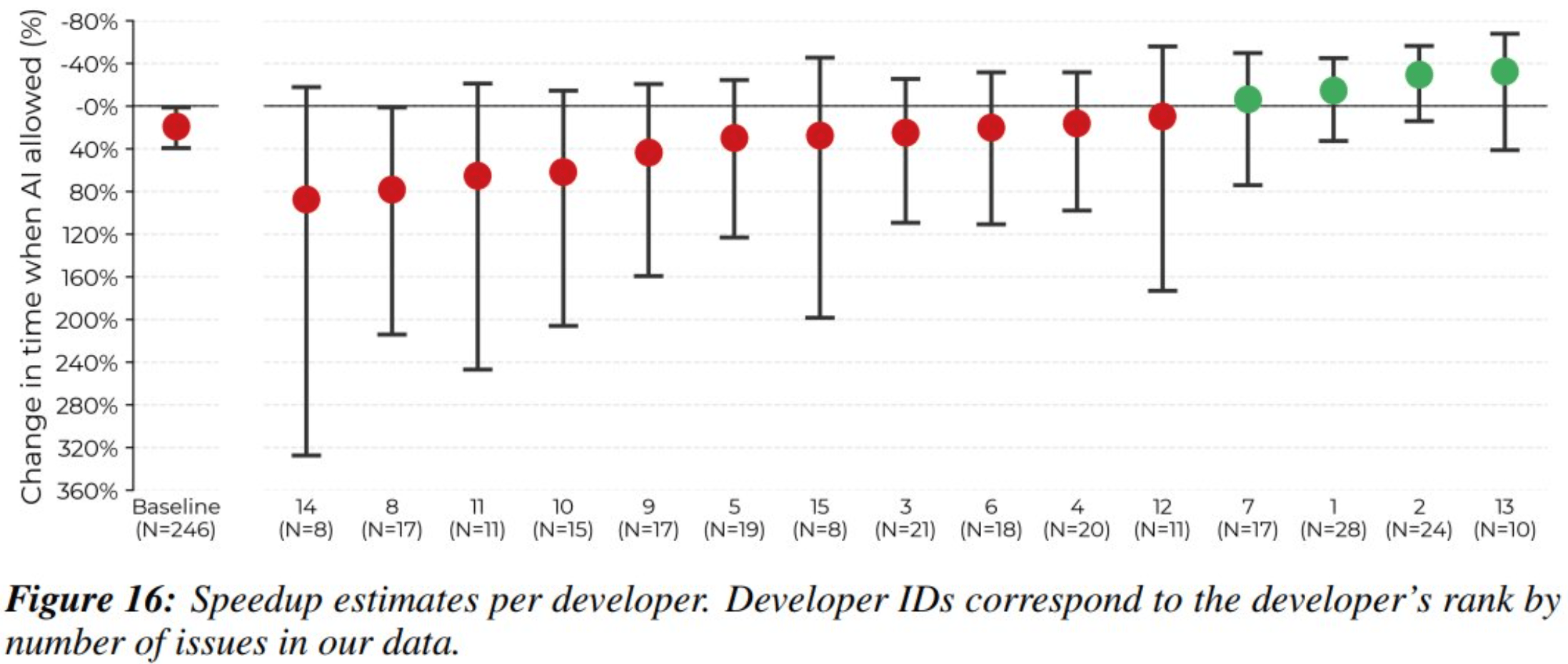
Er erklärt den allgemeinen Produktivitätsverlust nicht mit mangelnder Kompetenz, sondern mit typischen Fehlanwendungen: "Wir sagen zwar, dass LLMs Werkzeuge sind, behandeln sie aber wie eine Wunderwaffe", so Anthony. Ihrer vermeintlichen Nähe zur Lösung wegen neige man dazu, zu viel Zeit mit ihnen zu verbringen, statt effizient zur Zielerreichung beizutragen.
Zudem verweist Anthony auf technische Limitierungen: Große Sprachmodelle seien sehr ungleich verteilt in ihren Fähigkeiten – etwa stark bei Test-Code, aber schwach bei Low-Level-Systementwicklung wie GPU-Kernels oder Synchronisationslogik. Auch der sogenannte "Context Rot", bei dem LLMs durch zu lange oder irrelevante Kontextverläufe unzuverlässig werden, trage dazu bei, dass Entwickler in ineffiziente Interaktionen abrutschen.
Sein Tipp: Konsequent neue Chats starten, Modelle gezielt nach bekannten Stärken auswählen und die Zeit mit LLMs aktiv begrenzen.
