KI-Sprachmodelle scheitern an einfachen visuellen Rätseln
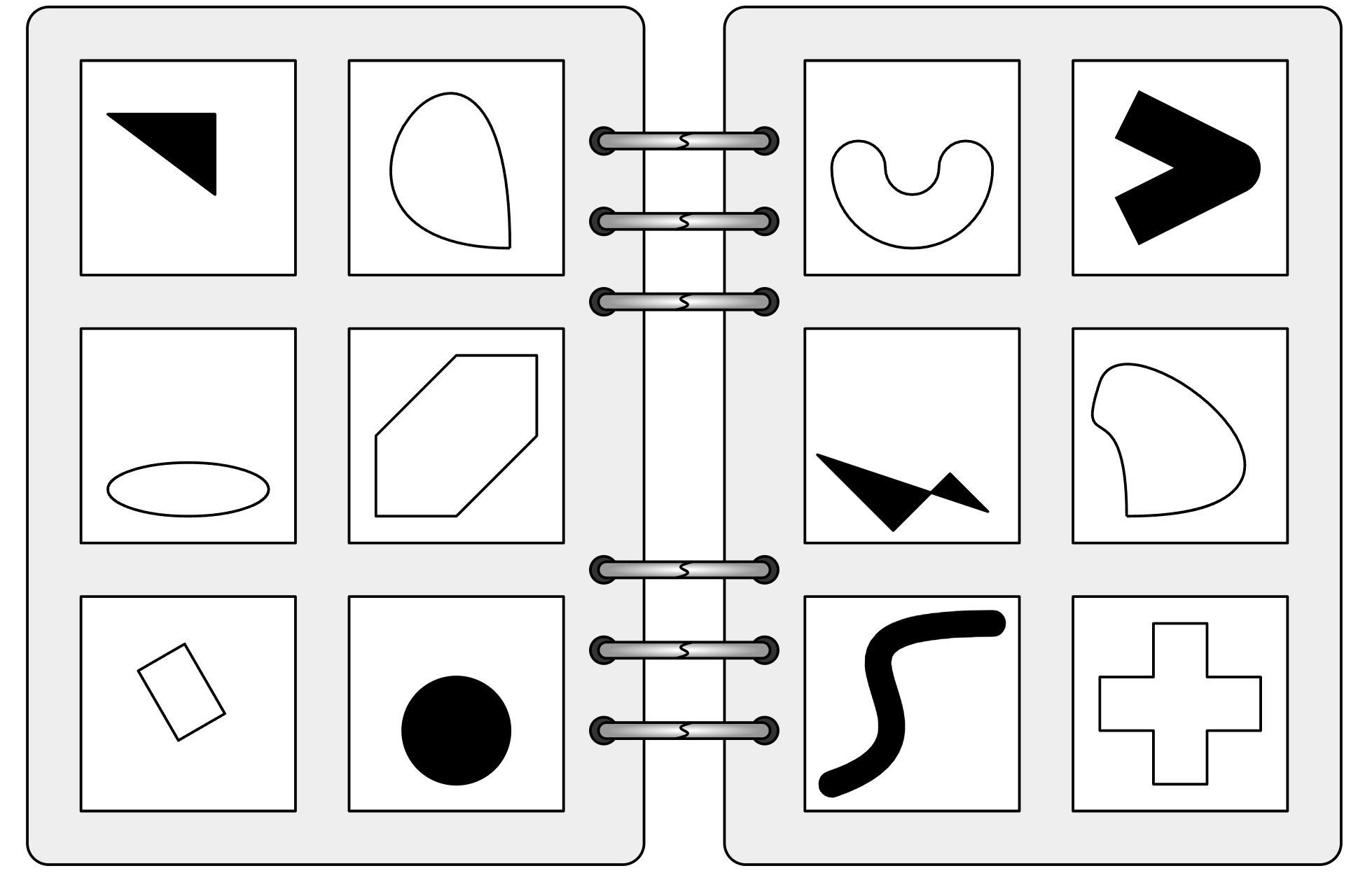
Selbst die fortschrittlichsten KI-Bildmodelle scheitern an grundlegenden Aufgaben des visuellen Schlussfolgerns. Das zeigt eine aktuelle Studie der TU Darmstadt, in der verschiedene Vision Language Models (VLMs) mit sogenannten Bongard-Problemen konfrontiert wurden.
