
Diffusion-Modelle wie Stable Diffusion können Bilder generieren. Ein neues Google-Modell erzeugt aus einem einzigen Bild 3D-Ansichten.
Innerhalb der Domäne generativer KI-Systeme haben sich im Laufe des Jahres Diffusion-Modelle durchgesetzt: KI-Systeme wie DALL-E 2, Imagen, Midjourney oder Stable Diffusion setzten auf die Methode, um Bilder zu generieren. Die Videomodelle Imagen Video, Make-a-Video und Phenaki generieren mit der Methode Videos, Motion Diffusion Animationen und CLIP-Mesh 3D-Modelle.
Nun zeigen Google-Forschende "3D Diffusion Models" (3DiM), ein Diffusion-Modell, das aus einem einzigen Bild neue 3D-Ansichten erzeugt.
Googles 3DiM generiert 3D-Ansicht mit einem Bild
Googles 3DiM verarbeitet für die 3D-Ansicht ein einziges Referenzbild mit Informationen über die relative Pose und erzeugt per Diffusion eine neue Ansicht. Anders als vergleichbare KI-Systeme nutzt 3DiM diese neuen Bilder für die Generierung folgender Ansichten, statt für jede neu generierte Ansicht ausschließlich das Input-Bild zu setzen. Die Google-Forschenden bezeichnen das als eine stochastischen Konditionierung.
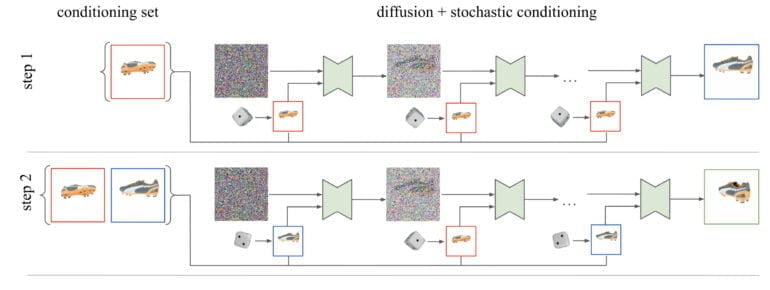
Konkret wählt das Modell während des umgekehrten Diffusionsprozesses jedes einzelnen Bildes bei jedem Entrauschungsschritt ein zufälliges Konditionierungsbild aus der Menge der vorherigen Bilder aus.
Diese stochastische Konditionierung liefere im Vergleich zum naiven Sampling-Verfahren, die nur ein einziges vorhergehendes Bild berücksichtigt, wesentlich konsistentere 3D-Ergebnisse, etwa in generierten Videos, schreibt das Google-Team.
Video: Google
Das Team trainierte zudem ein 471 Millionen Parameter großes 3DiM-Modell mit dem ShapeNet-Datensatz. Das Modell kann anschließend 3D-Ansichten für alle im Datensatz enthaltenen Objekte generieren.
3DiM nutzt Architekturverbesserungen, Google hofft auf Echtwelt-Daten
Neben der stochastischen Konditionierung profitiert 3DiM von einigen Veränderungen an der Architektur der klassischen Bild-zu-Bild UNet-Architektur. Die Forschenden schlagen X-UNet vor, eine Variante, die Gewichtungen des künstlichen Netzwerks zwischen verschiedenen Bildern teilt, sowie auf Cross-Attention setzt.

Sie zeigen, dass mit dieser Änderung bessere Ergebnisse möglich sind. 3D Diffusion Modelle können so laut des Teams eine Alternative zu anderen Techniken wie NeRFs darstellen, die mit Qualitätsproblemen und hohem Rechenaufwand zu kämpfen haben.
Als Nächstes möchte das Team die Fähigkeit der 3D-Diffusion-Modelle, ganze Datensätze in einem einzigen Netz zu modellieren, auf die größten 3D-Datensätze der realen Welt anwenden. Dafür sei jedoch noch mehr Forschung notwendig, um typischen Herausforderungen solcher Datensätze zu bewältigen, etwa verrauschte Posen oder unterschiedlichen Brennweiten in den Aufnahmen.
Mehr Beispiele und Informationen gibt es auf der 3DiM-Github-Seite.


