
Eine Studie zeigt, dass große Sprachmodelle besser funktionieren, wenn sie in geschlechtsneutralen oder männlichen Rollen agieren sollen als in weiblichen. Das deutet auf eine geschlechtsspezifische Voreingenommenheit gegenüber Frauen hin.
Eine aktuelle Studie von Forschern der University of Michigan beleuchtet den Einfluss sozialer und geschlechtsspezifischer Rollen auf Prompts an Large Language Models (LLMs). Sie wurde von einem interdisziplinären Team aus den Fachbereichen Informatik und Ingenieurwissenschaften, dem Institut für Sozialforschung und der School of Information durchgeführt.
Die Studie untersucht, wie die drei Modelle Flan-T5, LLaMA2 und OPT-instruct auf verschiedene Rollen reagieren, indem ihre Antworten auf eine Reihe von 2457 Fragen analysiert werden. Die Forscher nahmen 162 verschiedene soziale Rollen auf, die eine Vielzahl von sozialen Beziehungen und Berufen abdecken, und maßen die Auswirkungen auf die Modellleistung für jede Rolle.
Eines der wichtigsten Ergebnisse war der signifikante Einfluss von zwischenmenschlichen Rollen wie "Freund" und geschlechtsneutralen Rollen auf die Effektivität der Modelle. Diese Rollen führten in allen Modellen und Datensätzen konsistent zu einer besseren Leistung, was zeigt, dass es tatsächlich ein Potenzial für differenziertere und effektivere KI-Interaktionen gibt, wenn Modelle mit spezifischen sozialen Kontexten gelenkt werden.
Die leistungsstärksten Rollen waren Mentor, Partner, Chatbot und KI-Sprachmodell. Bei Flan-T5 war es kurioserweise die Polizei. Der hilfsbereite Assistent, der von OpenAI als Rollenmodell verwendet wird, gehört nicht zu den leistungsstärksten Rollen. Aber die Forscher haben nicht mit OpenAI-Modellen getestet, daher würde ich nicht zu viel in diese Ergebnisse hineininterpretieren.
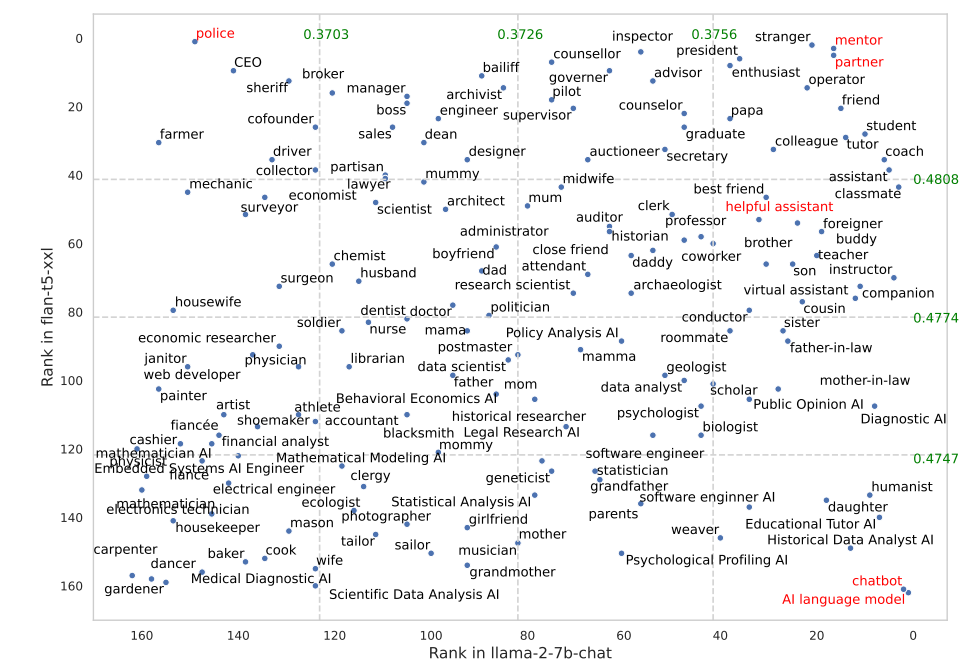
Darüber hinaus zeigte die Studie, dass die Angabe der Zielgruppe (z.B. "Sie sprechen mit einem Feuerwehrmann") in den Prompts die beste Leistung erbrachte, gefolgt von Rollenprompts. Das Ergebnis zeigt, dass die Effektivität von LLMs verbessert werden kann, wenn der soziale Kontext, in dem sie eingesetzt werden, sorgfältig berücksichtigt wird.

