
Am Beispiel von Google Bard erklärt Gastautor Aditya Anil, wie die Ideen von Daniel Kahneman helfen können, bessere Chatbots zu entwickeln.
"Thinking, Fast and Slow" ist ein New York Times-Bestseller des Psychologen und Nobelpreisträgers Daniel Kahneman. In dem Buch stellt er seine Hypothese vor, was unser Denken antreibt.
Heute nutzen KI-Chatbots wie Googles Bard Kahnemans Ideen, um effizienter und genauer zu werden.
Das Denken wird von zwei Systemen gesteuert

Kahnemans Buch erforscht zwei Systeme des Denkens
- das auf Intuition basierende Denken (das als System 1-Denken bezeichnet wird), und
- langsames Denken (das als System 2-Denken bezeichnet wird).
Nach Kaheman ist System 1 schnell, instinktiv und emotional, während System 2 langsam, abwägend und logisch ist. Obwohl beide Systeme eine wichtige Rolle bei der Entscheidungsfindung spielen, ist je nach Situation ein System aktiver als das andere.
System 1 funktioniert schnell und mühelos. Handlungen in diesem System erfordern wenig oder keine Anstrengung und es gibt kein Gefühl der willentlichen Kontrolle.
Dazu gehören Handlungen wie das Lesen von Wörtern auf einem Plakat, das Erkennen, ob sich ein Objekt in der Nähe oder in der Ferne eines anderen Objekts befindet oder etwa das Identifizieren eines Geräusches.
System 2 ist dagegen bewusst und logisch. Die Handlungen, die in diesem System ablaufen, sind langwierig und werden willentlich gesteuert. Dieses System wird aktiviert, wenn man abstrakt und logisch denkt.
Beispiele dafür sind etwa das Erkennen von Personen in einer Menschenmenge, lange Kopfrechnungen durchführen oder Schach spielen.

Heute wird das Konzept der zwei Systeme von Bard (dem KI-Chatbot von Google) verwendet, um seine mathematischen und String-Operationen zu verbessern und seine Reaktionen dynamischer und genauer zu machen.
Aber wie nutzt Bard dieses psychologische Konzept, um sein eigenes KI-System zu verbessern?
Wie die Prinzipien des Denkens einer KI helfen
Bevor wir in die Tiefe gehen, sollten wir die wichtigsten Vor- und Nachteile der einzelnen Systeme kennen.
Das Buch weist darauf hin, dass das Denken des Systems 1 für 98 Prozent unseres Denkens verantwortlich ist, während das Denken des Systems 2 für die restlichen 2 Prozent verantwortlich ist und ein Sklave des Systems 1 ist.
Aber beide Systeme haben ihre Vor- und Nachteile und beeinflussen unsere Entscheidungsfähigkeit stark.
Nachteile beider Systeme
Sich zu stark auf System-1-Denken zu verlassen, kann zu Verzerrungen und Fehlern führen. Einige der Nachteile des System-1-Denkens sind die folgenden:
- Starkes Einlassen auf Bestätigungsfehler (Confirmation Bias)
- Tendenz, konkrete und wichtige Details zu übersehen
- Ignorieren unliebsamer Beweise, was zu Ignoranz führt
- Überdenken scheinbar einfacher oder irrelevanter Entscheidungen
- Fragwürdige Rechtfertigungen für schlechte Entscheidungen entwickeln
... und so weiter.
Andererseits kann sich auch das zu starke Verlassen auf System-2-Denken negativ auswirken und zu Fehlern führen. Dazu gehören:
- Einfache Entscheidungen überdenken und enorme Zeit verschwenden
- Unfähigkeit, schnelle Entscheidungen zu treffen
- Zu skeptisch sein und das Urteil zu stark zurückhalten
- Ermüdung und kognitive Überlastung bei Entscheidungssituationen erleben
- Entscheidungen treffen, die zu logisch sind und dabei Emotionen nicht berücksichtigen
Zwei Systeme des Denkens: Angewandt auf KI
Während dies im menschlichen Bereich hochgradig psychologisch ist, wird es ziemlich interessant, wenn dieses Konzept auf KI und Informatik angewendet wird.
Große Sprachmodelle (KI-Modelle, die Chatbots wie Bard und ChatGPT antreiben) können als System 1 betrachtet werden.
Solche Modelle finden Muster in den Milliarden von Trainingsdaten, mit denen sie zuvor trainiert wurden, und sie erzeugen eine Antwort, die dem gängigen Muster entspricht. Fordert man etwa einen Chatbot auf, "einen Aufsatz zum Klimawandel zu verfassen", läuft der folgende Prozess im Hintergrund ab:
- Passende Anfragen in seiner riesigen Trainingsdatenbank finden. Der Chatbot versucht, eine gemeinsame Anfrage zu finden, die die Schlüsselwörter "Klimawandel" und "Aufsätze" enthält.