Die nach dem russischen Wissenschaftler Michail Bongard benannten Probleme bestehen aus zwölf einfachen Bildern in zwei Gruppen. Die Aufgabe besteht darin, die Regel zu finden, nach der sich die beiden Gruppen unterscheiden - eine Fähigkeit, die Menschen in der Regel intuitiv beherrschen. Die Rätsel testen das Abstraktionsvermögen.
Menschliche Fähigkeiten gefordert
Viele der Aufgaben sind für Menschen relativ einfach zu lösen - KI-Systeme scheitern dagegen selbst an einfachen Beispielen. Nach Angaben der Forschenden konnte selbst das beste getestete Modell, GPT-4, nur 21 von 100 dieser visuellen Rätsel lösen. Andere bekannte Modelle wie Claude, Gemini und LLaVA schnitten noch schlechter ab.
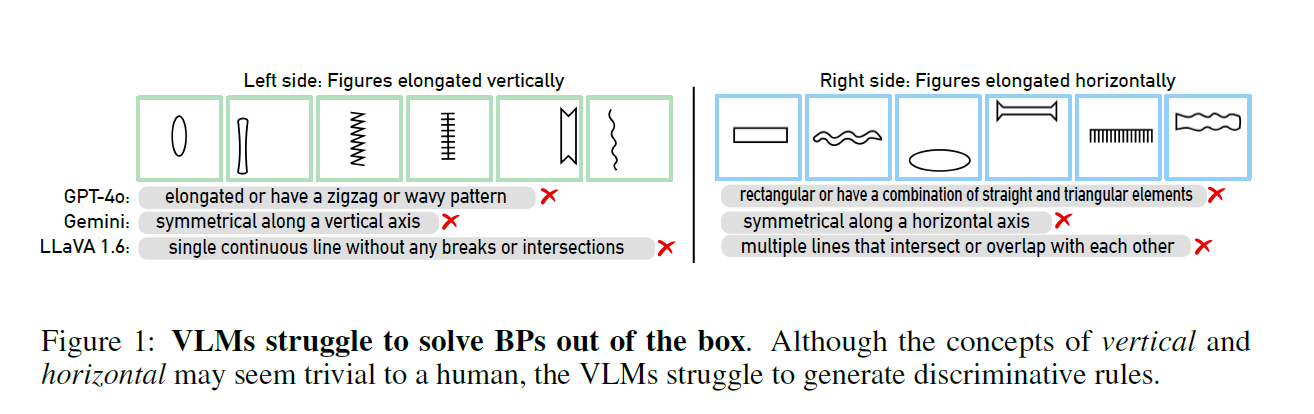
Die Studie zeigt, dass KI-Systeme selbst an elementaren Aufgaben scheitern. Sei es die Drehrichtung einer Spirale oder die Unterscheidung von waagerechten und senkrechten Linien - die Modelle haben erhebliche Probleme bei der Lösung.
