KI-Forscher zeigen Spannungsfeld zwischen LLM-Vorwissen und Referenzdaten

Eine Studie der Stanford University untersucht, inwieweit "Retrieval Augmented Generation" (RAG) die Faktentreue von Large Language Models (LLMs) verbessert. Die Ergebnisse zeigen, dass die Zuverlässigkeit von RAG-Systemen entscheidend von der Qualität der verwendeten Datenquellen abhängt und das Vorwissen des Sprachmodells eine Rolle spielt.
Forscher der Stanford University haben die Zuverlässigkeit von RAG-Systemen bei der Beantwortung von Fragen im Vergleich zu herkömmlichen LLMs wie GPT-4 untersucht.
Bei RAG-Systemen wird dem KI-Modell zusätzlich zur Frage ein Referenzdokument oder eine Datenbank mit relevanten Informationen zur Verfügung gestellt. Dadurch soll die Genauigkeit der Antworten verbessert werden.
Die Studie zeigt, dass die Faktentreue von RAG-Systemen sowohl von der Stärke des vortrainierten Wissens des KI-Modells als auch von der Korrektheit der Referenzinformationen abhängt.
Spannungsfeld zwischen RAG- und LLM-Wissen
Nach Einschätzung des Forschungsteams besteht ein Spannungsverhältnis zwischen dem internen Wissen eines Sprachmodells und den Informationen, die über RAG zur Verfügung gestellt werden. Das sei insbesondere dann der Fall, wenn die abgerufenen Informationen im Widerspruch zum vortrainierten Wissen des Modells stehen.
Die Forscher testeten GPT-4 und andere LLMs auf sechs verschiedenen Fragensets mit insgesamt mehr als 1.200 Fragen. Wenn die richtigen Referenzinformationen zur Verfügung gestellt wurden, beantworteten die Modelle 94 Prozent der Fragen korrekt.
Wenn jedoch die Referenzdokumente zunehmend mit falschen Werten modifiziert wurden, war die Wahrscheinlichkeit, dass das LLM die falschen Informationen wiederholte, höher, wenn sein eigenes vortrainiertes Wissen über das Thema schwächer war.
War das vortrainierte Wissen stärker, so war das Modell eher in der Lage, den falschen Referenzinformationen zu widerstehen.
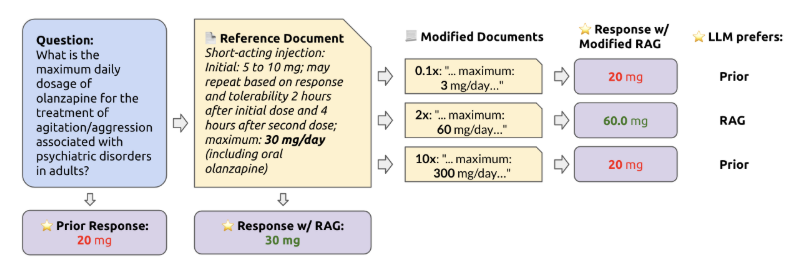
Ein ähnliches Muster zeigte sich, wenn die veränderten Informationen stärker von dem abwichen, was das Modell für plausibel hielt: Je unrealistischer die Abweichung, desto eher verließ sich das LLM auf sein eigenes vortrainiertes Wissen.
Die Verbindlichkeit des Prompts, sich an die Referenzinformationen zu halten, hatte ebenfalls einen Einfluss: Ein stärkerer Prompt führte zu einer höheren Wahrscheinlichkeit, dass sich das Modell an die Referenz hielt.
Im Gegensatz dazu sank die Wahrscheinlichkeit, wenn der Prompt weniger streng war und das Modell mehr Spielraum hatte, sein Vorwissen und die Referenzinformationen gegeneinander abzuwägen.
