Know3D steuert die unsichtbare Rückseite von 3D-Objekten per Textbefehl
Ein Forschungsteam nutzt das Wissen großer Sprachmodelle, um bei der 3D-Generierung aus Einzelbildern die Rückseite von Objekten gezielt per Text zu kontrollieren. Das adressiert ein grundlegendes Problem der 3D-Generierung.
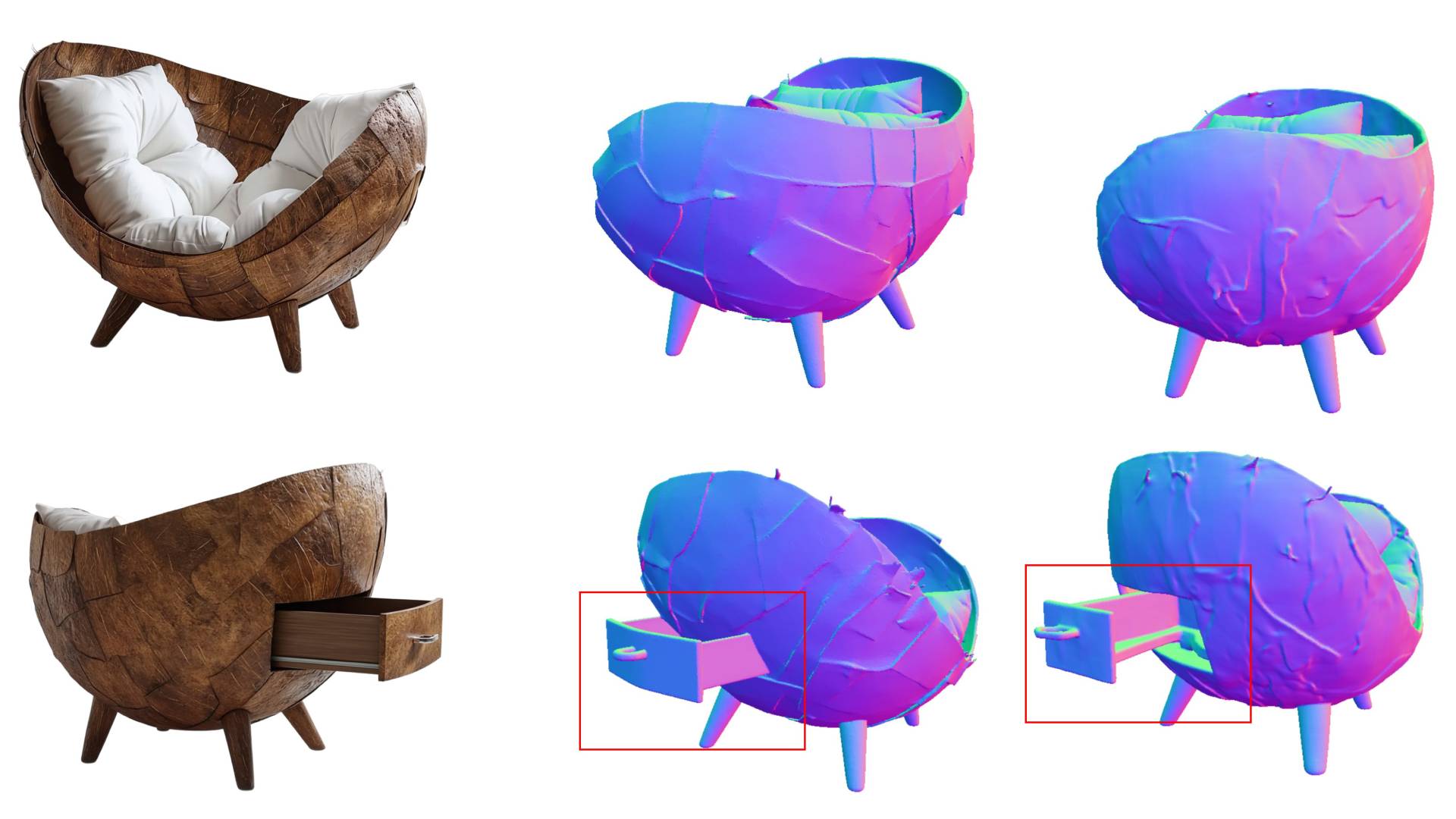
Wenn ein KI-Modell aus einem einzelnen Foto ein vollständiges 3D-Objekt erzeugen soll, fehlt ihm eine entscheidende Information: Das Bild zeigt nur eine Seite, die Rückseite muss das Modell im Grunde halluzinieren. Laut einem neuen Forschungspaper eines Teams verschiedener chinesischer Universitäten entstehen dabei häufig physikalisch unplausible Geometrien oder Ergebnisse, die nicht der Absicht des Nutzers entsprechen.