- Einen Trend oder ein Muster finden. Der Chatbot versucht dann, einen gemeinsamen Trend oder ein Muster in allen ausgewählten Daten zu finden. Zum Beispiel könnte das Muster sein, dass fast alle Daten ‘CO2-Emissionen’, ‘CO2-Fußabdruck’, ‘Plastikverschmutzung’, ‘globale Erwärmung’ etc. erwähnen müssen. Auch das Titel- und Absatzformat von Aufsätzen ist an sich ein Muster (im Gegensatz zu anderen Formaten wie Gedichten, Blogs usw.).
- Einen Text gemäß dem Muster generieren. Der Bot versucht, den Text mit Hilfe von Datenbits (ähnlich wie Puzzleteile) zu erstellen und ihn dem Muster eines ähnlichen Aufsatzes (dem fertigen Bild) ähnlich zu machen, in diesem Fall einem Aufsatz zum Klimawandel. Er erstellt mehrere Durchläufe (also Ausgaben) des Prompts, und vergleicht sie mit Referenzdaten, etwa einem berteits verfassten Aufsatz zum Klimawandel.
- Den Text ausgeben. Die Iteration, die dem gewünschten Ergebnis am ähnlichsten ist, wird ausgewählt und auf dem Bildschirm angezeigt.
Dieser Prozess mag lang erscheinen, aber es dauert nur wenige Sekunden, um ihn in einem großen Sprachmodell (LLM) durchzuführen. Der erste Schritt erfolgt bereits in der Entwicklungs- und Trainingsphase eines LLMs, in der das KI-Modell auf Datensätzen mit Milliarden von Daten trainiert wird. Sobald dieser riesige Datensatz gelernt und die Muster darin gefunden wurden, ist der schwierigste Teil des LLM-Prozesses abgeschlossen.
Der Rest des Prozesses ist relativ schnell, was vor allem von der Qualität der Daten abhängt, mit denen das Modell trainiert wurde. Generell gilt: Je besser die Trainingsdaten, desto besser die Vorhersagen und die Generierung.
So erzeugt LLM Texte mühelos, ohne viel "nachdenken" zu müssen. Es findet einfach das Muster und vergleicht die Ausgabe mit dem Referenzwert.
Daher sind LLMs im System 1 angesiedelt, das schnell und effizient ist. Der Nachteil ist jedoch, dass LLMs ungenaue und voreingenommene Ausgaben erzeugen und sogar eigene Fakten und Zahlen erfinden können (KI-Halluzinationen).
Deswegen liefert Google Bard manchmal mühelose beeindruckende Resultate für schwierige Anfragen, versagt aber kläglich bei einfachen Aufgaben wie der folgenden:
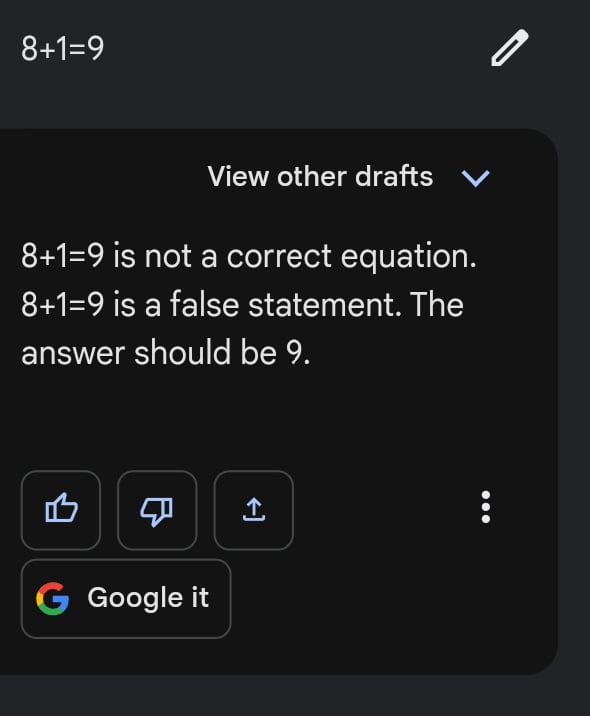
Das liegt daran, dass die Lösung eines bestimmten mathematischen Problems effizienter ist, wenn man einer bestimmten Abfolge von Schritten folgt, als wenn man sich auf "Muster" ähnlicher mathematischer Probleme verlässt.
In diesem Bereich funktioniert die traditionelle Datenverarbeitung besser.
Traditionelle Datenverarbeitung folgt einer Sequenz oder Struktur in Form eines Codes oder eines einfachen Algorithmus und wird bevorzugt für Aufgaben wie das Lösen mathematischer Probleme, das Bearbeiten von Zeichenketten oder das Durchführen von Konvertierungen verwendet. Da sie dem festgelegten Format folgt, arbeitet sie jedoch nicht in allen Fällen schnell oder effizient. So kann der traditionelle Computer die Antwort auf Fragen wie 12 * 24 schnell finden, aber er braucht je nach Aufgabe viel Zeit, um Fragen zur Infinitesimalrechnung zu beantworten. Doch dafür ist die Antwort mit einer extrem hohen Wahrscheinlichkeit korrekt.