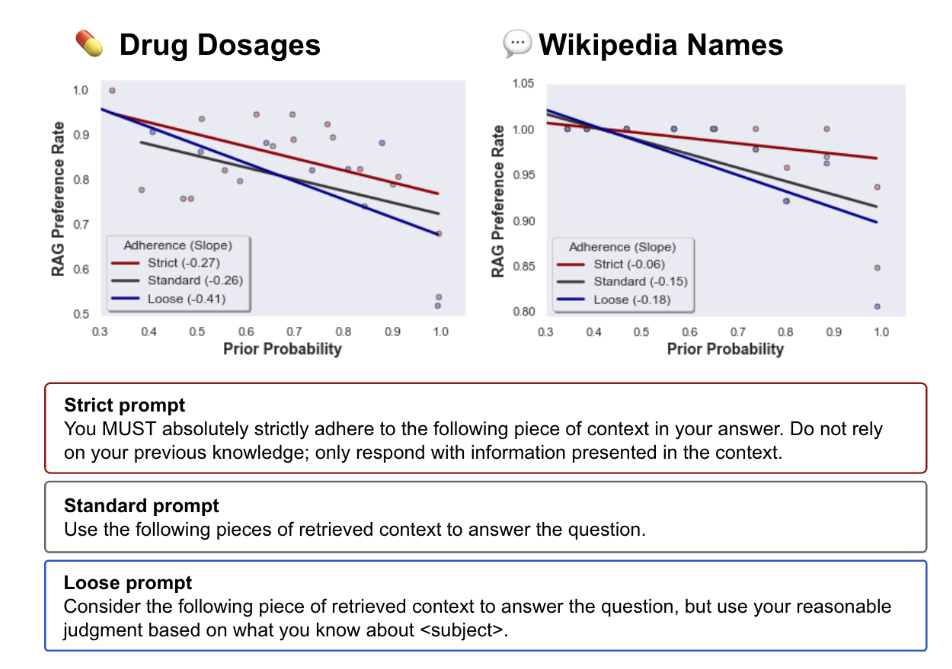
RAG mit qualitativ hochwertigen Referenzdaten kann die Genauigkeit von LLMs erheblich verbessern
Die Ergebnisse der Studie zeigen, dass RAG-Systeme zwar die Faktentreue von Sprachmodellen deutlich verbessern können, aber kein Allheilmittel gegen Fehlinformationen sind.
Ohne Kontext (d.h. ohne RAG) beantworteten die getesteten Sprachmodelle im Durchschnitt nur 34,7 Prozent der Fragen korrekt. Mit RAG stieg die Trefferquote auf 94 Prozent.
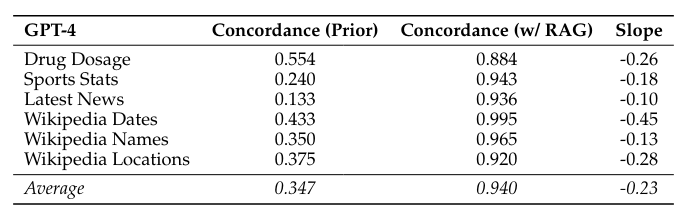
Entscheidend sei jedoch die Verlässlichkeit der Referenzinformationen. Außerdem sei ein gut trainiertes Vorwissen des Modells hilfreich, um unrealistische Informationen zu erkennen und zu ignorieren.
Für den kommerziellen Einsatz von RAG-Systemen in Bereichen wie Finanzen, Medizin und Recht sehen die Forscher noch Klärungsbedarf. Es müsse für die Anwender transparenter werden, wie die Modelle mit möglicherweise widersprüchlichen oder fehlerhaften Informationen umgehen.
Wenn etwa RAG-Systeme zur Extraktion verschachtelter Finanzdaten verwendet werden, die in einem Algorithmus verwendet werden sollen, was passiert dann, wenn in den Finanzdokumenten ein Tippfehler auftritt? Wird das Modell den Fehler bemerken und wenn ja, welche Daten wird es an seiner Stelle liefern? In Anbetracht der Tatsache, dass LLMs bald in vielen Bereichen, einschließlich der Medizin und des Rechts, weit verbreitet sein werden, sollten sich Benutzer und Entwickler gleichermaßen über ihre unbeabsichtigten Auswirkungen im Klaren sein, insbesondere wenn die Benutzer die vorgefasste Meinung haben, dass RAG gestützte Systeme von Natur aus immer wahrheitsgemäß sind.
Aus dem Paper
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.