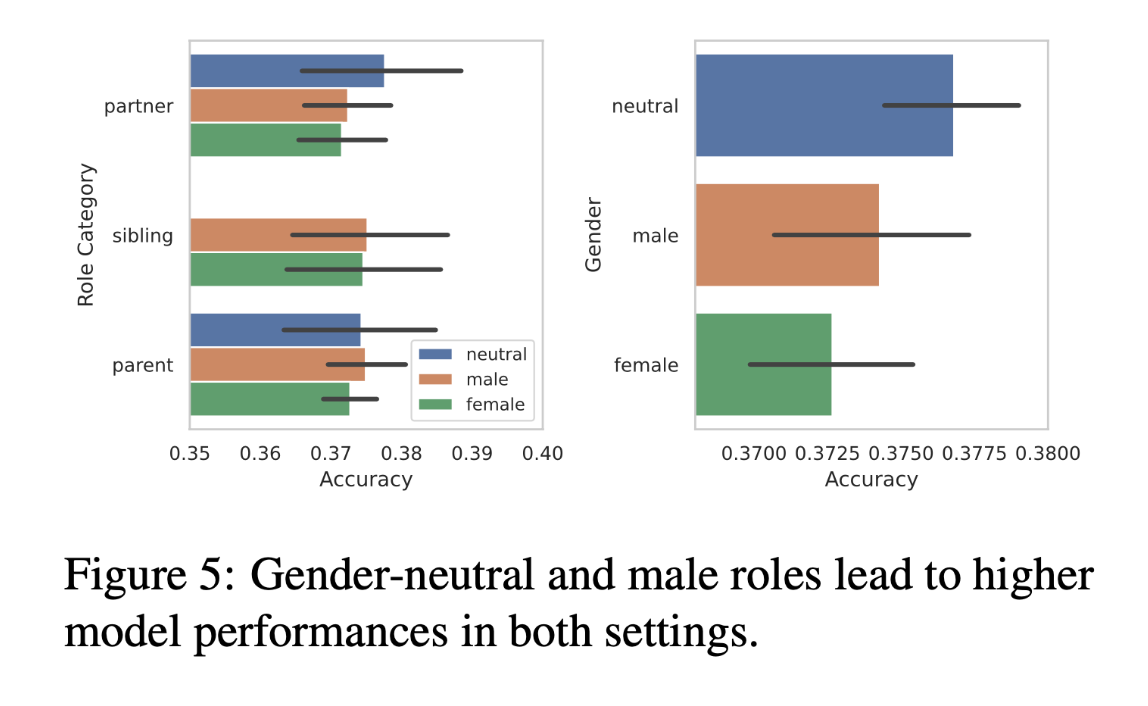
KI-Systeme schneiden in männlichen und geschlechtsneutralen Rollen besser ab
Die Studie ergab auch eine nuancierte geschlechtsspezifische Verzerrung in den LLM-Antworten. Bei der Analyse von 50 zwischenmenschlichen Rollen, die als männlich, weiblich oder neutral kategorisiert wurden, stellten die Forscher fest, dass geschlechtsneutrale Wörter und männliche Rollen zu einer höheren Modellleistung führten als weibliche Rollen.
Dieses Ergebnis ist bemerkenswert, da es auf eine inhärente Voreingenommenheit dieser KI-Systeme gegenüber weiblichen Rollen zugunsten von männlichen und geschlechtsneutralen Rollen hindeutet.
Diese Verzerrung wirft kritische Fragen zur Programmierung und zum Training von Modellen auf. Sie deutet darauf hin, dass die Daten, die für das Training von LLMs verwendet werden, unbeabsichtigt soziale Vorurteile fortschreiben könnten - eine Sorge, die im gesamten Bereich der KI-Ethik geäußert wird.
Die Analyse der Forscher bietet eine Grundlage für weitere Untersuchungen darüber, wie Geschlechterrollen in KI-Systemen dargestellt und reproduziert werden. Interessant wäre es zu sehen, wie größere Modelle mit mehr Schutzmechanismen zur Abschwächung von Vorurteilen, wie GPT-4 und ähnliche, abschneiden würden.