Anthony nutzt unterschiedliche Modelle für verschiedene Aufgaben – etwa Gemini für Codeverständnis, Claude für Refaktorierung und Debugging – und bevorzugt direkte API-Zugriffe über IDE-Integrationen, um besser zu kontrollieren, was das Modell tatsächlich sieht. Für ihn ist klar: "LLMs sind Werkzeuge, aber wir müssen ihre Grenzen kennen – und unsere eigenen."
Ursprünglicher Artikel vom 11. Juli 2025:
Eine neue Studie zeigt: Erfahrene Open-Source-Entwickler arbeiten mit KI-Tools langsamer, obwohl sie selbst das Gegenteil glauben.
Eine randomisierte Studie des Forschungsinstituts METR untersucht, wie fortgeschrittene KI-Tools Anfang 2025 die Produktivität erfahrener Open-Source-Entwickler beeinflussen. Mit KI dauert es im Schnitt 19 Prozent länger, reale Entwicklungsaufgaben zu lösen – obwohl die Entwickler selbst das Gegenteil glauben.
Subjektive Beschleunigung – objektive Verlangsamung
Das Herzstück der Studie bildeten 16 erfahrene Entwickler, die 246 reale Aufgaben aus ihren eigenen, komplexen Open-Source-Projekten bearbeiteten. Noch bevor die eigentliche Arbeit begann, wurde die Erwartung der Entwickler erfasst: Sie schätzten, dass der Einsatz von KI ihre Arbeit um beachtliche 24 Prozent beschleunigen würde.
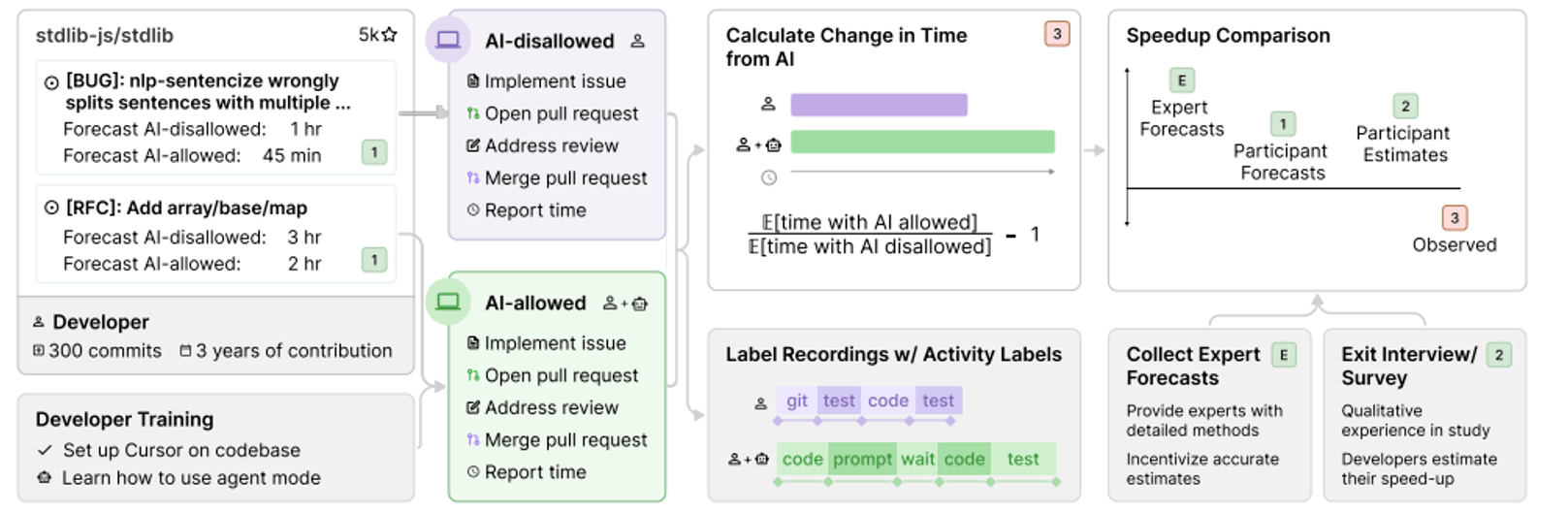
Anschließend wurde jede einzelne Aufgabe per Zufallsprinzip einer von zwei Gruppen zugeteilt. In der Kontrollgruppe arbeiteten die Entwickler klassisch, ohne generative KI. In der Experimentalgruppe durften sie KI-Assistenten einsetzen, wobei hauptsächlich Cursor Pro mit den damaligen Spitzenmodellen Claude 3.5 und 3.7 Sonnet zum Einsatz kam.