Das Problem wurzelt in der Datenlage: Im Vergleich zu den riesigen Bild- und Textdatensätzen im Internet bleiben 3D-Trainingsdaten knapp. Das Weltwissen, das 3D-Modelle aus ihren Trainingsdaten verinnerlichen, reicht oft nicht aus, um verdeckte Strukturen plausibel zu rekonstruieren.
Das Framework Know3D soll hier ansetzen, indem es das umfangreiche Weltwissen multimodaler Sprachmodelle in den 3D-Generierungsprozess einfließen lässt. Nutzer können dann per Textbeschreibung festlegen, was auf der nicht sichtbaren Seite eines Objekts erscheint.
Sprachmodell-Wissen gelangt auf Umwegen in die dritte Dimension
Der naheliegende Ansatz, die Ausgaben eines Sprachmodells direkt in ein 3D-Netzwerk einzuspeisen, funktioniert laut den Forschern nicht. Die Repräsentationen seien zu abstrakt und enthielten keine ausreichenden räumlichen Informationen, um daraus Geometrie abzuleiten.
Know3D wählt daher einen indirekten Weg und schaltet zwischen Sprachmodell und 3D-Generator ein Bildgenerierungsmodell als Übersetzer. Konkret nutzen die Forscher Qwen2.5-VL als Sprachmodell, Qwen-Image-Edit als Bildgenerierungsmodell und Microsofts Trellis.2 als 3D-Generator. Das Sprachmodell versteht die Textanweisung und analysiert das Eingabebild. Das Bildgenerierungsmodell wandelt dieses Verständnis in räumlich-strukturelle Informationen um, die wiederum den 3D-Generator steuern.
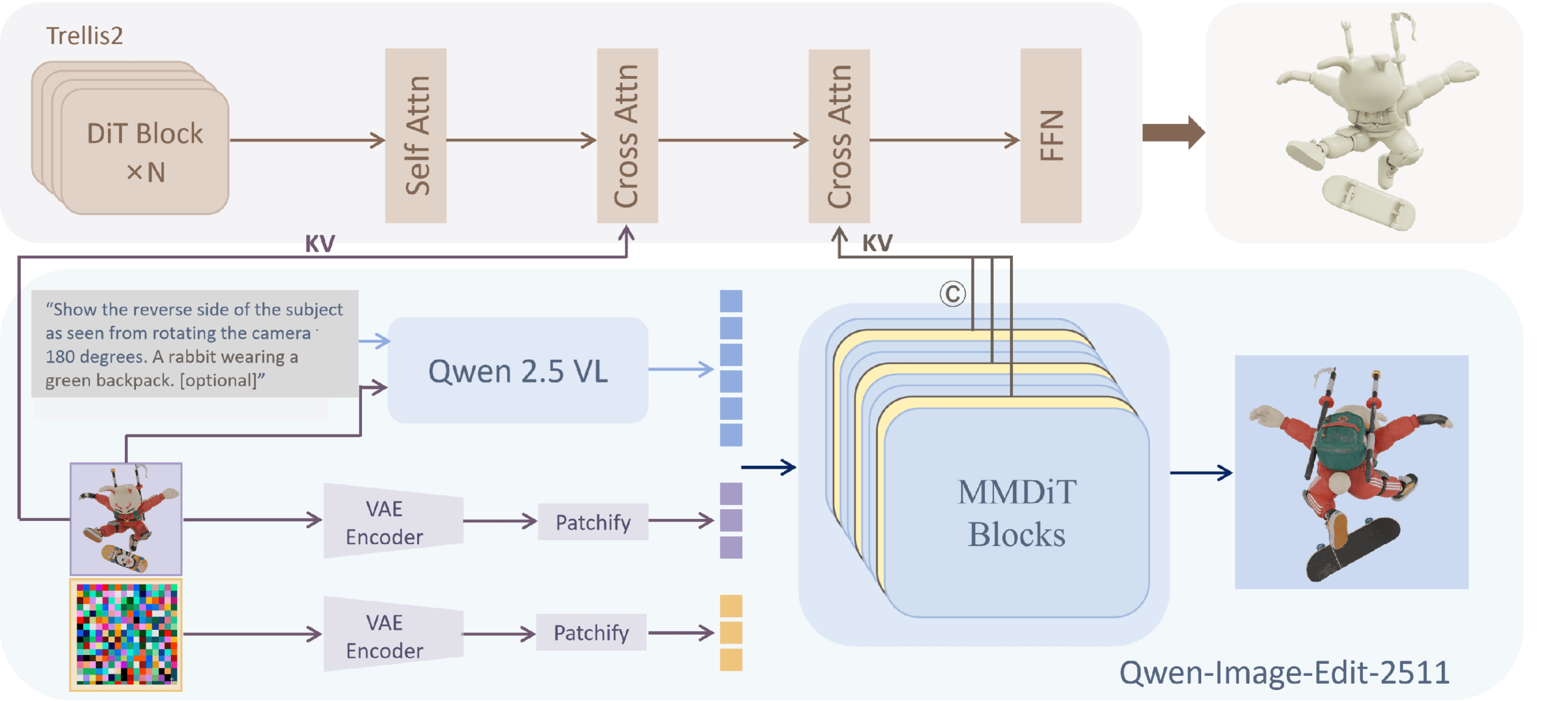
Entscheidend ist dabei, welche Informationen die Forscher aus dem Bildgenerierungsmodell abgreifen. Sie testeten drei Varianten: eine interne Bildrepräsentation des Modells kurz vor dem fertigen Ausgabebild, daraus abgeleitete Bildmerkmale via DINOv3 und die internen Zwischenzustände des Modells während des Erzeugungsprozesses. Letztere erwiesen sich als deutlich überlegen, weil sie sowohl semantische als auch räumliche Informationen tragen, ohne von pixelgenauen Details oder Fehlern im fertigen Bild abzuhängen.
Fehler im Zwischenschritt pflanzen sich nicht fort
