KI-Diagnostik: Neues KI-System steigert Genauigkeit um bis zu 8 Prozent
Zuverlässige KI-Systeme für die Medizin benötigen hochwertige Daten. Doch die sind noch immer selten. Ein neues Modell könnte das Problem umgehen.
Künstliche Intelligenz für die medizinische Diagnostik verspricht eine bessere Versorgung von Patient:innen. Besonders hilfreich wäre das dort, wo Fachkräfte rar und Wartezeiten lang sind. Erste Systeme für die diagnostische Bildanalyse sind bereits zugelassen.
Doch die Entwicklung der KI-Systeme erfordert von menschlichen Expert:innen sogenannte "gelabelte Daten", etwa Röntgenaufnahmen der Lunge, auf denen verdächtiges und identifiziertes Krebsgewebe so markiert wurde, dass es für Computer lesbar ist. Diese Trainingsdaten sind noch immer selten und teuer, da - anders als bei anderen Anwendungsfällen der KI-Bildanalyse - nur ausgewiesene Expert:innen die Daten aufarbeiten können.
KI in der Medizin: Vortrainierte Modelle lernen schneller
Eine mögliche Lösung: Mit massenhaft nicht gelabelten Daten werden KI-Modelle - von Expert:innen überwacht - vortrainiert und anschließend mit den begrenzt verfügbaren Daten auf ihre Aufgabe spezialisiert. Die Modelle lernen während des KI-Trainings in den Daten vorhandene Muster, die dann mit überwachtem Training genutzt werden können.
Dieser Ansatz kommt bereits seit Längerem erfolgreich in Sprach-Systemen wie GPT-3 zum Einsatz. Auch in der Bildanalyse hat sich der Ansatz mittlerweile bewährt. Mitte 2020 knackte ein mit drei Milliarden Bildern vortrainiertes KI-System von Google die Bestwerte im ImageNet-Benchmark.
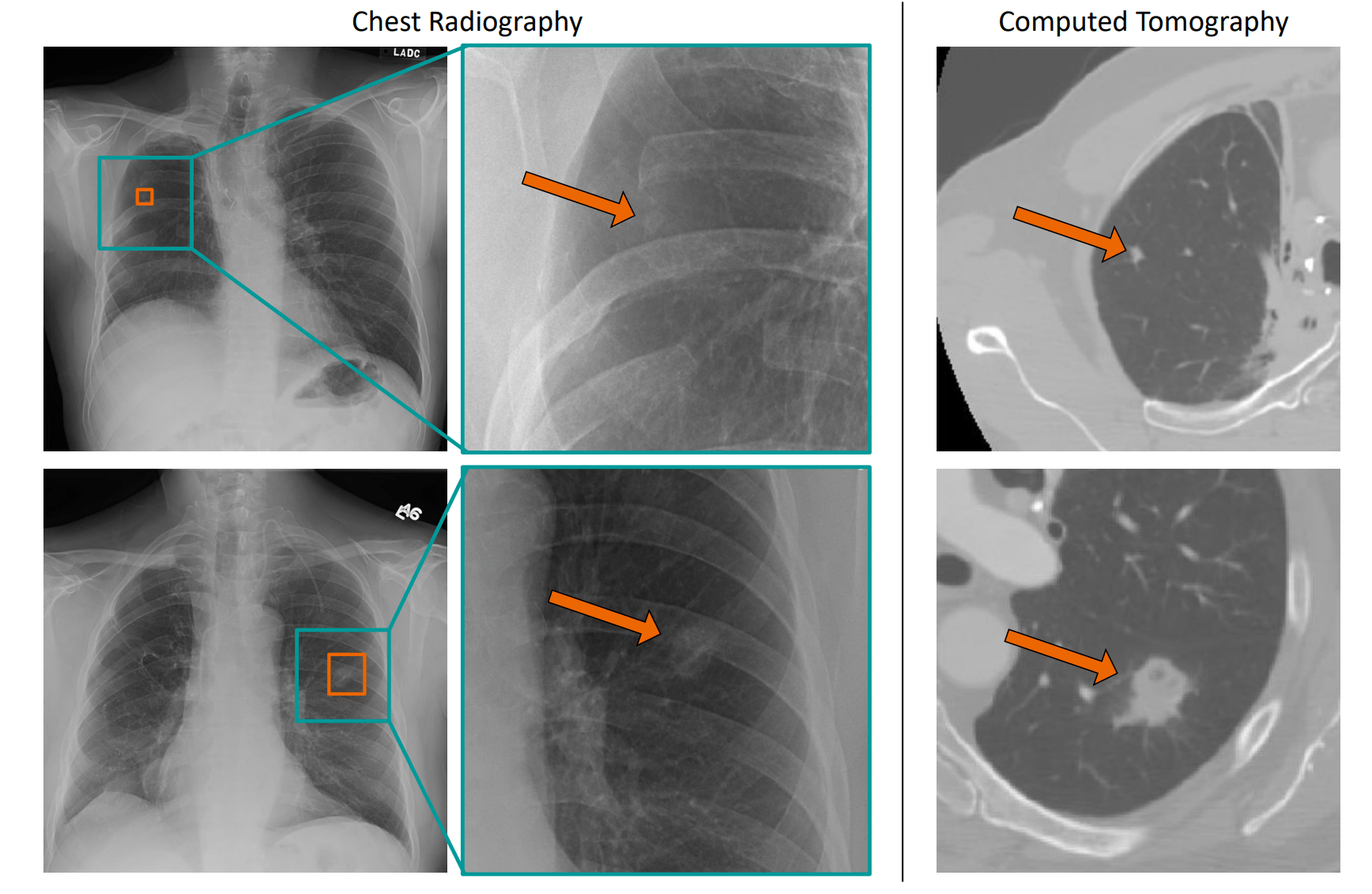
Forschende haben nun vortrainierte Modelle für Diagnostik-Systeme vorgestellt. Ein KI-Modell wurde mit knapp 105 Millionen Bildern verschiedener Anatomien (Kopf, Unterleib, Brust, Beine, etc.) trainiert.
