KI-Suchmaschinen scheitern bei der korrekten Quellenangabe von Nachrichteninhalten

Eine aktuelle Studie zeigt, dass acht führende KI-Suchmaschinen Schwierigkeiten haben, Nachrichteninhalte korrekt zu zitieren. Trotz Lizenzvereinbarungen mit Verlagen werden Quellen oft falsch oder unvollständig angegeben.
KI-Suchmaschinen gewinnen rasant an Popularität: Fast jede:r vierte Amerikaner:in hat bereits eine KI-Suchmaschine anstelle traditioneller Suchmaschinen genutzt. Doch eine neue Studie des Tow Center for Digital Journalism an der Columbia University zeigt erhebliche Mängel bei der Quellenangabe von Nachrichteninhalten auf.
Die Forschenden testeten acht KI-Suchmaschinen mit Live-Suchfunktion, darunter ChatGPT, Perplexity und Google Gemini. Dazu wählten sie zufällig Artikel von 20 Nachrichtenverlagen aus und gaben Textausschnitte daraus in die Suchmaschinen ein. Die Chatbots sollten dann Überschrift, Quelle, Erscheinungsdatum und URL des jeweiligen Artikels nennen.
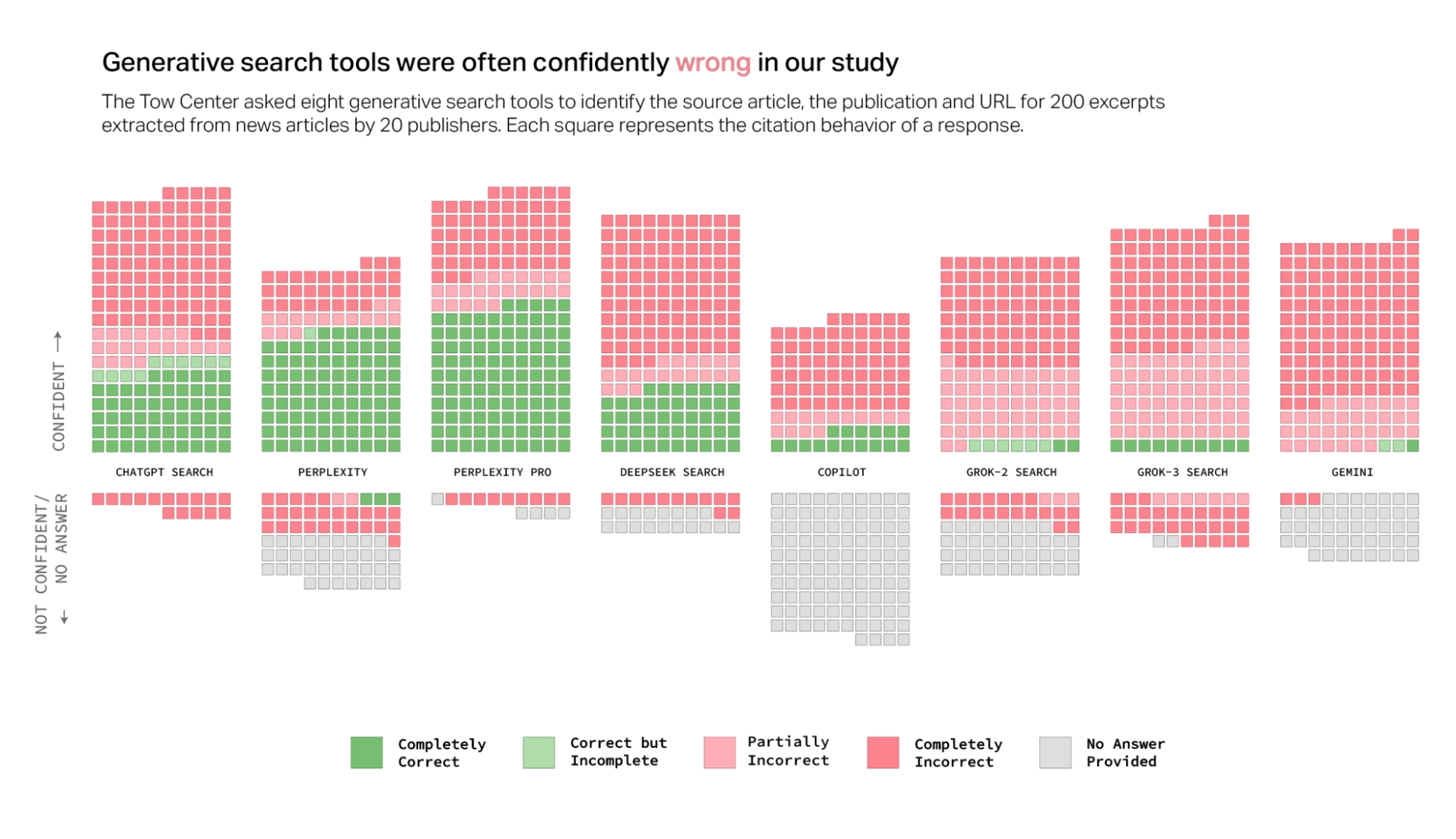
Das ernüchternde Ergebnis: Insgesamt beantworteten die Suchmaschinen über 60 Prozent der Anfragen falsch. Perplexity schnitt mit 37 Prozent falscher Antworten noch am besten ab, Grok 3 lag mit 94 Prozent Fehlerquote am unteren Ende.
