Das inhaltliche Verständnis für Sprache und Text gilt als Schwachpunkt Künstlicher Intelligenz. Eine neue Methode könnte diese Hürde nach und nach überwinden.
KI-gestützte Bilderkennung ist Teil unseres Alltags: Facebook erkennt Personen auf Fotos, Überwachungskameras scannen U-Bahn-Passagiere und selbstfahrende Autos finden sich testweise auf den Straßen.
Es gibt verschiedene Bewertungsverfahren für das Leistungsvermögen einer Bildanalyse-KI. Die „ImageNet Large Scale Visual Recognition Challenge“ (ILSVRC) ist eines von ihnen. Es gründet auf dem ImageNet-Datensatz, den die bekannte KI-Forscherin Fei-Fei Li 2009 zusammenstellte, Googles aktuelle und bald ehemalige KI-Chefin.
Ihre Idee: Selbst das beste neuronale Netzwerk taugt nichts, wenn die für das Training verwendeten Daten nichts mit der Realität zu tun haben.
Seit der ImageNet-Test existiert, versuchen Forscher Jahr für Jahr mit ihrem KI-System neue Bestmarken zu erreichen. Der Wendepunkt für Bildanalyse-KIs kam 2012, als Forscher ein Deep Learning Netzwerk (DNN) trainierten, das die ImageNet-Herausforderung 41 Prozent besser bestand als alle konkurrierenden Verfahren.
Der Erfolg dieses Netzwerks lag in seinem mehrschichtigen Aufbau begründet. Jede Schicht analysierte einzelne Pixelgruppen, also letztlich Bildinformationen: So erkannte es Ränder, Texturen und Muster bis hin zu Objekten.

Mit ImageNet vortrainierte Bilderkennungsmodelle werden seitdem häufig als Grundlage für spezialisierte KI-Aufgaben genutzt. Viele Modelle sind frei im Internet verfügbar und können nach dem Download durch entsprechende Trainingsdaten an eine neue Aufgabe angepasst werden, beispielsweise für die Gesichtserkennung.
Sprachsteuerung ist ungleich Sprachverständnis
Komplexer als die Bildanalyse ist es, einer Künstlichen Intelligenz ein Verständnis für Sprache beizubringen. Im Fachjargon heißt das „Natural Language Processing“ – oder kurz: NLP.
Zwar können virtuelle Assistenten wie Amazons Alexa oder Googles Assistant auf Sprachbefehle reagieren. Aber sie übersetzen nur Sprache in Klangdaten. Sie erfassen nicht den eigentlichen Inhalt einer Aussage.

Dieses Defizit fällt auf, wenn man einen Wunsch äußert, der noch nicht in der Klangdatenbank hinterlegt ist. Hätte die KI ein grundlegendes Verständnis für Sprache, könnte sie sich den Inhalt der Aussage womöglich herleiten – oder durch gezieltes Nachfragen einen Anhaltspunkt finden.
Das langfristige Ziel von NLP-KIs ist eben diese Fähigkeit: Künstliche Intelligenz soll den Inhalt von Sätzen oder eines Textes erfassen können, indem sie ein Verständnis der Regelmäßigkeiten einer Sprache entwickelt. Sie soll Fragen frei beantworten, logische Zusammenhänge zwischen Einzelaussagen erkennen, sinngemäß übersetzen und Sätze zu Ende führen können.
Sprachmodelle hängen zurück
Die meisten aktuellen Ansätze nutzen dafür – ähnlich der Bilderkennungsmodelle - vorbereitete Daten, sogenanntes überwachtes Lernen. Das schränkt sie in ihrem Umfang ein, denn das Vorbereiten der Trainingsdaten ist aufwendig und muss noch dazu für jede Sprache einzeln passieren.
Umfangreiche, vorbereitete Datensätze in der Qualität eines ImageNet existieren nicht. Da Sprache sehr komplex ist, können solche Datensätze die Vielfalt der Ausdrucksmöglichkeiten nicht vollständig erfassen.
Bisherige NPL-KIs sind außerdem nicht mehrstufig aufgebaut wie ihre Bildanalyse-Verwandtschaft. Sie nutzen lediglich sogenannte „Word Embeddings": Jedes Wort in einem Text wird in einem mehrdimensionalen Raum einem Vektor zugeordnet.
Wörter, die häufig in vergleichbaren Kontexten erscheinen, werden ähnlichen Vektoren zugewiesen. Am Ende repräsentiert so jeder Wortvektor ansatzweise die Bedeutung des Wortes im Kontext der Trainingsdaten.
Auf eine Bildanalyse-KI übertragen hieße das: Es gibt nur eine Schicht und die erkennt nur Ränder. Komplexere Informationen gehen verloren.
Solche Modelle benötigen wesentlich mehr Beispiele – also mehr Trainingsdaten - um mit mehrschichtigen Modellen vergleichbare Ergebnisse zu erzielen. Hier dreht sich die Methode im Kreis, denn wie oben erwähnt, ist die Bereitstellung vieler Daten mit hohem Aufwand verbunden.
Neue Ansätze könnten flüssige KI-Gespräche ermöglichen
KI-Sprachforscher haben sich daher in den letzten Jahren vermehrt dem unüberwachten Lernen zugewandt. Eine NLP-KI, die mit unvorbereiteten Texten trainiert wird, kann ihre Datensätze durch das Internet vervielfachen. Die aufwendige Vorbereitung der Texte entfällt und der Zugang zu einer großen, vielsprachigen Datenmenge ist gesichert.
Eines der vielversprechendsten Modelle ist das "Embeddings from Language Models" (ELMo). ELMo ist Teil einer neuen Generation von NLP-KIs, die sowohl unvorbereitete Datensätze verarbeiten können, als auch mehrstufig aufgebaut sind.
ELMo ist in der Lage, große Mengen unvorbereiteter Texte zu analysieren. Darauf aufbauend entwickelt das Modell ein Verständnis von Syntax und Semantik: Die NLP-KI kann Präfix und Suffix unterscheiden oder Homonyme wie „Bank“ im jeweiligen Kontext richtig zuordnen.
Die Einführung dieses Modells hat bei einigen NLP-Bewertungsverfahren zu einer Qualitätssteigerung von bis zu 25 Prozent geführt. In einem Forschungsfeld, in dem es seit Jahren kaum Fortschritte gibt, ist das ein großer Sprung.
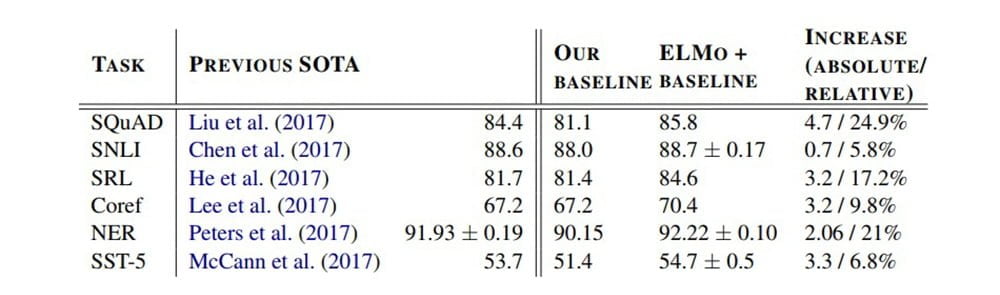
Einer der an ELMo beteiligten Forscher spricht daher von einem „ImageNet-Moment“: ELMo könnte für eine ähnliche Beschleunigung der NLP-Entwicklung sorgen, wie es 2012 dem Gewinner der ImageNet-Herausforderung für die Deep-Learning-Bildanalyse gelang.
Experten sagen KI-Siegeszug in den nächsten 50 Jahren voraus
Die vortrainierten Sprachmodelle könnten zum Ausgangspunkt für viele NLP-Projekte werden. Sie können weiter spezialisiert werden und verschiedene Aufgaben übernehmen: Wissenschaftliche Artikel zusammenzufassen, Emails verlässlicher als Spam oder Betrugsversuch erkennen oder eine Kurzgeschichte zu Ende erzählen.
Experteneinschätzungen zufolge wird Künstliche Intelligenz den Menschen in den nächsten zehn Jahren bei vielen Tätigkeiten übertreffen. Menschliche Übersetzer sollen beispielsweise schon ab circa 2024 überflüssig sein. NLP-KIs sollen ab 2026 Aufsätze für die gymnasiale Oberstufe und einen Bestseller ab 2049 schreiben können.
Einen Truck steuert Künstliche Intelligenz ab 2027, im Einzelhandel macht sie ab 2031 Vertrieb – manifestiert in einem Roboter. Ab 2053 sollen Roboter die Chirurgie vollständig übernehmen.
