KI wird zum Speedrunner, indem sie die Spielanleitung liest

Mithilfe einer Spielanleitung lernte eine KI ein altes Atari-Spiel mehrere tausendmal schneller als mit älteren Methoden. Der Ansatz könnte auch in anderen Bereichen nützlich sein.
Im März 2020 stellten Wissenschaftler:innen von DeepMind Agent57 vor, das erste mit Deep Reinforcement Learning (RL) trainierte Modell, das in allen 57 Atari-2600-Spielen besser abschnitt als Menschen.
Der Trainingsprozess erwies sich jedoch als sehr langwierig und aufwändig: Für das als besonders schwierig geltende Atari-Spiel Skiing, bei dem der KI-Agent auf einer Skipiste Bäumen ausweichen muss, benötigte Agent57 ganze 80 Milliarden Trainingsbilder - bei 30 Bildern pro Sekunde wären das für einen Menschen knapp 85 Jahre.
KI lernt Spiel 6.000 Mal schneller
Forschende der Carnegie Mellon University, der Ariel University und Microsoft Research zeigen in einem neuen Paper mit dem Titel "Read and Reap the Rewards", wie sich diese Trainingszeit auf bis zu 13 Millionen Bilder - oder fünf Tage - reduzieren lässt.
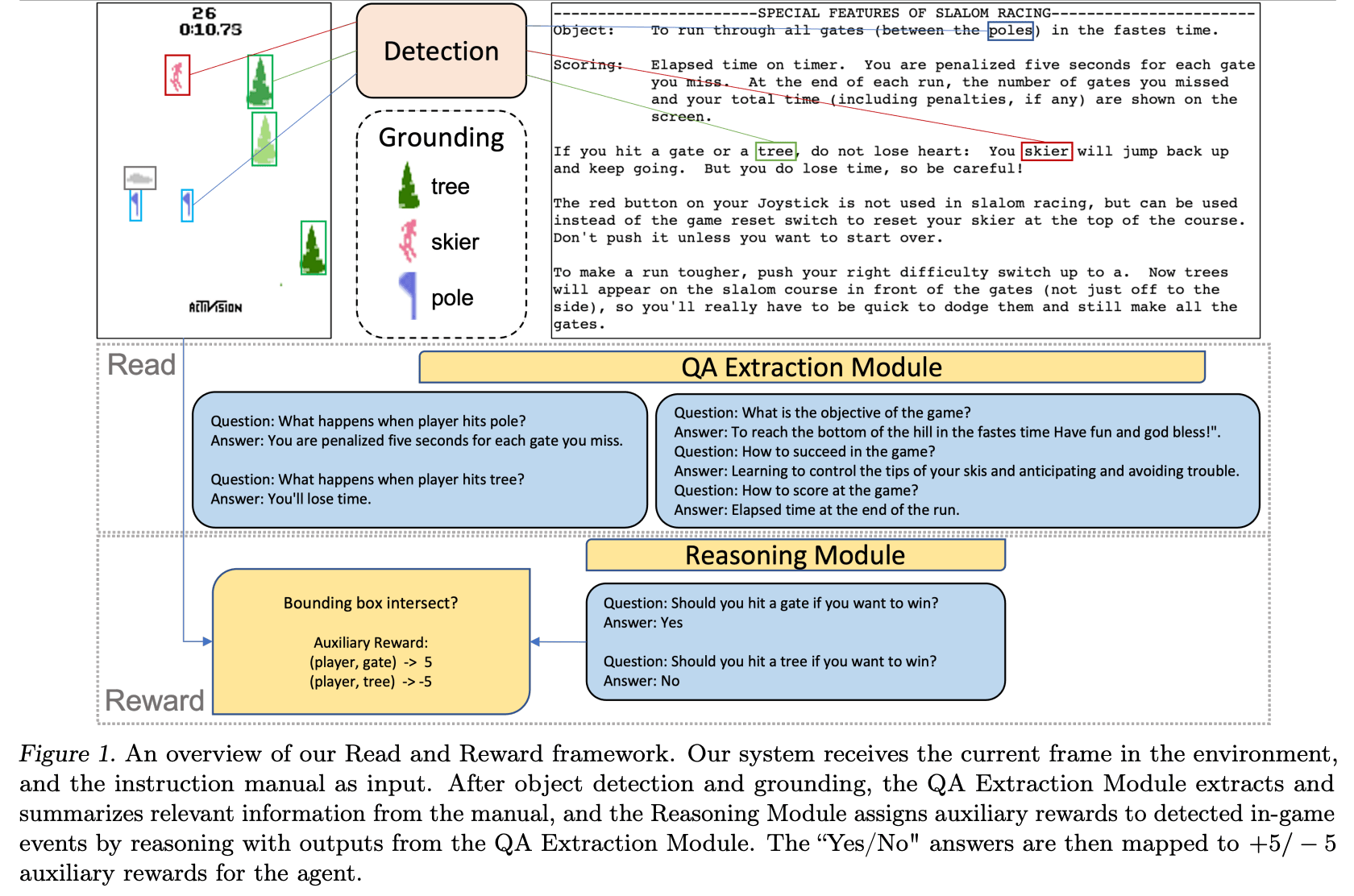
Das "Read and Reward Framework" verwendet dazu von Menschen geschriebene Spielanleitungen als Informationsquelle für den KI-Agenten. Nach Angaben des Teams erwies sich der Ansatz als vielversprechend und konnte die Leistung von RL-Algorithmen auf Atari-Spielen deutlich verbessern.
Informationen extrahieren, Schlussfolgerungen anstellen
Als Herausforderung beschreiben die Forschenden die Länge der Anleitungen, die oft redundant formuliert sind. Zudem seien viele wichtige Informationen in den Anleitungen oft nur implizit enthalten und ergäben nur dann einen Sinn, wenn sie mit dem Spiel in Verbindung gebracht werden könnten. Ein KI-Agent, der Anleitungen verwendet, muss daher in der Lage sein, den Text zu verarbeiten und logische Schlussfolgerungen zu ziehen.
