Wer KI menschlicher klingen lässt, verliert laut Studie an inhaltlicher Präzision

Forschende der Universität Zürich zeigen, dass sich KI-Texte noch immer zuverlässig von menschlicher Sprache unterscheiden lassen. Der Versuch, Modelle menschlicher klingen zu lassen, geht oft zulasten der inhaltlichen Präzision.
Da Sprachmodelle zunehmend menschliches Verhalten in der Sozialforschung simulieren sollen – etwa als digitale Zwillinge in Umfragen –, hängt der Wert dieser Methoden entscheidend davon ab, wie glaubwürdig die KI echte Personen imitieren kann.
Ein eigens trainierter, auf BERT basierender Klassifikator konnte die KI-generierten Antworten mit einer Genauigkeit von 70 bis 80 Prozent von menschlichen Texten unterscheiden, ein Wert, der weit über der statistischen Zufallswahrscheinlichkeit liegt.
Die schiere Größe eines Modells brachte anscheinend kaum einen Vorteil. Modelle mit mehr Parametern schrieben nicht zwangsläufig menschenähnlicher als kompakte Systeme. Zudem schnitten sogenannte Basis-Modelle oft besser ab als Varianten, die durch "Instruction Tuning" darauf trainiert wurden, Anweisungen zu befolgen.
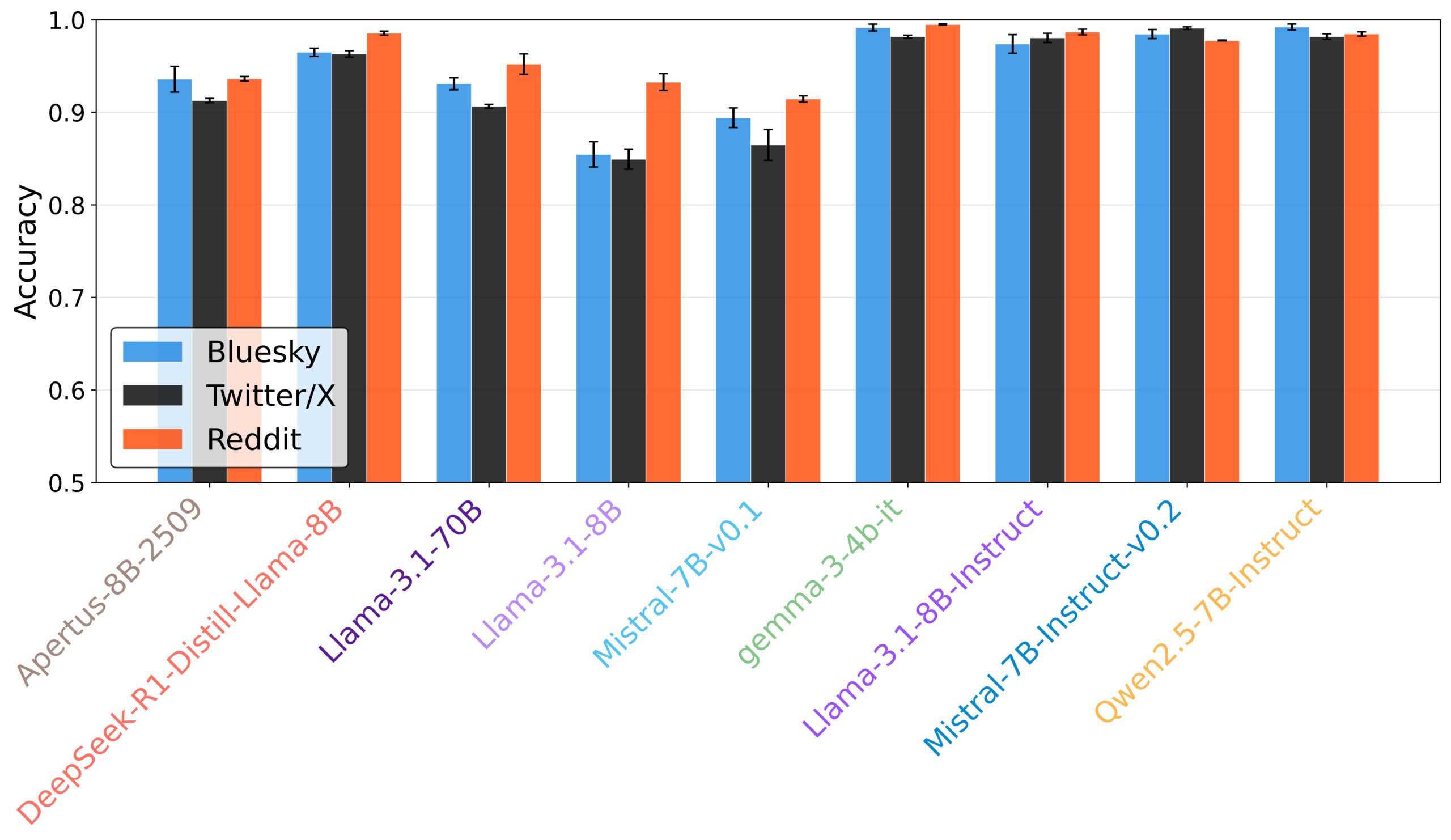
In ihrem Paper untersuchten die Forschenden neun offene Sprachmodelle auf ihre Fähigkeit, Nutzerinteraktionen auf Plattformen wie X, Bluesky und Reddit glaubwürdig zu imitieren. Das Testfeld umfasste Apertus, Deepseek-R1, Gemma 3, Qwen2.5 sowie verschiedene Varianten von Llama 3.1 und Mistral 7B.