Die Bilder setzen sich aus Aufnahmen aus der Computertomografie (CT), Magnetresonanztomografie (MRT), Röntgenaufnahmen und Ultraschallaufnahmen zusammen. Zudem wurde keiner der Datensätze gelabelt. Ein zweites Modell wurde außerdem mit etwa 24500 3D-Gehirnaufnahmen trainiert.
Das Training nahm je nach KI-Modell bis zu zwei Wochen auf vier Serverknoten mit jeweils acht Nvidia Volta GPUs mit 16 Gigabyte, 80 CPU-Kernen und 512 Gigabyte Speicher in Anspruch. Das Team experimentierte zudem mit verschiedenen Architekturen.
Mit 100 Millionen Bildern zum besten KI-System
Die Forschenden trainierten anschließend die bereits vortrainierten Modelle mit von Expert:innen gelabelten Datensätzen. Das erste Modell lernte anhand von rund 300 gelabelten Thorax-Röntgenaufnahmen, Lungenläsionen und Pneumothorax zu erkennen. Eine Version dieses ersten Modells lernte mit 341 weiteren Aufnahmen, Metastasen im Gehirn in 3D-MRT-Aufnahmen zu identifizieren. Eine Variante des zweiten Modells lernte, mit über 3000 Aufnahmen Hirnblutungen in 3D-CT-Aufnahmen zu erkennen.
In allen Fällen wiesen diese Systeme, die auf die vortrainierten Modelle aufbauen, eine höhere Genauigkeit auf als aktuelle Alternativen, die ausschließlich mit gelabelten Daten trainiert wurden: Die Genauigkeit stieg um sechs bis acht Prozent. Das ist gerade ohne zusätzliche gelabelte Daten ein beachtlicher Erfolg.
Die Systeme seien außerdem robuster und lernten ihre Aufgabe bis zu 85 Prozent schneller, schreiben die Forschenden. Verbesserungen sollen in Zukunft ein schnelleres KI-Training und so schnellere Iterationen der vortrainierten Modelle sowie diversere Modelle für weitere Diagnostik-Aufgaben ermöglichen.
Die Vor- und Nachteile verschiedener KI-Trainingsmethoden und speziell des Reinforcement Learning besprechen wir mit dem KI-Forscher Tim Rocktäschel in unserem DEEP MINDS Podcast.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.