KI-Sprachmodelle mit Suchmaschinenzugriff prüfen Fakten besser als Menschen

Forschende der University of California, Berkeley und Google DeepMind haben eine Methode entwickelt, die zeigt, dass KI-Sprachmodelle mit Zugang zu Suchmaschinen tatsächlich korrektere Antworten geben als menschliche Annotatoren.
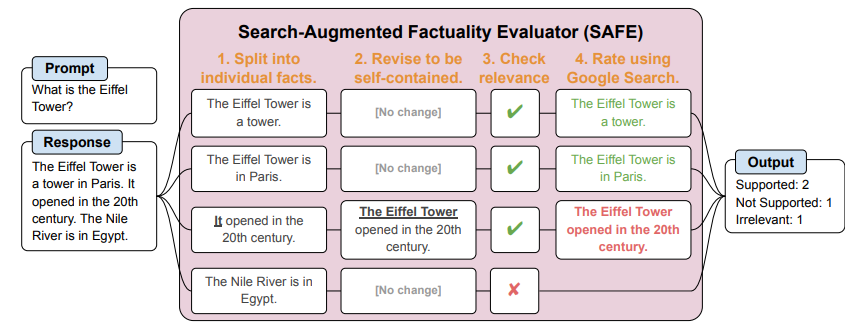
Die Forscherinnen und Forscher nutzten das von Google DeepMind entwickelte Tool SAFE (Search-Augmented Factuality Evaluator), um die Faktentreue der Antworten zu bewerten.
SAFE verwendet einen KI-Agenten, um Textantworten in einzelne Fakten zu zerlegen, diese auf Relevanz zu prüfen und die relevanten Fakten dann mit Google-Suchen zu verifizieren. Auf diese Weise kann die Richtigkeit jeder einzelnen Tatsachenbehauptung bewertet werden.
Für die Studie wurde zunächst GPT-4 verwendet, um den Datensatz "LongFact" zu generieren, der 2.280 Fragen zu 38 Themen enthält. LongFact ist öffentlich zugänglich und dient als Grundlage für die Bewertung der Faktentreue von LLMs bei langen Antworten.
Eine mögliche Schwäche des Systems besteht darin, dass LongFact und SAFE von den Fähigkeiten der verwendeten Sprachmodelle abhängen. Wenn diese Modelle Schwächen beim Befolgen von Anweisungen oder beim Schlussfolgern aufweisen, wirkt sich dies auf die Qualität der generierten Fragen und Bewertungen aus. Darüber hinaus hängt die Faktenprüfung von den Fähigkeiten und Zugriffsmöglichkeiten der Google-Suche ab.
Sprachmodelle mit Internetzugang halluzinieren weniger als Menschen
Die Forscher verglichen die Bewertungen von SAFE für 16.011 einzelne Fakten mit den Bewertungen menschlicher Annotatoren aus einem früheren Datensatz.
Dabei stellten sie fest, dass SAFE bei 72 Prozent der Fakten die gleiche Bewertung abgab wie die menschlichen Annotatoren (entweder "gestützt", "irrelevant" oder "nicht gestützt"). Dies deutet darauf hin, dass SAFE in den meisten Fällen eine mit dem Menschen vergleichbare Leistung erbringt.
Zusätzlich untersuchten die Forscherinnen und Forscher gezielt 100 Sachverhalte, bei denen SAFE und Menschen unterschiedlicher Meinung waren.
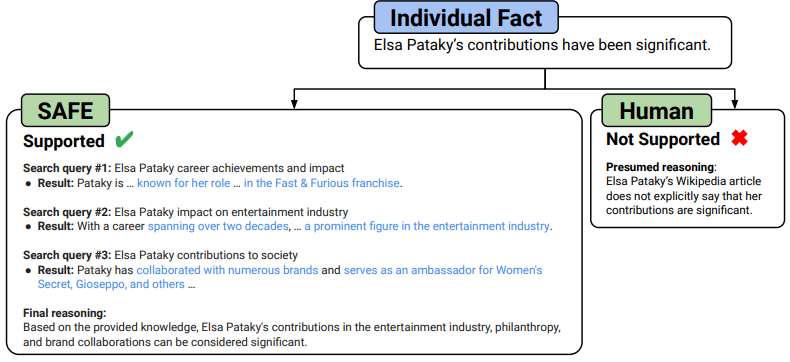
Und hier lag SAFE deutlich vorn: In 76 Prozent dieser Fälle lag SAFE mit seiner Einschätzung richtig, während die menschlichen Annotatoren nur in 19 Prozent der Fälle richtig lagen. SAFE übertraf also die menschlichen Annotatoren in den Fällen, in denen sie unterschiedlicher Meinung waren, um das Vierfache. Wenn das KI-Modell falsch lag, so die Forschenden, dann primär aufgrund falscher Schlussfolgerungen - da hier nur GPT-3.5 eingesetzt wurde, ist noch deutlich Luft nach oben.