Dieser Befund hat eine praktische Konsequenz: Erzeugt das Bildgenerierungsmodell eine fehlerhafte Rückansicht, etwa eine Einschultertasche mit zwei Trägern, übernehmen bildbasierte Methoden diesen Fehler direkt.
Die internen Zwischenzustände des Modells hingegen sind robuster. Sie enthalten offenbar genug räumliche und semantische Information, um trotzdem ein plausibles 3D-Objekt zu erzeugen. Offenbar bildet das Modell also schon in mittleren Verarbeitungsschritten ein recht verlässliches Verständnis von Struktur und Form aus.
Auch der Zeitpunkt, zu dem die Forscher diese Zwischenzustände abgreifen, beeinflusst das Ergebnis: Zu früh im Prozess fokussieren sich die Informationen zu stark auf Pixeldetails, zu spät dominiert Rauschen. Ein Zeitpunkt bei etwa einem Viertel des Prozesses lieferte laut den Ablationsstudien kompetitive Ergebnisse.
Know3D hebt sich von bestehenden Methoden primär durch seine Steuerbarkeit ab. Die Forscher zeigen in ihrem Paper, wie dasselbe Foto einer Kaffeetasse durch verschiedene Textanweisungen zu unterschiedlichen, aber jeweils geometrisch konsistenten Rückseiten führt. Auch bei Stühlen, Robotern oder Häusern passt das Modell die Rückseite an die jeweilige Beschreibung an, während es die sichtbare Vorderseite bewahrt.
Kompetitive Ergebnisse, aber Abhängigkeit vom Grundmodell
Auf dem HY3D-Bench, einem Benchmark des Hunyuan3D-Teams, erreicht Know3D laut den Forschern die besten Werte bei der semantischen Übereinstimmung zwischen Eingabebild und erzeugtem 3D-Objekt. Das gilt sowohl im Vergleich mit aktuellen Einzelbild-Methoden als auch gegenüber einem Ansatz, der die generierte Rückansicht zusätzlich als zweites Eingabebild nutzt. Bei der geometrischen Qualität der Rückseiten übertrifft Know3D die Vergleichsmethoden ebenfalls.

Wie gut die Ergebnisse ausfallen, hängt laut den Forschern davon ab, ob das zugrundeliegende Sprachmodell die Textanweisungen korrekt interpretiert. Versteht es eine Anweisung falsch, entstehen auch fehlerhafte 3D-Formen. Stärkere multimodale Modelle könnten dieses Problem künftig abmildern.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.