Bezahlmodelle sind nicht zuverlässiger als kostenlose Angebote
Überraschenderweise schnitten kostenpflichtige Premiummodelle wie Perplexity Pro oder Grok 3 nicht besser, sondern sogar schlechter ab als ihre kostenlosen Pendants.
Zwar beantworteten sie insgesamt mehr Anfragen korrekt, gaben aber paradoxerweise auch häufiger falsche Antworten anstatt zuzugeben, wenn sie die Antwort nicht wussten.
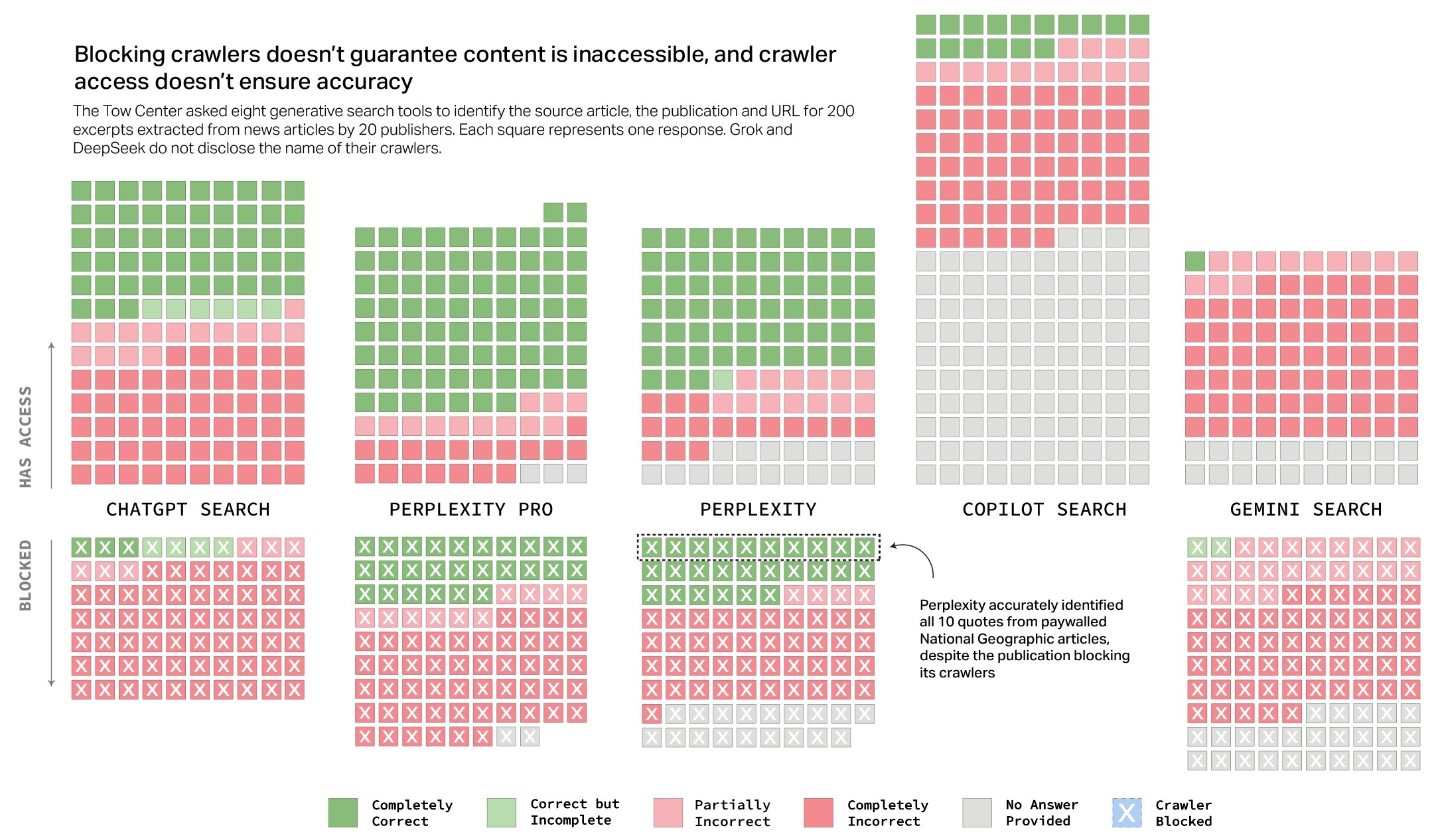
Mehrere Chatbots schienen zudem die Einstellungen im Robots Exclusion Protocol zu missachten, mit denen Verlage den Zugriff auf ihre Inhalte steuern können. So griff etwa Perplexity auf Inhalte von National Geographic zu, obwohl der Verlag die Crawler von Perplexity eigentlich blockiert.
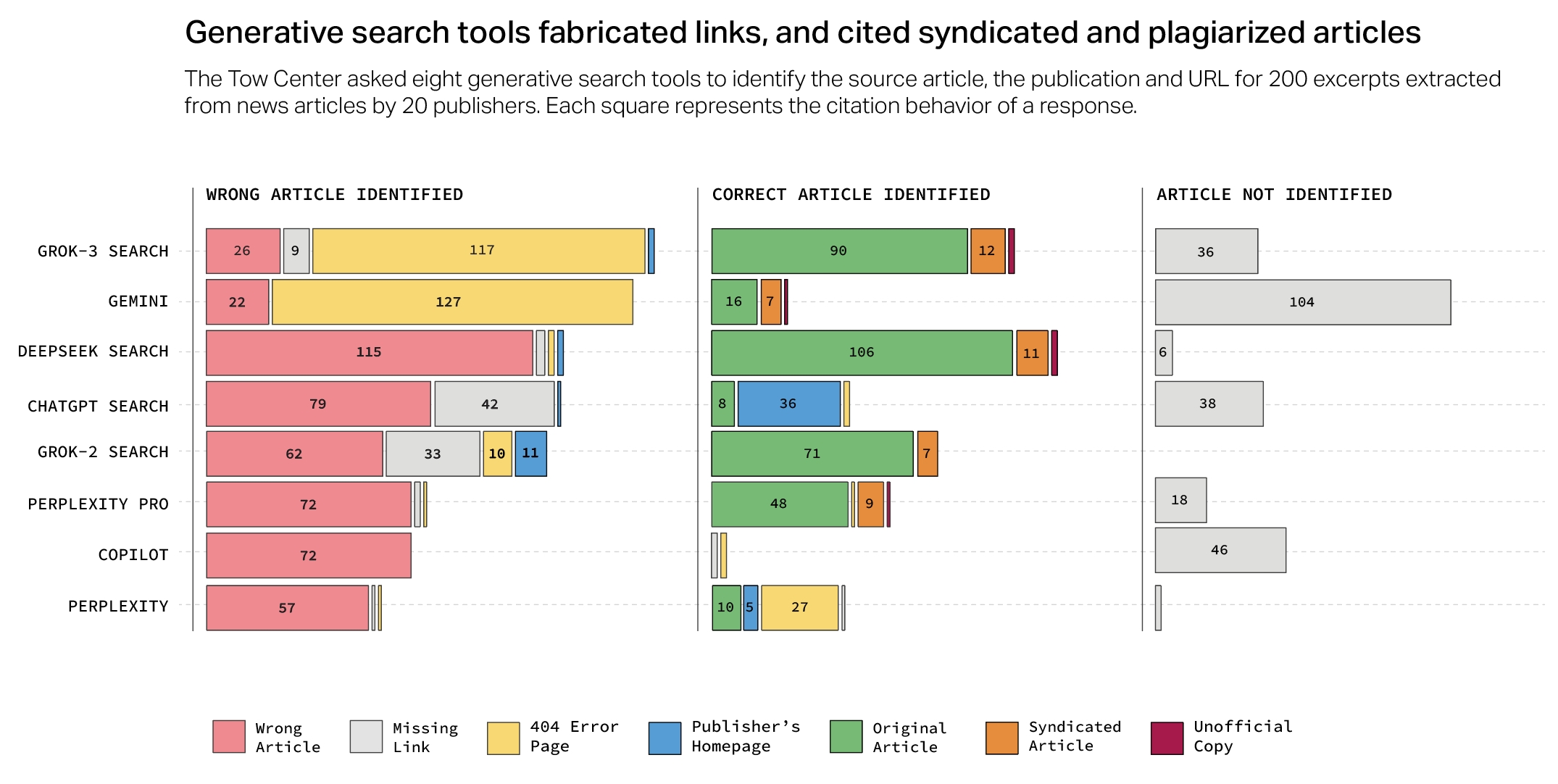
Oft leiteten die KI-Suchmaschinen Nutzer auch auf Syndikations-Plattformen wie Yahoo News weiter anstatt auf die Originalquelle. Oder sie erfanden schlicht URLs, die ins Leere führten - bei Grok 3 und Google Gemini war das in über der Hälfte der Fälle so.
Lizenzdeals bieten keine Garantie für korrekte Zitate
Einige Verlage wie Hearst oder die Texas Tribune haben Lizenzvereinbarungen mit KI-Firmen wie OpenAI oder Perplexity geschlossen. Doch auch das führte nicht dazu, dass ihre Inhalte zuverlässiger zitiert wurden.