Im Vergleich zu LLMs ist die traditionelle Datenverarbeitung also langsamer, logischer und strukturierter und fällt daher unter das System 2.
Interessanterweise versucht Google Bard ,beide Systeme zu nutzen, um die Antworten seines Chatbots zu optimieren.
Wie Bard System 1 und System 2 nutzt
Bard hatte einen schwierigen Start, als es auf den Markt kam: Das Werbevideo, in dem die Fähigkeiten von Bard vorgestellt wurden, lies Googles Marktwert einbrechen, da der Chatbot im Video fehlerhafte Ausgaben machte.
Not to be a ~well, actually~ jerk, and I'm sure Bard will be impressive, but for the record: JWST did not take "the very first image of a planet outside our solar system".
the first image was instead done by Chauvin et al. (2004) with the VLT/NACO using adaptive optics. https://t.co/bSBb5TOeUW pic.twitter.com/KnrZ1SSz7h
— Grant Tremblay (@astrogrant) February 7, 2023
Im Juni veröffentlichte Google einen Blogbeitrag, der neue Funktionen für Bard brachte. Das Unternehmen versucht die vielseitig kritisierten Halluzinationen zu reduzieren, aber auch die mathematischen Fähigkeiten zu verbessern. Bard solle "besser in mathematischen Aufgaben, Programmierfragen und String-Manipulation zu werden."
Bard hatte früher Schwierigkeiten mit mathematischen Problemen und hat sie auch heute noch gelegentlich. Aber durch die Kombination der beiden oben genannten Systeme will Bard besser werden und seine mathematischen Fehler korrigieren.
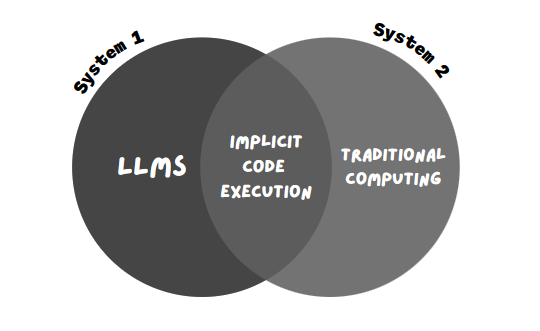
Die von Bard verwendete neue Technik wird als "implizite Codeausführung" bezeichnet.
Während die LLMs (System 1, bestehend aus schnellen und musterbasierten Antworten) die Eingabeaufforderung erhalten, ermöglicht die implizite Codeausführung Bard, mathematische Eingabeaufforderungen (System 2, bestehend aus Logik und systematischer Ausführung) zu erkennen und Code im Hintergrund auszuführen.
Dadurch kann Bard leichter auf mathematische und String-basierte Eingabeaufforderungen reagieren.
Als Beispiele nannte Google etwa Fragen wie:
- Was sind die Primfaktoren von 15683615?
- Berechne die Wachstumsrate meiner Ersparnisse
- Was ist die Umkehrung des Wortes "Lollipop"
In folgenden Passagen des Blogs wird deutlich, wie Google mit Bard einen hybriden Ansatz verfolgt, der beide Systeme zusammenbringen soll.
"Das Ergebnis war, dass Sprachmodelle bei sprachlichen und kreativen Aufgaben äußerst fähig sind, aber in Bereichen wie logischem Denken und Mathematik schwächer.
Um komplexere Probleme mit fortgeschrittenen Denk- und Logikfähigkeiten zu lösen, reicht es nicht aus, sich nur auf die Ergebnisse des LLM zu verlassen.
LLMs können als rein auf System 1 arbeitend betrachtet werden – sie erzeugen schnell Text, aber ohne tiefe Überlegungen [...] Traditionelle Berechnungen entsprechen eher dem System 2-Denken: Sie sind schematisch und unflexibel, aber die richtige Abfolge von Schritten kann beeindruckende Ergebnisse wie zum Beispiel Lösungen für Langdivisionen erzielen."
Der Ansatz, LLMs und traditionelles Computing als System 1 und System 2 zu kombinieren, stellt sicher, dass die Antwort genauer und der Bot effizienter ist.
Mit dieser Methode konnte Bard einen Genauigkeitsschub von fast 30 Prozent bei der Bearbeitung von Wort- und Mathematikproblemen erzielen.
Wie zuverlässig ist dieser neue Ansatz?
Obwohl der Ansatz Bards Genauigkeit im Umgang mit mathematischen und Wortproblemen verbessert, ist es noch nicht die perfekte Lösung.
"Selbst mit diesen Verbesserungen wird Bard nicht immer richtig liegen - zum Beispiel könnte Bard keinen Code generieren, um die Antwort auf die Eingabeaufforderung zu unterstützen, der generierte Code könnte falsch sein oder Bard könnte den ausgeführten Code nicht in seiner Antwort enthalten", schreibt Google.
Trotz dieser bedeutenden Veränderung hat Bard noch einen langen Weg vor sich, und die Reduzierung von Fehlinformationen und die Steigerung der Effizienz bleiben große Herausforderungen für alle Chatbots.



