Ein neues generatives KI-System erzeugt 3D-Modelle aus einer Textbeschreibung. Die Modelle können direkt in üblichen Grafikengines verwendet werden.
Generative KI-Modelle wie OpenAIs DALL-E 2, Midjourney oder Stable Diffusion erzeugen beeindruckende Bilder nahezu jeden Stils. Der einzig nötige Input ist eine Textbeschreibung, die das gewünschte Ergebnis möglichst bildhaft beschreibt. Die KI-Grafik-Tools beschleunigen bestehende Arbeitsprozesse oder erstellen nahezu komplette Werke.
Die Technologie könne daher ein frühes Beispiel für die Auswirkungen von KI auf den Arbeitsmarkt zeigen, meint etwa OpenAI-Gründer Sam Altman. Wie der Fall eines Jason Allen zeigt, dessen KI-Kunstwerk einen Kunstwettbewerb gewann, sorgt bereits für Ärger unter Künstlerinnen und Designern.
Abseits der Modelle für Bilder arbeitet eine kleine Gruppe von Forschenden an einer neuen Klasse generativer KI-Systeme, die großes Potenzial haben, eine ganze Industrie zu revolutionieren: generative KI-Systeme für 3D-Modelle.
So zeigte etwa Ende 2021 Google Dream Fields, ein KI-Modell für die Generierung von 3D-Darstellung. Dream Fields verbindet OpenAIs CLIP mit einem NeRF-Generator. So ausgestattet, kann Dream Fields einfache NeRFs anhand von Textbeschreibungen erstellen.

Googles Methode ist jedoch zeit- und rechenintensiv. Ferner lassen sich NeRFs nicht direkt in 3D-Mesh-Modelle verwandeln. Solche Mesh-Modelle bilden aber die Grundlage der Darstellung nahezu aller aktuellen 3D-Objekte, etwa in Videospielen oder Simulationen.
CLIP-Mesh generiert direkt 3D-Mesh-Modelle
In einer neuen Forschungsarbeit der Concordia University, Kanada, zeigen Forschende nun CLIP-Mesh, ein generatives KI-Modell, das aus Textbeschreibungen direkt 3D-Mesh-Modelle mit Texturen und Normal Maps generiert.
Das Team rendert dafür verschiedene Ansichten eines simplen Modells, etwa einer Kugel. Diese Kugel wird von einem Renderer aus Textur, Normal-Map und Eckpunkten des Meshs erstellt.
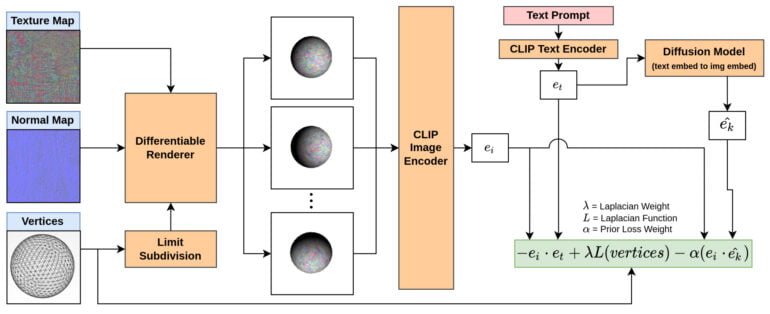
Die Ansichten werden von einem CLIP-Modul kodiert und mit der von einem weiteren CLIP-Modul kodierten Texteingabe verglichen. Zusätzlich wird diese kodierte Texteingabe von einem Diffusion-Modell in eine Bildeinbettung verwandelt, die ebenfalls zum Abgleich mit der ursprünglichen Kodierung der Ansichten verwendet wird.

CLIP-Mesh passt dann die dem Renderer zugeführten Texturen, Normal-Maps und Eckpunkte des Mesh-Modells nach dem Feedback des Text-Encoders und des Diffusion-Modells an.

In ersten Experimenten verwendet das Team eine Kugel mit 600 Eckpunkten sowie eine Textur- und Normal-Map-Auflösung von 512 mal 512 Bildpunkten. Mit diesen Daten generiert CLIP-Mesh ein 3D-Modell in 50 Minuten auf einer Nvidia P100 mit 16 Gigabyte Grafikspeicher. Die Form möglicher Modelle wird dabei durch die ursprünglichen Eckpunkte eingeschränkt - allzu variable Formen können aus einer Kugel nicht entstehen, so die Forschenden.
Generative KIs für 3D-Modelle sind nur eine Frage der Zeit
In einem kurzen Video zeigt das Team einen kleinen Raum, der komplett mit generierten 3D-Modellen ausgestattet ist. Die Ergebnisse sind klar als Objekte erkennbar und lassen sich problemlos in einer Engine, die 3D-Meshes verarbeitet, nutzen. CLIP-Mesh texturiert die Modelle dazu passend.
Video: Khalid et al.
CLIP-Mesh kann zudem auch eingesetzt werden, um mehrere Objekte zu bearbeiten. Dabei kann etwa eine Fläche lediglich texturiert und gleichzeitig ein darauf stehendes Modell komplett verändert werden.

CLIP-Mesh ist also theoretisch bereits vielfältig einsetzbar - auch wenn die produzierten 3D-Mesh-Modelle weit entfernt von der Qualität händischer 3D-Modellierung sind.
Ein potenziell großer Vorteil: Das Forschungsteam benötigte für das Modell dank des Einsatzes von CLIP keine eigene 3D-Datenbank. Potenziell könnten somit neue generative KI-Systeme für 3D-Modelle entstehen, die die umfassenden Datensätze für Bild-Systeme nutzen und keine zusätzlichen Daten benötigen. Wie weit dieser Ansatz trägt, wollen die Forschenden nun in Zukunft untersuchen.
Sollten generative KI-Modelle für 3D-Objekte eine ähnliche Entwicklungsgeschwindigkeit aufweisen wie 2D-Systeme, könnten in diesem Bereich spezialisierte Unternehmen wie OpenAI schon im nächsten Jahr Modelle vorstellen, die in einem weiteren Arbeitsmarkt gehörig Staub aufwirbeln werden: der 3D-Programmierung und -Gestaltung.