So erkannte ChatGPT trotz der Partnerschaft von Hearst mit OpenAI nur einen von zehn getesteten Artikeln der San Francisco Chronicle korrekt. Und Perplexity verwies in mehreren Fällen auf syndizierte statt auf Originalversionen von Artikeln der Texas Tribune.
Die Ergebnisse zeigen, dass KI-Suchmaschinen noch einen langen Weg vor sich haben, um Nachrichteninhalte zuverlässig und transparent zu zitieren. Für Nachrichtenverlage bedeutet das eine Gratwanderung zwischen Sichtbarkeit und Kontrolle über ihre Inhalte.
Laut Mark Howard, COO des Time Magazine, arbeiten die KI-Firmen zwar an Verbesserungen. Doch er betont auch: "Wenn jemand als Verbraucher im Moment glaubt, dass eines dieser kostenlosen Produkte zu 100 Prozent genau ist, dann ist das seine eigene Schuld."
Auch eine Studie der BBC kam Mitte Februar zu dem Ergebnis, dass KI-Assistenten bei Nachrichtenfragen viele Fehler machen. Zu den häufigsten Problemen gehörten falsche Fakten, unzureichende Quellenangaben und fehlender Kontext.
Perplexity wächst schnell - zu schnell?
Vor kurzem zeigte sich, dass Perplexity ein rasantes Wachstum hinlegt. Im Juni 2024 beantwortete die Suchmaschine rund 250 Millionen Fragen - fast so viele wie im gesamten Jahr 2023. An Google mit 8,5 Milliarden Suchanfragen pro Tag kommt Perplexity aber bei weitem nicht heran.
Perplexity führte kürzlich eine Deep-Research-Funktion ein, mit der die KI eigenständig umfangreiche Recherchen durchführt und in wenigen Minuten Berichte erstellt. Der Dienst kostet 20 Dollar im Monat für 500 Anfragen pro Tag. Zum Vergleich: Bei OpenAI zahlt man 200 Dollar für 100 Anfragen.
Eine große Herausforderung bleibt, dass bisher kein Anbieter das grundlegende Problem falscher Antworten gelöst hat. Perplexity stand zudem in der Kritik, weil es für sein "Perplexity Pages"-Feature Inhalte von Medien wie Forbes oder Bloomberg kopierte, ohne die Quellen korrekt anzugeben.
Mit dem im Juli 2024 vorgestellten "Perplexity Publishers Program" will das Unternehmen nun enger mit ausgewählten Verlagen zusammenarbeiten, ihre Inhalte in den Suchergebnissen prominenter platzieren und die Verlage an den Werbeeinnahmen beteiligen. Das scheint die bestehenden Probleme jedoch nicht zu lösen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.