KI-Grübelei: Auch Sprachmodelle können zu viel nachdenken

KI verspricht die Lösung komplexer Probleme. Doch gerade Sprachmodelle, die für logisches Denken optimiert sind, zeigen in interaktiven Umgebungen eine unerwartete Schwäche: Sie "denken" oft zu viel, anstatt zu handeln.
Eine neue Studie hat erstmals umfassend untersucht, wie "Large Reasoning Models" (LRMs) in interaktiven Szenarien, sogenannten "Agentic Tasks", agieren. Das dabei auftretende Phänomen, das von den Forschern als "Overthinking" bezeichnet wird, kann ihre Leistung erheblich beeinträchtigen.
Agentic Tasks zeichnen sich dadurch aus, dass die KI-Modelle autonom Ziele verfolgen, natürliche Sprachschnittstellen nutzen und strukturierte Ausgaben produzieren müssen, um andere Tools zu verwenden. Konkret bedeutet das, die KI muss Informationen sammeln, speichern und darauf basierend handeln.
Das Team aus verschiedenen US-Universitäten und der ETH Zürich hat Methoden entwickelt, um dieses Overthinking zu quantifizieren und Strategien zu entwickeln, um die negativen Folgen zu mildern.
Das "Reasoning-Action Dilemma"
Die Forschenden definieren "Overthinking" als die Tendenz eines KI-Modells, sich übermäßig auf interne Simulationen und Überlegungen zu verlassen und dabei wichtiges Feedback aus der realen Umgebung zu vernachlässigen.
Das führt zu einem Dilemma, das die Wissenschaftler:innen als "Reasoning-Action Dilemma" bezeichnen: Die KI muss ständig abwägen zwischen direkter Interaktion mit der Umgebung, um Feedback zu erhalten, und interner Simulation, um mögliche Aktionen und Konsequenzen zu durchdenken.
Selbst mit unbegrenzten Ressourcen bleiben "zu nachdenkliche" KI-Modelle durch die Grenzen ihres unvollständigen oder fehlerhaften Weltmodells eingeschränkt, was zu sich aufschaukelnden Fehlern und einer suboptimalen Entscheidungsfindung führt, argumentieren sie.
Overthinking quantifizieren
Um "Overthinking" zu quantifizieren, entwickelten die Forscher:innen eine systematische Bewertungsmethode. Im Rahmen der Studie nutzten sie die Software-Engineering-Benchmark "SWE-bench Verified" und das "OpenHands Framework". Dieses Framework simuliert eine interaktive Umgebung, in der die KI-Modelle mit verschiedenen Tools Code bearbeiten und ausführen können.
Dabei wird der gesamte Interaktionsprozess aufgezeichnet, um die Balance zwischen "Denken" und "Handeln" zu analysieren. Sie nutzten Claude 3.5 Sonnet aufgrund des großen Kontextfensters von bis zu 200.000 Token, um rund 4.000 Interaktionsverläufe (Trajektorien) auf typische "Overthinking"-Muster zu analysieren und Punkte von 0 bis 10 zu vergeben.Höhere Werte stehen für stärkeres "Overthinking".
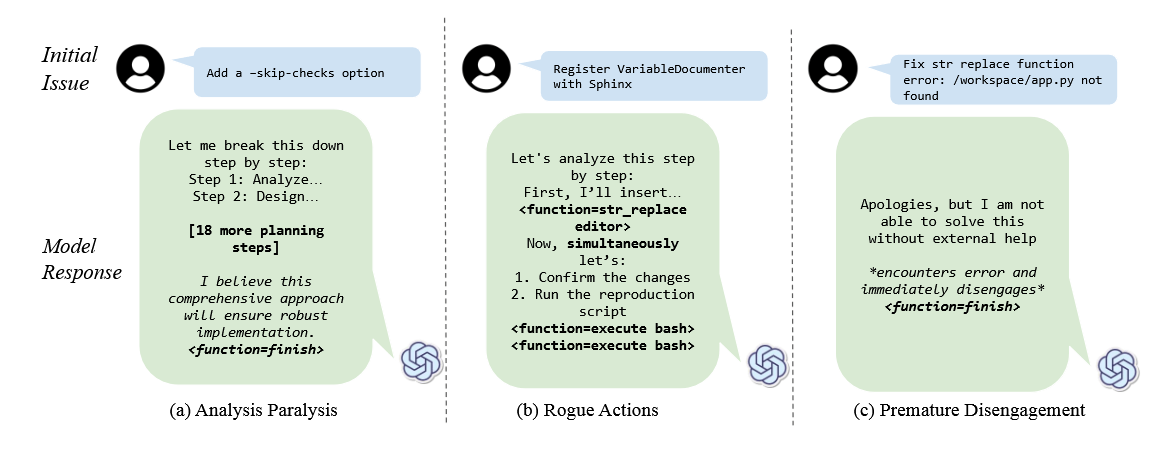
Die Forschenden identifizierten drei Hauptmuster: Analysis Paralysis (Lähmung durch Analyse), bei der die KI in der Planung stecken bleibt; Rogue Actions (ungültige Aktionen), bei der die KI mehrere Aktionen gleichzeitig ausführt und die sequentiellen Anforderungen der Umgebung missachtet; und Premature Disengagement (vorzeitiger Abbruch), bei der die KI die Aufgabe aufgrund interner Simulationen abbricht, ohne die Ergebnisse in der Umgebung zu validieren.
Vor allem die beiden letztgenannten Verhaltensweisen erinnert an das "Underthinking", das bereits andere Forschende in einem kürzlich veröffentlichten Paper Reasoning-Modellen attestierten. Hier ist eher das Gegenteil der Fall: Das KI-Modell bricht Gedankengänge zu früh ab und gibt dadurch schlechtere Antworten.
Auch Sprachmodelle ohne Reasoning können zu viel nachdenken
Die Studie untersuchte 19 verschiedene Sprachmodelle wie OpenAIs o1, Alibabas QwQ oder DeepSeek-R1 in interaktiven Software-Engineering-Aufgaben. Die Ergebnisse zeigen eine starke negative Korrelation zwischen "Overthinking" und der Leistung der Modelle. Interessanterweise zeigen sowohl Reasoning- als auch Non-Reasoning-Modelle wie Claude 3.5 Sonnet oder GPT-4o Overthinking, wobei Reasoning-Modelle deutlich höhere Overthinking-Werte aufweisen.
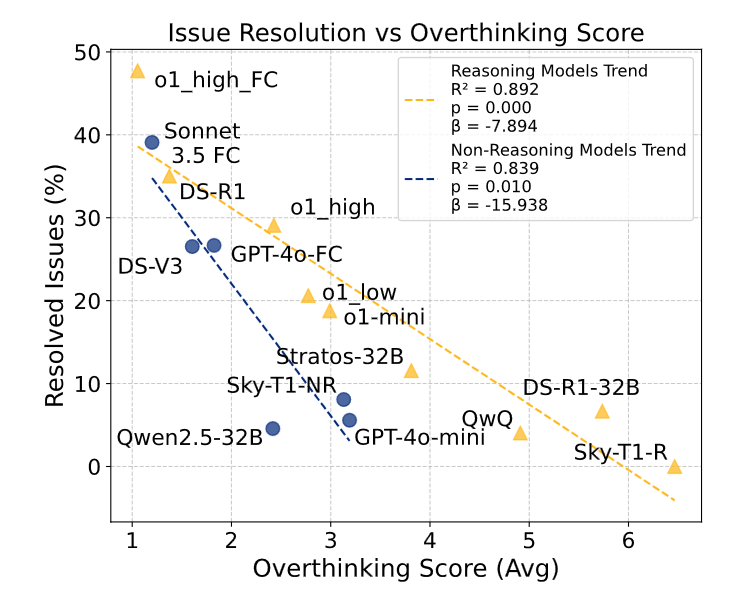
Allerdings führt Overthinking bei Non-Reasoning-Modellen zu einem dramatischeren Leistungsabfall, da diese nicht für das Verarbeiten von langen Denkprozessen trainiert sind.
Auch die Größe des Modells spielt eine Rolle: Kleinere Modelle neigen stärker zu Overthinking, vermutlich weil sie die Komplexität der Umgebung schlechter verarbeiten können und sich daher verstärkt auf interne Simulationen zurückziehen.
Hingegen zeigte sich kein signifikanter Zusammenhang zwischen der Größe des Kontextfensters und dem Overthinking-Verhalten. Die Forscher:innen vermuten, dass Overthinking eher von der Architektur und dem Training des Modells beeinflusst wird als von der Kapazität des Kontextfensters.
Einfache Maßnahmen können "Overthinking" deutlich reduzieren
Die Studie zeigt außerdem, dass bereits einfache Maßnahmen "Overthinking" reduzieren und die Leistung der Modelle verbessern können. So konnte in Experimenten die Lösungsrate für Programmieraufgaben um gut 25 Prozent gesteigert und gleichzeitig die Rechenkosten um 43 Prozent gesenkt werden, indem mehrere Lösungen mit geringem Rechenaufwand generiert und diejenige mit dem niedrigsten Overthinking-Score ausgewählt wurde.
Vielversprechende Ansätze zur grundlegenden Lösung des Problems seien die Integration von "Native Function-Calling", mit dem KI-Modelle direkt mit ihrer Umgebung interagieren können, und selektives Verstärkungslernen. Modelle mit nativem Function-Calling zeigten deutlich weniger Overthinking und eine signifikant bessere Leistung.
Das besonders große Modell DeepSeek-R1-671B zeigte überraschenderweise kein erhöhtes Overthinking, was die Forscher:innen auf das fehlende Reinforcement Learning für Software-Engineering-Aufgaben im Training zurückführen.
Die Forscher:innen stellen ihre Bewertungsmethodik und den erzeugten Datensatz als Open-Source auf GitHub zur Verfügung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.