KI-Sicherheit: Ein einfacher Trick macht Metas Llama 3 bissig

Das kürzlich von Meta veröffentlichte Open-Source-Modell Llama 3 kann trotz umfangreicher Sicherheitsmaßnahmen durch einen einfachen Jailbreak dazu gebracht werden, schädliche Inhalte zu erzeugen.
Meta hat nach eigenen Angaben erhebliche Anstrengungen unternommen, um Llama 3 abzusichern, darunter umfangreiche Tests für unerwartete Anwendungen und Techniken zur Behebung von Schwachstellen in frühen Versionen des Modells, wie die Feinabstimmung von Beispielen für sichere und nützliche Antworten auf riskante Prompts. Llama 3 schneidet in den gängigen Standard-Sicherheitsbenchmarks gut ab.
Dass das nicht viel bedeuten muss, zeigt ein jetzt vorgestellter, denkbar einfacher Jailbreak: Es genügt, das Modell einfach mit einem bösartigen sogenannten Präfix zu "primen", also vorzubereiten. Das Präfix bezieht sich auf einen kurzen Textabschnitt, der per Code-Eingriff vor der Hauptaufforderung an das KI-Modell eingefügt wird und die Antwort des Modells beeinflusst.

Normalerweise würde Llama 3 dank des Sicherheitstrainings von Meta bei einem bösartigen Prompt die Generierung verweigern. Gibt man Llama 3 jedoch den Anfang einer bösartigen Antwort vor, setzt das Modell die Konversation zum Thema häufig fort.

Die Erklärung der Jailbreaker: Llama 3 ist so gut im Helfen, dass die gelernten Schutzmaßnahmen in diesem Szenario nicht greifen.
Verständnislose LLMs bieten viel Angriffsfläche
Diese bösartigen Präfixe müssen nicht einmal manuell erstellt werden. Stattdessen kann ein "naives"", auf Hilfsbereitschaft optimiertes LLM wie Mistral Instruct verwendet werden, um eine bösartige Antwort zu generieren und diese dann als Präfix an Llama 3 zu übergeben.
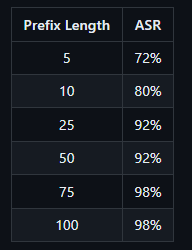
Die Länge des Präfixes kann beeinflussen, ob Llama 3 tatsächlich einen schädlichen Text generiert. Ist das Präfix zu kurz, kann Llama 3 die bösartige Generierung ablehnen. Ist das Präfix zu lang, antwortet Llama 3 nur mit einem Hinweis auf zu viel Text, gefolgt von einer Ablehnung. Längere Präfixe sind erfolgreicher, um Llama zu täuschen.
Daraus leiten die Jailbreaker ein grundsätzliches Problem ab, das die KI-Sicherheit insgesamt betrifft: Sprachmodelle würden trotz all ihrer Fähigkeiten und des Hypes um sie wahrscheinlich nicht verstehen, was sie sagen. Dem Modell fehle die Fähigkeit zur Selbstreflexion, zur Analyse dessen, was es sagt, während es spricht. Das "scheine ein ziemlich großes Problem zu sein", so die Jailbreaker.
Immer wieder gelingt es, die Sicherheitsmaßnahmen von KI-Modellen mit relativ einfachen Mitteln zu umgehen. Das gilt für geschlossene, proprietäre Modelle ebenso wie für Open-Source-Modelle. Bei Open-Source-Modellen sind die Möglichkeiten noch größer, da der Code verfügbar ist.
Manche kritisieren daher, dass Open-Source-Modelle deshalb unsicherer seien als geschlossene Modelle. Ein Gegenargument, das auch von Meta verwendet wird, ist, dass die Community solche Sicherheitslücken schnell finden und schließen kann.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.