Mathe braucht Bedenkzeit, Alltagswissen ein gutes Gedächtnis: Forscher optimieren KI-Architektur

Kurz & Knapp
- Eine neue Transformer-Architektur lässt jede Schicht selbst entscheiden, wie oft sie ihren Rechenblock wiederholt. Zusätzliche Speicherbänke stellen faktisches Wissen bereit.
- Das geloopte Modell mit nur zwölf Schichten übertrifft bei Mathe-Aufgaben ein herkömmliches Modell mit 36 Schichten und gleichem Rechenaufwand um 6,4 Prozent. Bei Alltagswissen helfen die Schleifen kaum, dort schließen die Speicherbänke die Lücke.
- Im Training entsteht eine Selbstorganisation: Frühe Schichten wiederholen kaum, späte loopen intensiv und greifen häufiger auf Speicher zu. Loops und Speicher wirken dabei nicht als Ersatz, sondern als Ergänzung.
Ein deutsches Forschungsteam lässt Transformer-Modelle selbst entscheiden, wie oft sie über ein Problem nachdenken. In Kombination mit zusätzlichem Speicher übertrifft das Ergebnis deutlich größere Modelle bei Mathe-Aufgaben.
Sprachmodelle können über Chain-of-thought-Prompting Schritt für Schritt denken. Doch jeder Zwischenschritt erfordert zusätzliche Token. Sogenannte geloopte Transformer bieten eine Alternative: Sie wenden denselben Rechenblock mehrfach auf ihre internen Repräsentationen an, ohne Zwischenschritte als Text auszugeben. Das spart Parameter, kostet aber Speicherkapazität – denn das Modell hat weniger einzigartige Gewichte, in denen es Wissen ablegen kann.
Ein Forschungsteam vom Lamarr-Institut, Fraunhofer IAIS und der Universität Bonn geht in einer Arbeit der Frage nach, ob sich dieser Zielkonflikt auflösen lässt. Die Forschenden schlagen eine Architektur vor, die zwei Mechanismen vereint. Zum einen adaptives Looping, bei dem jede Transformer-Schicht über einen gelernten Haltemechanismus selbst entscheidet, wie oft sie ihren Rechenblock wiederholt. Zum anderen gelernte Speicherbänke, die zusätzliches Wissen bereitstellen.
Die Basisarchitektur ist ein Decoder-only-Transformer mit 12 Schichten und rund 200 Millionen Parametern, trainiert auf 14 Milliarden Token aus dem deduplizierten FineWeb-Edu-Datensatz. Die geloopten Varianten erlauben jeder Schicht bis zu 3, 5 oder 7 Iterationen. Die Speicherbänke umfassen 1024 lokale Slots pro Schicht und 512 globale, geteilte Slots. Das entspricht laut der Studie etwa 10 Millionen zusätzlichen Parametern.
Looping hilft beim Rechnen, Speicher beim Alltagswissen
Die Ergebnisse zeigen laut den Forschenden: Wenn ein Modell seine Berechnungen bis zu dreimal wiederholen darf, wird es bei mathematischen Aufgaben deutlich besser. Das geloopte Modell erzielt dort 22 Prozent bessere Werte als das Basismodell ohne Schleifen. Am stärksten profitieren anspruchsvolle Teilgebiete wie Precalculus (31 Prozent Verbesserung) und Intermediate Algebra (26 Prozent). Bei Aufgaben, die Alltagswissen erfordern – etwa Fragen zu sozialen Situationen oder physikalischer Intuition –, bringen die Schleifen dagegen kaum Vorteile. Mit zusätzlichen Durchläufen sinkt die Leistung dort sogar leicht.
Um den Effekt einzuordnen, vergleichen die Forschenden ihr 12-Schichten-Modell mit Dreifachschleife mit einem herkömmlichen Modell mit 36 Schichten, das denselben Rechenaufwand verursacht, aber keine Schleifen nutzt. Trotz nur eines Drittels der Schichten schneidet das geloopte Modell bei Mathe-Benchmarks um 6,4 Prozent besser ab. Schleifen seien damit effizienter als zusätzliche Schichten, wenn es um mathematisches Denken gehe, schreiben die Forschenden.
Die Speicherbänke lösen ein anderes Problem. Alltagswissen lässt sich nicht durch wiederholtes Nachdenken erzeugen, sondern muss abgelegt sein. Die Speicherbänke liefern genau diese zusätzliche Kapazität und schließen einen Teil der Wissenslücke, die Schleifen allein nicht überbrücken können. In Kombination verbessert sich das Modell laut der Studie gegenüber der Variante ohne Speicher um weitere 4,2 Prozent bei Mathe und zwei Prozent bei Alltagswissens-Aufgaben.
Frühe Schichten sind genügsam, späte Schichten arbeiten intensiv
Obwohl das Modell keinen expliziten Strafterm für die Anzahl der Schleifendurchläufe erhält, entsteht laut den Autoren von selbst eine Spezialisierung: Frühe Schichten lernen, ihre Rechenblöcke nur minimal zu wiederholen und kaum auf den Speicher zuzugreifen. Späte Schichten dagegen loopen intensiver und nutzen die Speicherbänke häufiger.
