Llama 3: Meta veröffentlicht neue leistungsfähige Open-Source-Sprachmodelle

Meta AI hat heute Llama 3, die nächste Generation seiner Open-Source-Sprachmodelle, veröffentlicht. Laut Meta sollen die neuen Modelle den besten proprietären Modellen ebenbürtig sein und bald auch Multimodalität und mehr Sprachen unterstützen.
Meta hat heute die ersten beiden Modelle der nächsten Generation von Llama vorgestellt. Die Reihe mit dem Namen Meta Llama 3 umfasst zunächst vortrainierte und instruktions-trainierte Sprachmodelle mit 8 bzw. 70 Milliarden Parametern.
Nach Angaben des Unternehmens handelt es sich dabei um die besten Open-Source-Modelle ihrer Klasse. Die Modelle seien ein großer Fortschritt gegenüber Llama 2 und zeigten deutlich verbesserte Fähigkeiten wie logisches Schlussfolgern, Codegenerierung und das Befolgen von Anweisungen.
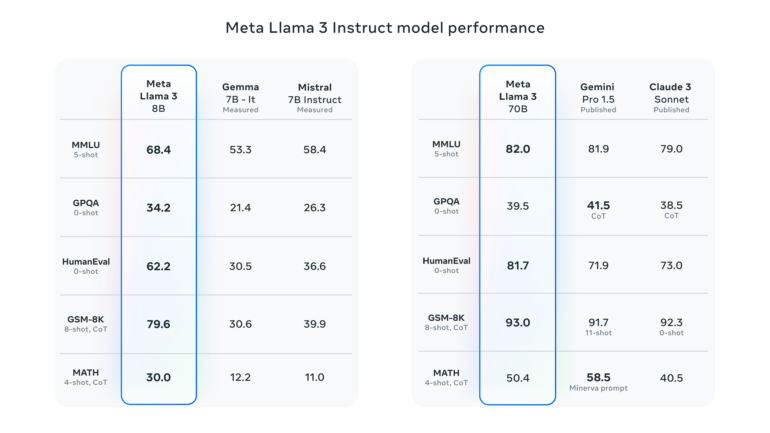
In den von Meta vorgestellten Benchmarks übertrifft Llama 3 70B in mehreren Benchmarks wie MMLU proprietäre Modelle wie Googles Gemini 1.5 Pro und Anthropics Claude 3 Sonnet, bleibt aber hinter führenden Modellen wie Claude 3 Opus und OpenAIs GPT-4 Turbo zurück.
Llama 3: Training mit 15 Billionen Token
Der Leistungssprung anderem auf einen massiven Anstieg der Trainingsdaten zurückzuführen: Llama 3 wurde auf über 15 Billionen Token vortrainiert, die alle aus öffentlich zugänglichen Quellen stammen. Der Datensatz ist siebenmal größer als bei Llama 2 und enthält viermal mehr Code. Mehr als 5 Prozent der Daten sind nicht auf Englisch, sondern decken über 30 Sprachen ab - auch wenn Meta in diesen Sprachen noch nicht die gleiche Leistung wie auf Englisch erwartet.
Bei der Architektur setzt Meta auf die Decoder-Only-Transformer, der aber unter anderem einen effizienteren Tokenizer mit einem Vokabular von 128.000 Token verwendet. Allerdings kommen die ersten beiden Modelle nur mit einem Kontextfenster von 8.000 Token. Der Knowledge Cutoff für Llama 3 8B ist März 2023, für Llama 70B Dezember 2023.
Um Llama 3 sicher und verantwortungsvoll einsetzen zu können, stellt Meta verschiedene neue Tools bereit, darunter aktualisierte Versionen von Llama Guard und Cybersec Eval sowie das neue Code Shield, das als Leitplanke für die Ausgabe unsicheren Codes durch Sprachmodelle dient.
Größere und bessere Llama-3-Modelle mit bis zu 400 Milliarden Parametern sollen kommen
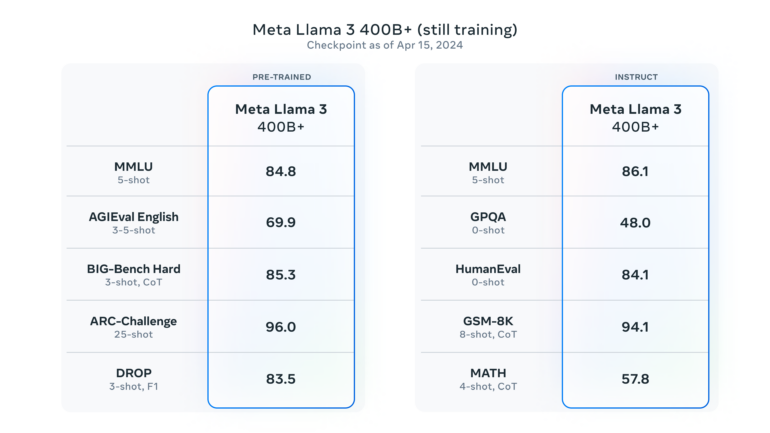
Mit den heute veröffentlichten Modellen ist Llama 3 nicht komplett: Meta will die Modelle weiterentwickeln und in den kommenden Monaten zusätzliche Modelle mit neuen Fähigkeiten wie Mehrsprachigkeit, einem längeren Kontextfenster und stärkeren Gesamtfähigkeiten veröffentlichen. Die größten Modelle von Llama 3 haben laut Meta über 400 Milliarden Parameter und befinden sich noch in der Trainingsphase. Meta will auch ein detailliertes Forschungspapier veröffentlichen, sobald das Training von Llama 3 abgeschlossen ist. Das größte Modell könnte das Niveau von GPT-4 erreichen, wie einige vorläufige Benchmarks zeigen, die Meta anhand eines aktuellen Schnappschusses des 400B-Modells erstellt hat.
Die Llama-3-Modelle werden bald auf Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM und Snowflake sowie mit Unterstützung von Hardwareplattformen von AMD, AWS, Dell, Intel, NVIDIA und Qualcomm verfügbar sein. Sie sind zudem auf Metas Llama 3 Seite zum Download und Amazon SageMaker verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.