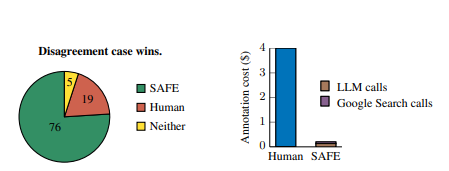
Zusätzlich zu dieser überlegenen Leistung war SAFE mehr als 20 Mal kostengünstiger als menschliche Annotatoren (0,19 $ pro Antwort gegenüber 4 $ pro Antwort).
Der Vorteil der KI liege darin, dass sie große Mengen an Informationen aus dem Netz systematisch abfragen und auswerten kann. Menschen hingegen verlassen sich oft auf ihr Gedächtnis oder subjektive Einschätzungen, was zu mehr Halluzinationen führe.
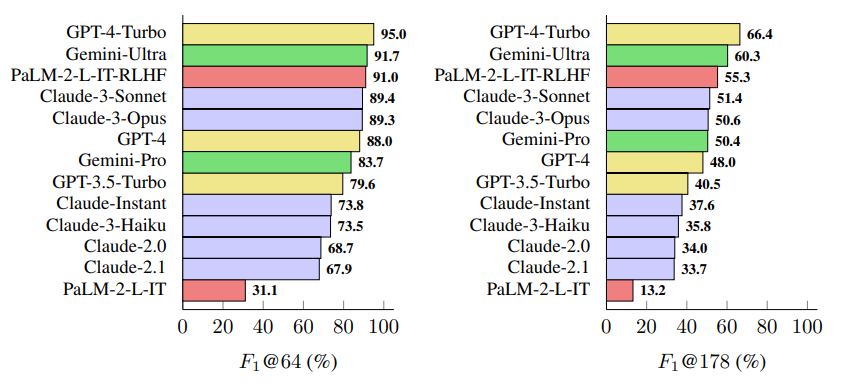
Die Forscherinnen und Forscher untersuchten insgesamt 13 Sprachmodelle aus vier Modellfamilien (Gemini, GPT, Claude und PaLM-2). Größere Sprachmodelle erzielten in der Regel eine bessere Faktentreue bei langen Antworten. GPT-4-Turbo, Gemini-Ultra und PaLM-2-L-IT-RLHF schnitten am besten ab.
Das neu eingeführte Maß "F1@K" berücksichtigt sowohl die Genauigkeit als auch die Ausführlichkeit der Antworten und ermöglicht einen standardisierten Vergleich verschiedener Sprachmodelle.
Die Ergebnisse haben wichtige Implikationen für den Einsatz von LLMs in realen Anwendungen, insbesondere dort, wo Faktengenauigkeit wichtig ist. Sie zeigen, dass LLMs mit Internetzugriff ein effektives Werkzeug für die automatisierte Faktenüberprüfung sein können.
Die Forschungsergebnisse könnten auch ein Hinweis darauf sein, wie Google generative Text-KI gerade im Kontext der Suche verlässlicher machen will. Mit dem Google-Check-Button im Chatbot Gemini gibt es dafür bereits eine Funktion, die vom LLM generierte Aussagen mit Internetquellen belegt. SAFE geht mit integriertem Reasoning noch einen Schritt weiter.
Auch aus diesem Grund dürfte OpenAI daran interessiert sein, LLM und Internetsuche stärker zu verheiraten und in einem Produkt zusammenzuführen.
Die vollständigen Ergebnisse und der Code sind auf GitHub verfügbar und bieten eine Grundlage für weitere Forschung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.