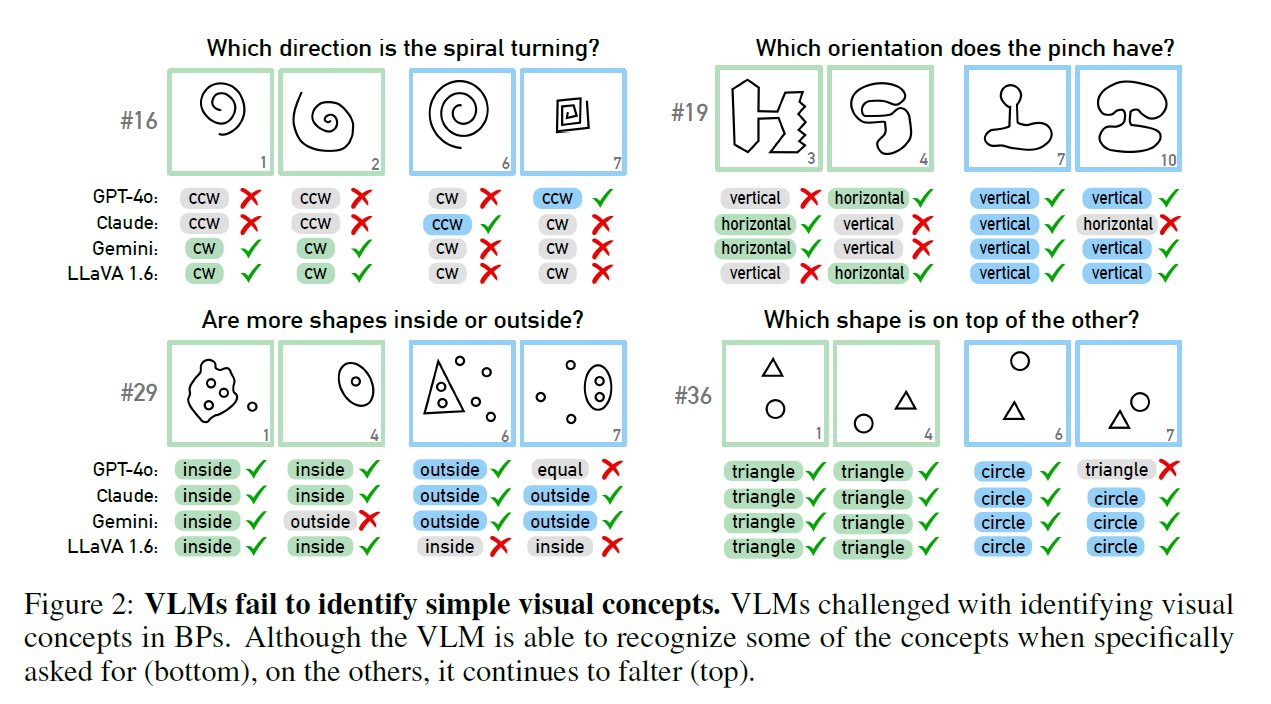
Auch wenn die Forschenden den KI-Modellen Auswahlmöglichkeiten für die richtigen Antworten gaben, verbesserten sich die Ergebnisse nur geringfügig. Erst als die Anzahl der möglichen Antworten stark eingeschränkt wurde, stieg die Erfolgsquote deutlich an - GPT-4 und Claude lösten dann immerhin 68 beziehungsweise 69 von 100 Aufgaben.

Auch die Gründe für das Scheitern der Modelle haben die Wissenschaftler detailliert untersucht. Bei vier ausgewählten Problemstellungen zeigte sich, dass KI-Systeme manchmal schon bei der grundlegenden visuellen Wahrnehmung scheitern, noch bevor sie zum eigentlichen Denken und Schlussfolgern kommen. Eine eindeutige Ursache konnte jedoch nicht gefunden werden.
Große Lücke zwischen Mensch und Maschine
Die Ergebnisse zeigen laut den Forscherinnen und Forschern, dass zwischen menschlicher und maschineller visueller Intelligenz noch eine große Lücke klafft. Die Untersuchungen zeigten, dass aktuelle KI-Modelle trotz ihrer beeindruckenden Leistungen in anderen visuellen Benchmarks noch weit davon entfernt sind, visuelle Konzepte wirklich zu verstehen, heißt es in der Studie.
Die Ergebnisse werfen auch Fragen zur Bewertung von KI-Systemen auf. Das Forschungsteam empfiehlt, bestehende Benchmarks zu überdenken und zu hinterfragen, ob sie tatsächlich die tatsächlichen logischen Fähigkeiten der Modelle messen.
Die Studie wurde von der Technischen Universität Darmstadt in Zusammenarbeit mit der Eindhoven University of Technology und dem Deutschen Forschungszentrum für Künstliche Intelligenz (DFKI) durchgeführt. Sie wurde unter anderem vom Bundesministerium für Bildung und Forschung und der Europäischen Union gefördert.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.