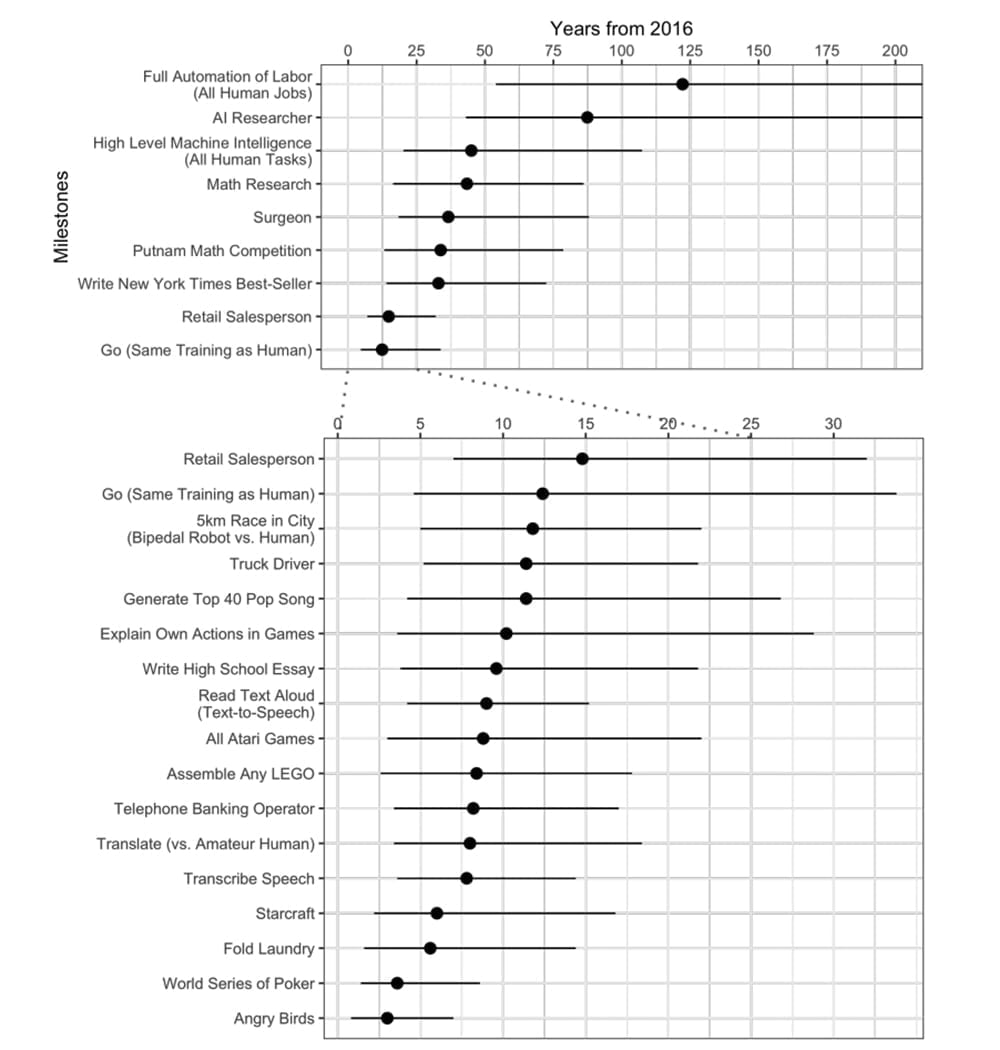
Die Forscher sehen eine 50-prozentige Wahrscheinlichkeit, dass KI den Menschen schon in 45 Jahren bei allen Aufgaben übertreffen wird. Dies würde zu einer Automatisierung aller menschlichen Jobs in 120 Jahren führen. Forscher aus Asien erwarten diese Veränderung im Schnitt 44 Jahre früher als nordamerikanische Forscher.

ELMos Zukunft ist ungewiss
Ob ELMo die Lösung für alle NLP-Probleme ist, kann niemand vorhersehen. Die Möglichkeiten und Grenzen des neuen Ansatzes sind noch nicht absehbar: Aufgrund der undurchsichtigen Struktur geschichteter neuronaler Netze ist es schwer festzustellen, was das Modell tatsächlich lernt und versteht.
Die menschliche Sprache ist so komplex, dass es wohl noch einige Jahre dauern wird, bis eine KI so spricht und schreibt, wie wir es tun – wenn es überhaupt gelingt.
Doch ELMo könnte der Beginn einer neuen Zeitrechnung für das Sprachvermögen Künstlicher Intelligenz sein. Erst kürzlich stellte Facebook eine neue Übersetzungs-KI vor, die wie ELMo auf unüberwachtes Lernen setzt.