Das Framework besteht daher aus zwei Hauptkomponenten: dem QA-Extraction-Modul und dem Reasoning-Modul. Das QA-Extraction-Modul extrahiert und gruppiert relevante Informationen aus den Instruktionen, indem es Fragen stellt und Antworten aus den Texten extrahiert. Das Reasoning-Modul bewertet dann die Objekt-Agenten-Interaktionen auf Basis dieser Informationen und vergibt Hilfsbelohnungen für erkannte Ereignisse im Spiel.
Diese Hilfsbelohnungen werden dann an einen A2C-RL-Agenten (Advantage Actor Critic) weitergegeben, der so seine Leistung in vier Spielen in der Atari-Umgebung mit spärlichen Belohnungen verbessern konnte. Solche Spiele erfordern oft komplexe Verhaltensweisen, bis der Spielende belohnt wird - die Belohnungen sind daher "spärlich" und ein RL-Agent, der nur nach Versuch und Irrtum vorgeht, erhält so kein gutes Lernsignal.
Auch außerhalb von Atari praktisch?
Durch die Verwendung der Anleitungen lasse sich die Zahl benötigter Trainingsframes um den Faktor 1.000 reduzieren, schreiben die Autor:innen. In einem Interview mit New Scientist spricht Erstautor Yue Wu sogar von einer Beschleunigung um den Faktor 6.000. Ob die Anleitungen von den Entwickler:innen selbst oder aus dritter Hand von Wikipedia stammen, spiele dabei keine Rolle.
Eine der größten Herausforderungen sei die Erkennung von Objekten in Atari-Spielen. In modernen Spielen sei dies jedoch kein Problem, da diese Informationen über alle Objekte liefern. Außerdem deuten die jüngsten Fortschritte bei multimodalen Video-Sprachmodellen darauf hin, dass bald zuverlässigere Lösungen zur Verfügung stehen werden, die den Objekterkennungsteil des aktuellen Frameworks ersetzen könnten. In der realen Welt könnten moderne Computer-Vision-Algorithmen helfen.
Wer mehr über den Einsatz von Spielanleitungen im Reinforcement Learning lernen will, kann sich unseren DEEP MINDS Podcast mit Tim Rocktäschel anhören. Tim ist mittlerweile Forscher bei Deepmind.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.