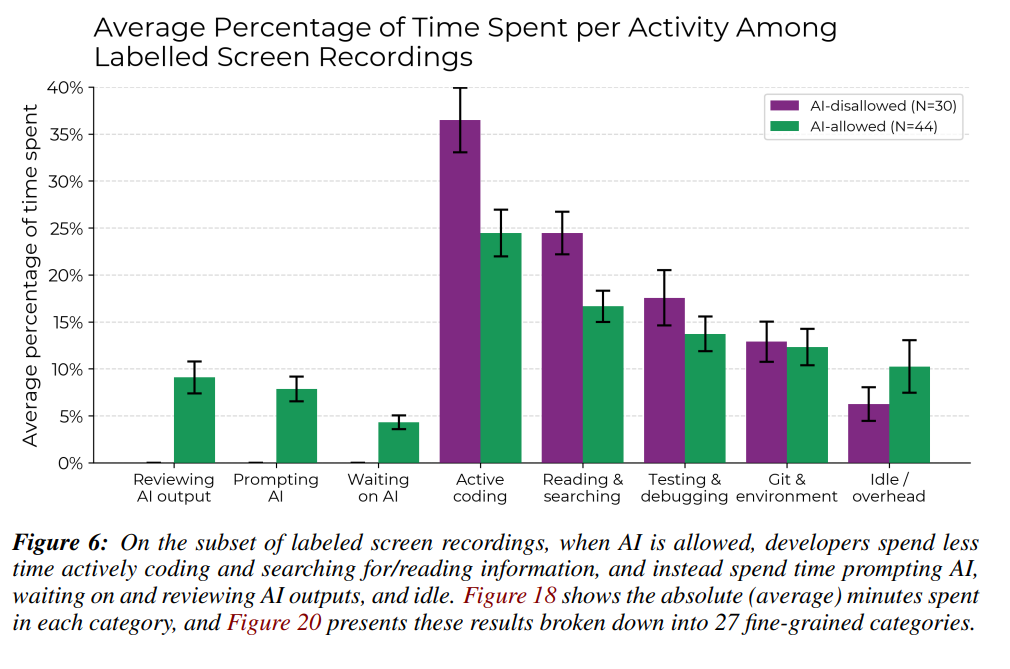
Während der Bearbeitung zeichneten die Entwickler ihre Bildschirme auf und meldeten am Ende die tatsächlich benötigte Implementierungszeit. Um Unterschiede im Schwierigkeitsgrad der Aufgaben zu berücksichtigen, nutzten die Forschenden für die Auswertung ein statistisches Verfahren, das die zuvor von den Entwicklern geschätzte Dauer jeder einzelnen Aufgabe einbezieht. Dadurch konnten sie genau herausfinden, wie stark der Einsatz von KI die Arbeitszeit beeinflusst hat – unabhängig davon, ob die Aufgabe besonders leicht oder schwer war.
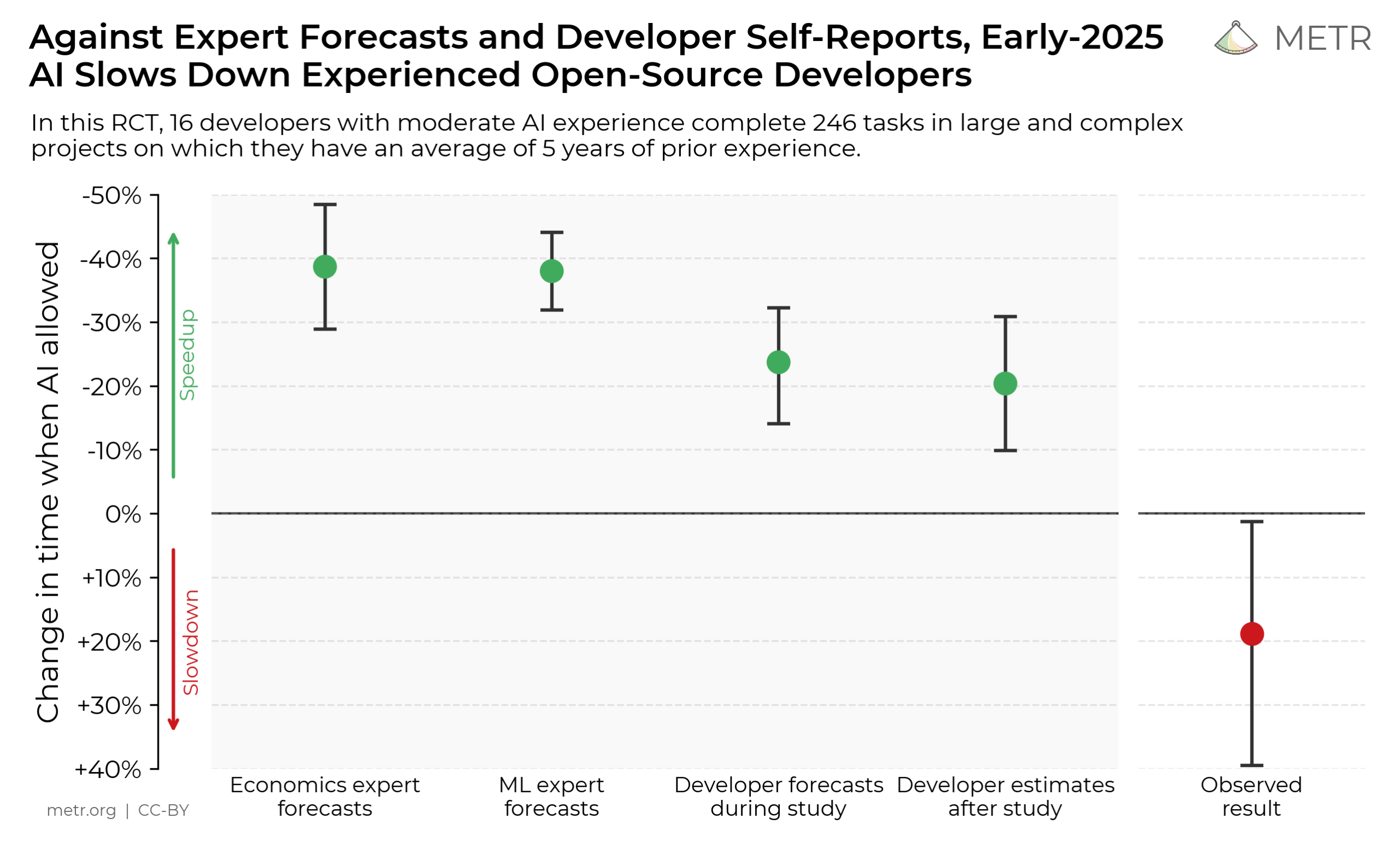
Der entscheidende Punkt offenbarte sich beim Vergleich der Daten: Obwohl die Entwickler mit KI-Unterstützung objektiv 19 Prozent länger benötigten, war ihre subjektive Einschätzung eine vollkommen andere. Selbst nach Abschluss der Aufgaben glaubten sie weiterhin, durch die KI um 20 Prozent schneller gewesen zu sein.
Um die Ergebnisse abzusichern, schlossen die Forscher auch gezielt mögliche Verzerrungen als Hauptursache aus. Die Verlangsamung war demnach nicht auf eine unvertraute Arbeitsumgebung zurückzuführen, da auch erfahrene Nutzer betroffen waren und kein Lerneffekt eintrat. Ebenso wenig lag es an veralteten KI-Modellen – die eingesetzten Systeme wie Claude 3.7 Sonnet waren zum Studienzeitpunkt hochmodern. Anhand von Bildschirmaufnahmen und robusten statistischen Tests stellten die Forscher zudem sicher, dass weder Regelverstöße noch die Messmethode selbst das Ergebnis verfälschten.