Komplexität garantiert keine Menschlichkeit
Um den maschinellen Texten mehr Natürlichkeit zu verleihen, setzen Entwickler häufig auf komplexe Anpassungsstrategien. Dazu zählen etwa detaillierte Rollenbeschreibungen ("Persona") oder ein gezieltes Nachtraining mit spezifischen Daten ("Fine-Tuning").
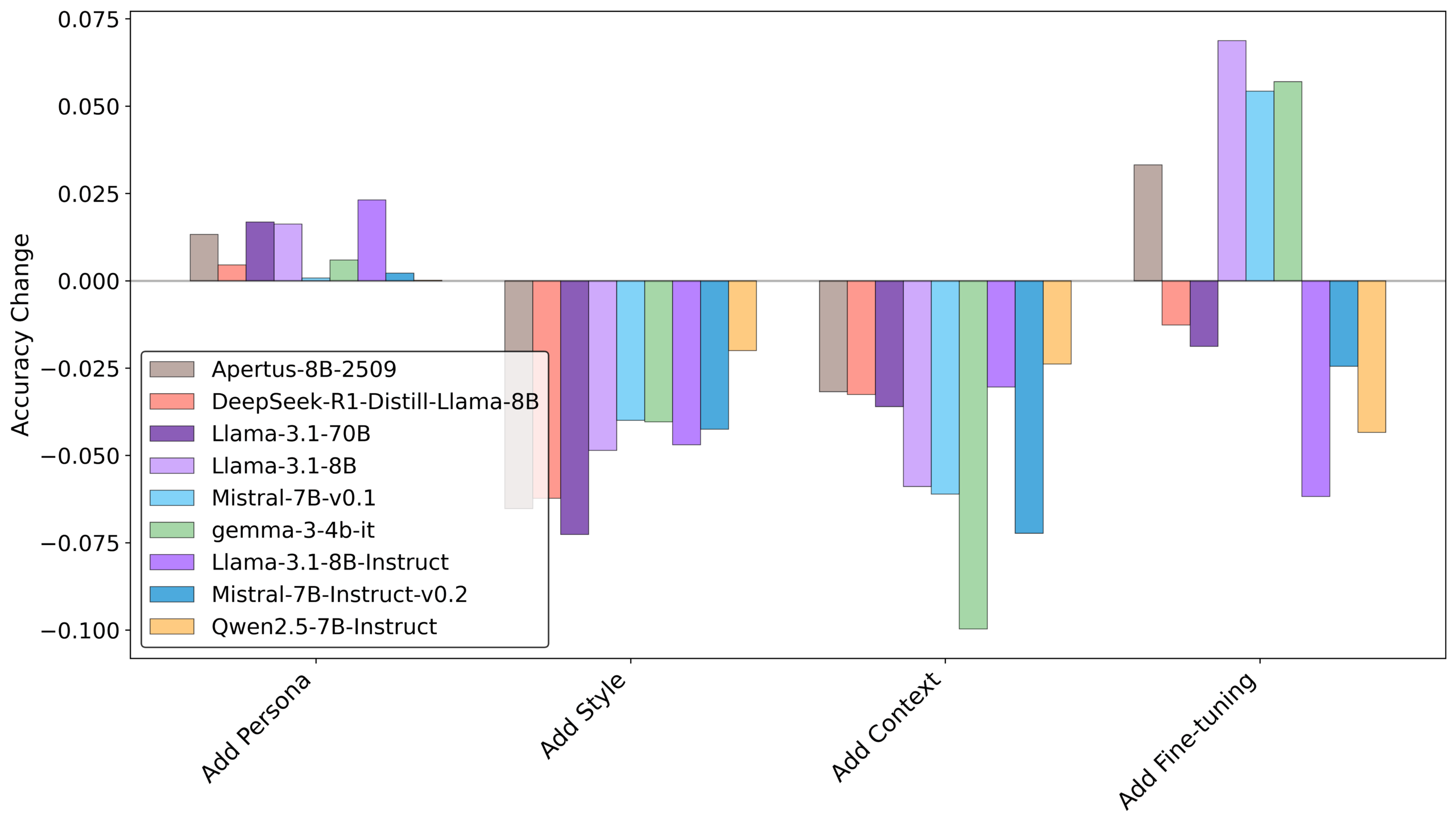
Die Studie deutet jedoch darauf hin, dass diese komplexen Eingriffe oft wirkungslos bleiben oder die Texte sogar leichter als künstlich entlarven. "Einige ausgefeilte Strategien, wie Fine-Tuning und Persona-Beschreibungen, schaffen es nicht, den Realismus zu verbessern, oder machen den Text sogar besser erkennbar", heißt es in der Untersuchung.
Effektiver erwiesen sich simplere Ansätze: Wenn die Forschenden der KI konkrete Beispiele für den gewünschten Schreibstil zeigten oder Kontextinformationen aus früheren Posts mitlieferten, sank die Erkennungsrate messbar. Dennoch blieben die Texte auch nach dieser Optimierung für die Analyse-Software meist klar identifizierbar.
Der Konflikt zwischen Stil und Inhalt
