

Das ERGO Innovation Lab hat gemeinsam mit ECODYNAMICS eine Studie zur Sichtbarkeit von Versicherungsinhalten in KI-Suchsystemen veröffentlicht. Ausgewertet wurden über 33.000 KI-Suchergebnisse und 600 Webseiten. Die Ergebnisse zeigen: LLMs wie ChatGPT bevorzugen Inhalte, die technisch gut lesbar, semantisch klar strukturiert und vertrauenswürdig sind – alles Merkmale klassischer SEO. Inhalte, die modular aufgebaut, dialogorientiert (z. B. in Frage-Antwort-Form) und gut verlinkt seien, hätten höhere Chancen, in KI-Antworten aufzutauchen.
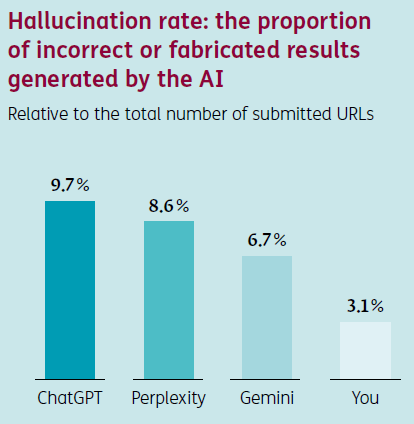
Zudem wurden Halluzinationsraten untersucht: ChatGPT lag mit knapp zehn Prozent am höchsten, während you.com deutlich stabilere Ergebnisse lieferte. Diese Erkenntnis beschränkt sich jedoch auf den Ergebnisraum "Versicherungen".