Neue Messmethoden für reale KI-Auswirkungen
Laut METR zeigt die Studie, dass neue Evaluierungsmethoden notwendig sind, um die tatsächliche Leistungsfähigkeit generativer KI abzubilden. Klassische Benchmarks wie SWE-Bench oder RE-Bench testen meist in sich geschlossene Aufgaben, die keinen vorherigen Kontext erfordern und algorithmisch bewertet werden. Das kann zu einer Über- oder Unterschätzung der tatsächlichen Fähigkeiten führen.
Randomisierte Kontrollstudien (RCTs) ergänzen dieses Bild, indem sie reale Aufgaben in realistischen Umgebungen untersuchen. Sie liefern damit wichtiges Zusatzwissen über den tatsächlichen Nutzen – oder auch Schaden – von KI im Arbeitsalltag von Entwicklern.
Ich fragte unseren KI-Entwickler, ob sich die Ergebnisse mit seinen Eindrücken aus dem Arbeitsalltag decken. Er hält sie für plausibel, insbesondere im Kontext gewachsener, komplexer Projekte mit hohen Qualitätsanforderungen und zahlreichen impliziten Regeln wie in Open-Source-Projekten. Hier könnten KI-Tools zusätzlichen Erklärungs- und Kontrollaufwand verursachen.
Anders verhalte es sich bei neuen Projekten oder beim schnellen Prototyping sowie der Arbeit mit bislang unbekannten Frameworks. In solchen Szenarien könnten KI-Tools ihre Stärken ausspielen und Entwickler tatsächlich unterstützen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.