Ein zentrales Ergebnis der Arbeit ist ein fundamentaler Zielkonflikt: Es scheint kaum möglich, gleichzeitig den menschlichen Klang und den exakten Inhalt einer Nachricht zu optimieren. Die Forschenden verglichen die KI-Texte mit den echten Antworten der simulierten Personen. Dabei zeigte sich, dass Maßnahmen zur Verschleierung der KI-Herkunft oft dazu führten, dass sich der Inhalt von der eigentlichen menschlichen Referenzantwort entfernte.
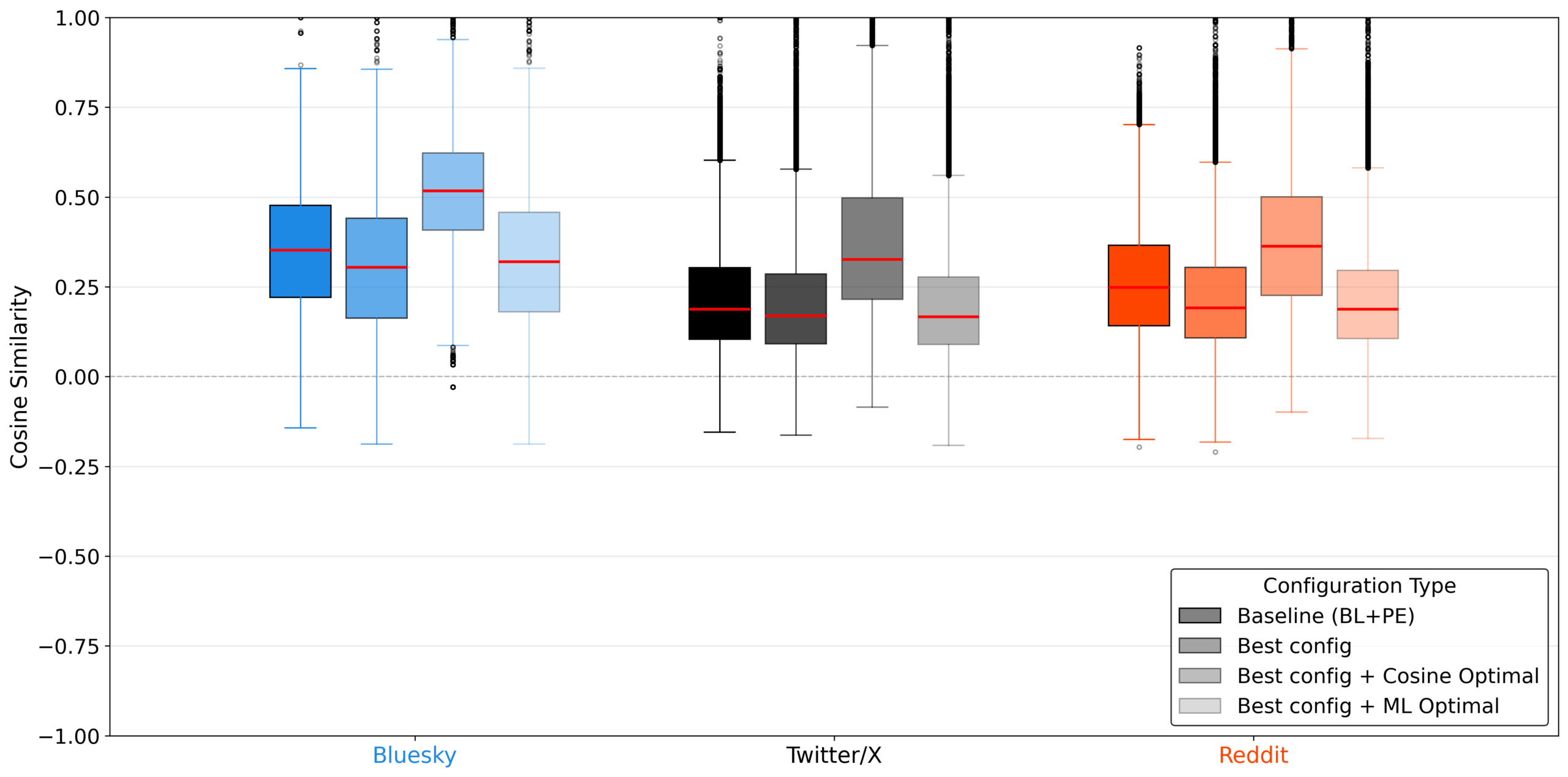
"Unsere Ergebnisse zeigen einen Kompromiss, bei dem die Optimierung auf Menschlichkeit oft auf Kosten der semantischen Treue geht und umgekehrt", schreiben die Autoren.
Für die Anwendung bedeutet dies ein Dilemma. Die Modelle können entweder Stil, Tonfall und Satzlänge besonders menschlich wirken lassen oder sich stärker am Inhalt der menschlichen Referenzantwort orientieren. Laut Studie gelingt es ihnen jedoch kaum, beides gleichzeitig in derselben Antwort zu vereinen.
Emotionen als Achillesferse
Die linguistische Analyse offenbarte zudem, woran die Simulation im Detail scheitert. Während sich strukturelle Merkmale wie die Satzlänge anpassen lassen, bleiben Emotionen die große Schwachstelle. Besonders bei affektiver oder aggressiver Sprache verfehlten die Modelle den menschlichen Tonfall signifikant.
Oft trafen die KI-Modelle nicht den spezifischen Jargon der jeweiligen Plattform – etwa bei Emojis, Hashtags und emotionalen Kategorien. Während die Täuschung auf X vergleichsweise gut gelang, fiel sie auf dem kommunikativ raueren Parkett von Reddit deutlich schwerer. Die Studie warnt deshalb davor, Sprachmodelle unkritisch als Ersatz für menschliche Kommunikation in der Forschung zu verwenden.
Bereits in der Vergangenheit hofften Forschende des MIT und der Harvard University, den gesamten sozialwissenschaftlichen Prozess mittels KI-Agenten und Kausalmodellen automatisieren zu können. Doch schon damals war die Übertragbarkeit auf echtes menschliches Verhalten die größte Hürde.
Die Ergebnisse der Forscher validieren auch KI-Text-Detektoren mit hohen Erkennungsraten wie Pangram. Entgegen früherer Annahmen scheint es doch so zu sein, dass KI-Text auch ohne komplexe Erkennungsinstrumente wie Wasserzeichen zumindest maschinell erkannt werden kann. Ob das eine gesellschaftliche Relevanz hat oder haben sollte, ist jedoch eine kulturelle und keine technische Debatte.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.