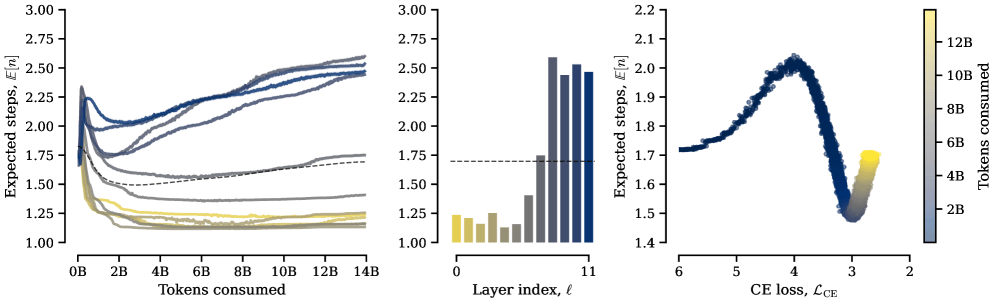
Das passt laut der Arbeit zu früherer Forschung, wonach frühe Transformer-Schichten lokale syntaktische Muster kodieren, während spätere Schichten komplexere semantische und logische Operationen übernehmen. Einfache Berechnungen profitieren demnach nicht von zusätzlichen Iterationen – die anspruchsvolleren Operationen in tieferen Schichten dagegen schon.
Dazu kommt ein auffälliger Wendepunkt im Training: Zu Beginn nutzen die Modelle ihre Schleifen kaum, obwohl sie es könnten. Erst wenn das Modell gut genug gelernt hat, Sprache zu verstehen und vorherzusagen, beginnt es, seine Berechnungen tatsächlich zu wiederholen. Dieser Schwellenwert tritt laut den Forschenden bei allen Loop-Konfigurationen an nahezu derselben Stelle auf. Das Modell muss also erst grundlegende Sprachfähigkeiten aufbauen, bevor es vom wiederholten Nachdenken profitieren kann.
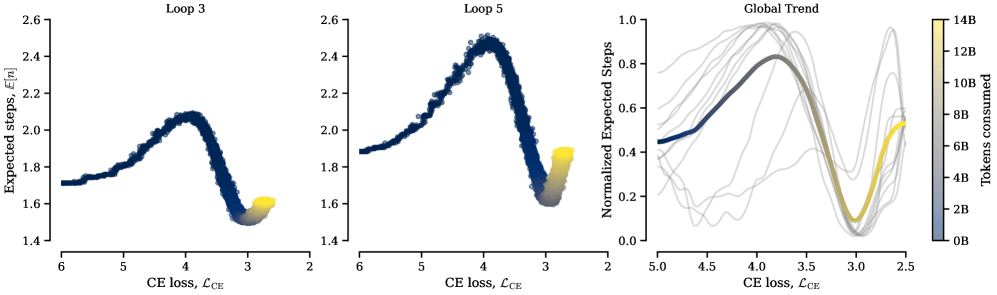
Mehr Berechnung verlangt nach mehr Wissen
Die Forschenden sehen in ihren Ergebnissen einen Beleg für eine grundlegende Aufgabenteilung innerhalb von Transformern. Die Feed-Forward-Schichten fungieren als eine Art Speicher für faktische Assoziationen, während Aufmerksamkeitsschichten Informationen routen und manipulieren. Looping verbessere das Routing, könne aber unzureichende Speicherkapazität nicht kompensieren.
Dass Schichten, die häufiger loopen, auch stärker auf den Speicher zugreifen, stützt diese Interpretation: Schleifen und Speicher ergänzen sich. Wer mehr rechnet, braucht offenbar auch mehr Fakten.
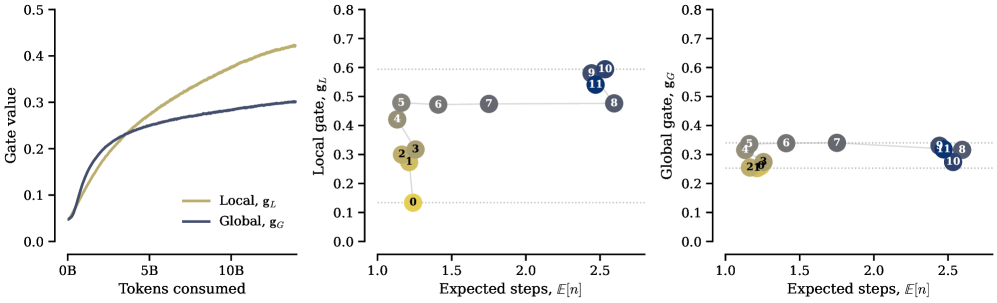
Die Autoren benennen selbst Einschränkungen: Die Experimente liefen in relativ kleinem Maßstab, rund 200 Millionen Parameter und 14 Milliarden Trainingstoken. Ob die Ergebnisse bei Modellen mit mehreren Milliarden Parametern halten, die bereits über erhebliche Kapazität verfügen, bleibt offen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren