Meta veröffentlicht erste multimodale Llama-4-Modelle und die EU bleibt außen vor
Meta startet mit den beiden kleinsten Llama-Modellen, das leistungsstärkste befindet sich noch in der Entwicklung. Die Modelle sind von Grund auf multimodal und nutzen erstmals die Mixture-of-Experts-Architektur.
Meta hat die ersten beiden Modelle seiner neuen Llama-4-Generation vorgestellt. Beide Modelle verarbeiten Text und Bilder in einer gemeinsamen Architektur und basieren erstmals auf einer Mixture-of-Experts-Struktur (MoE).
Die Modelle wurden mit einer Vielzahl von Bildern und Videos trainiert, um ein breites visuelles Verständnis zu ermöglichen. Während des Vortrainings wurden sie mit bis zu 48 Bildern gleichzeitig konfrontiert, und in den Tests nach dem Training zeigten sie gute Analyseergebnisse mit bis zu acht Bildern als Eingabe.
Llama 4 Scout
Das kleinste Modell ist Llama 4 Scout. Es verfügt über 17 Milliarden aktive Parameter und 16 Experten (109 Milliarden insgesamt) und soll auf einer einzigen H100-GPU laufen. Laut Meta eignet es sich für Aufgaben wie Langtextverarbeitung, visuelle Frage-Antwort-Systeme, Codeanalyse und Multi-Image-Verständnis.
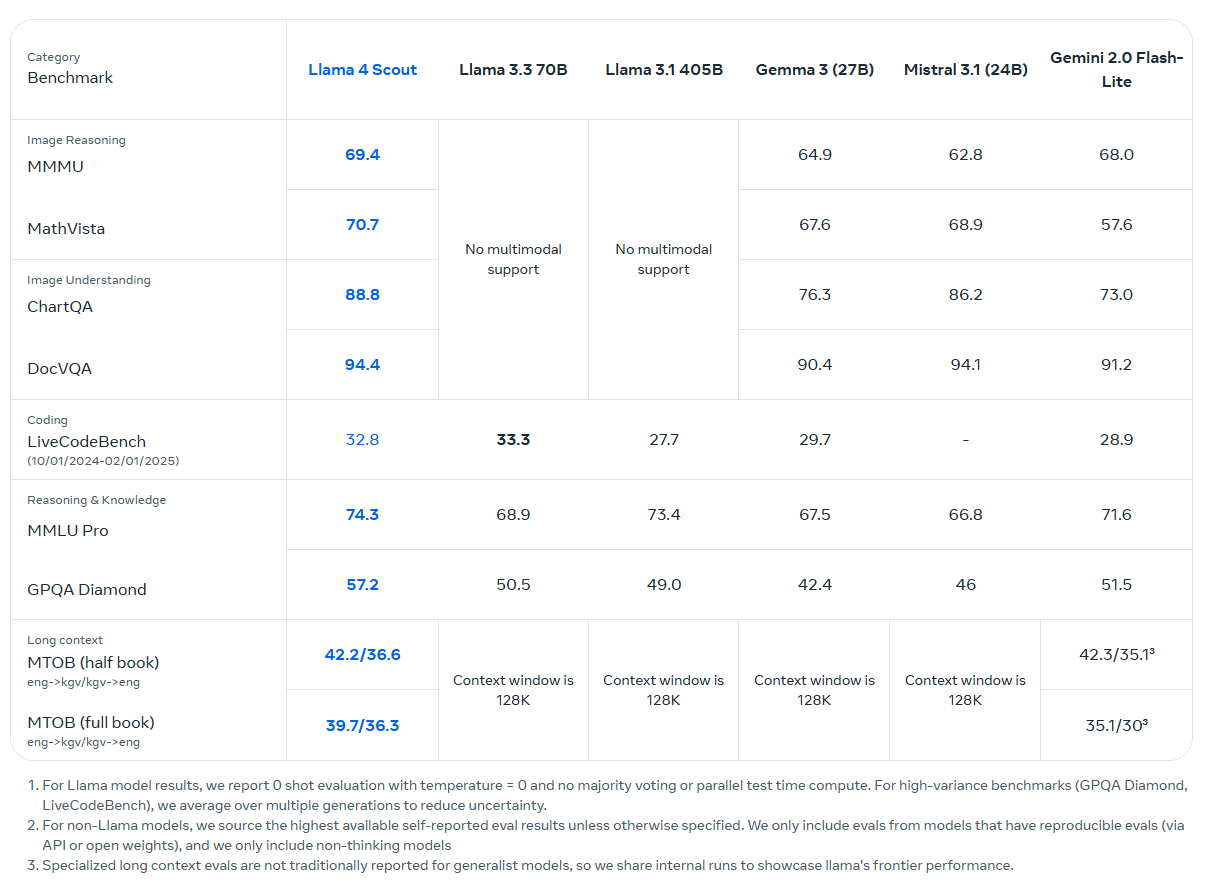
Meta hebt das große Kontextfenster von Scout mit 10 Millionen Token - etwa 5 Millionen Wörter aufwärts - hervor. Das klingt beeindruckend, aber Meta lässt die wichtigere Frage offen: Nicht, wie viele Daten hineinpassen, sondern wie gründlich und zuverlässig diese bei komplexen Anfragen abgedeckt werden, die über eine reine Wortsuche hinausgehen, die man auch mit Strg+F abdecken könnte. Alle Sprachmodelle haben dabei deutliche Schwächen, bei Text und bei Bildern.
Dass Meta für den Performance-Nachweis des Scout-Kontextfensters immer noch den längst veralteten und irreführenden "Needle in the Haystack"-Benchmark anführt, spricht nicht für einen Durchbruch. Hier gibt es mittlerweile bessere Benchmarks, die gezielt die Verknüpfung von Informationen im Kontextfenster testen. Außerdem wurde das Modell sowohl im Pre-Training als auch im Post-Training nur mit einer Kontextlänge von 256K trainiert. Das beworbene 10-Millionen-Token-Fenster basiert auf einer Längengeneralisierung.
Llama 4 Maverick
Das größere Modell Llama 4 Maverick verwendet ebenfalls 17 Milliarden aktive Parameter, hat allerdings 128 Experten (400 Milliarden Parameter insgesamt). Maverick kann laut Meta auf einem einzigen H100-Host betrieben werden. Die MoE-Architektur reduziert die Rechenlast, indem nur ein Teil der Parameter pro Eingabe aktiviert wird. Die Kontextlänge beträgt eine Million Token.
Laut Meta schlägt es OpenAIs GPT-4o und Googles Gemini 2.0 Flash in verschiedenen Benchmarks und erreicht ähnliche Ergebnisse wie DeepSeek v3 bei Reasoning und Coding - mit weniger als der Hälfte der aktiven Parameter. In der experimentellen Chatversion erreicht Maverick 1417 Punkte in der LMArena ELO Rangliste.
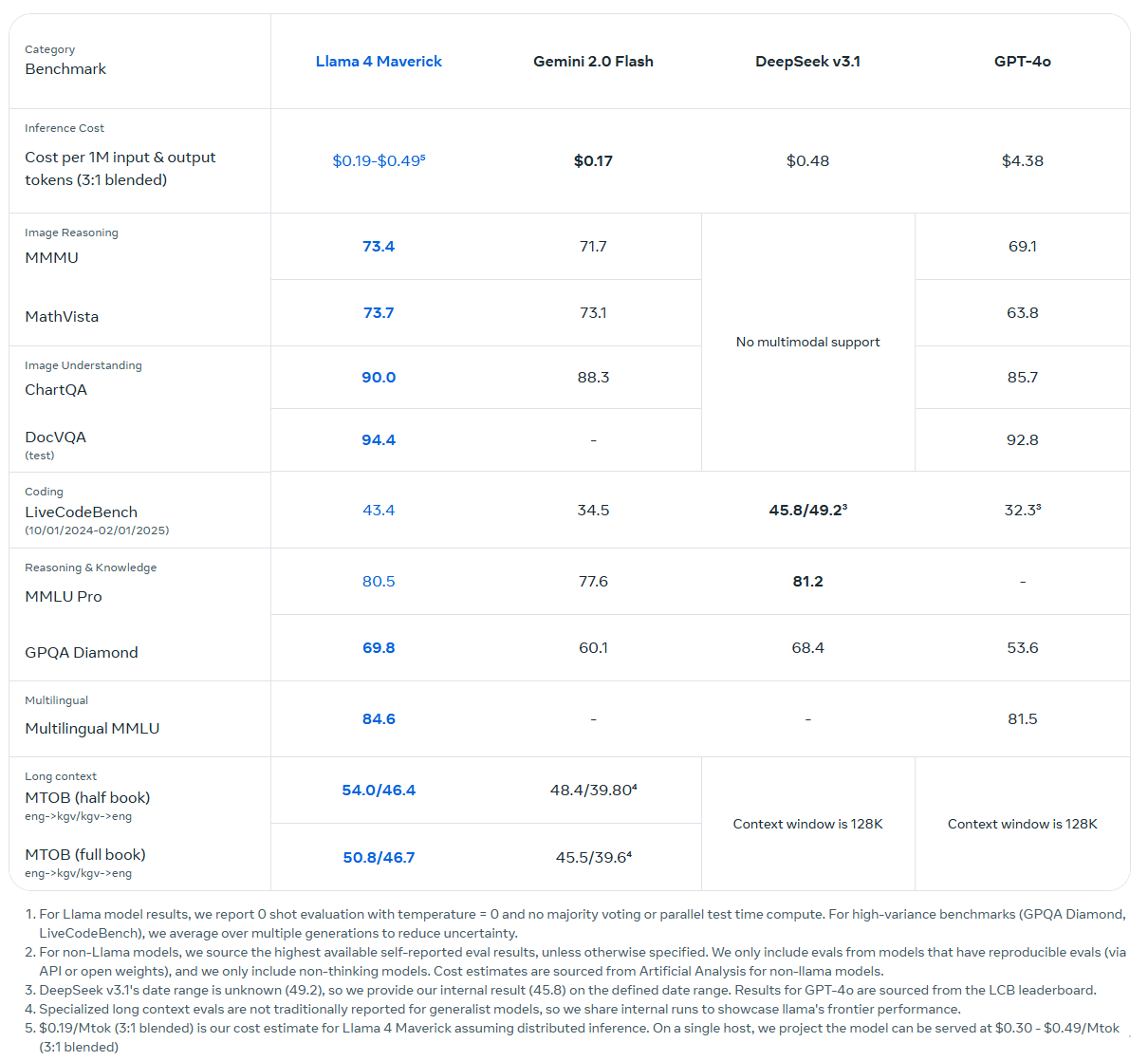
Scout und Maverick sind ab sofort als Open-Weight-Modelle über llama.com und Hugging Face erhältlich. Sie werden auch in Meta-Produkten wie WhatsApp, Messenger, Instagram Direct und Meta.ai eingesetzt. Meta plant weitere Entwicklungen für die Llama-4-Reihe und will diese auf der LlamaCon am 29. April vorstellen, für die man sich hier anmelden kann.
Llama 4 "Behemoth" trainiert die kleineren Modelle
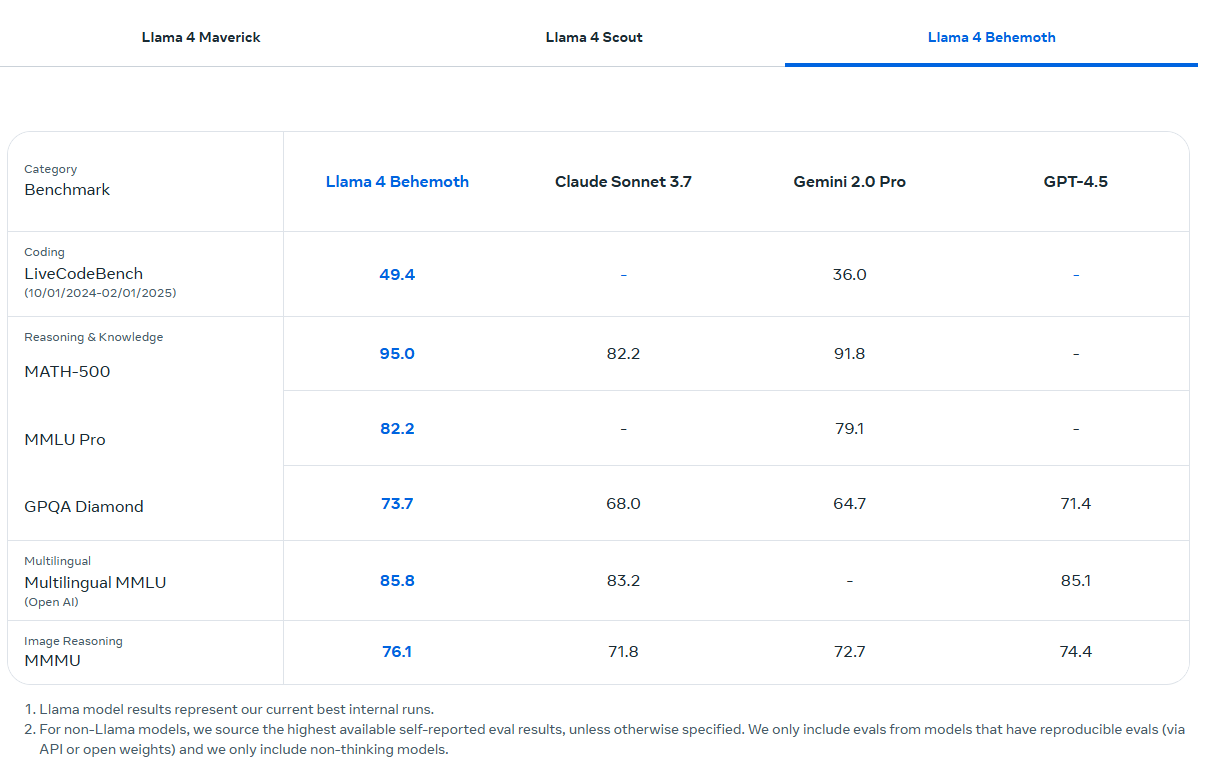
Beide Modelle wurden mit Hilfe von Llama 4 Behemoth entwickelt, einem bisher unveröffentlichten Modell mit 288 Milliarden aktiven Parametern, 16 Experten und insgesamt 2 Billionen Parametern.
Behemoth dient als "Lehrermodell" für Scout und Maverick und übertrifft laut Meta GPT-4.5, Claude Sonnet 3.7 und Gemini 2.0 Pro in mathematischen und wissenschaftlichen Benchmarks. Meta scheut hier allerdings den Vergleich mit Googles neuem Gemini 2.5 Pro, das als Reasoning-Hybrid bessere Test-Ergebnisse erzielt und vorn liegt. Ein Llama-Reasoning-Modell gibt es bisher nicht, es dürfte aber folgen.
Nach dem Haupttraining verfeinert Meta die Llama-4-Modelle in mehreren Schritten, um ihre Fähigkeiten weiter zu verbessern (Post-Training). Zunächst werden sie mit einer kleinen Auswahl von Beispieldaten leicht nachtrainiert (Supervised Fine-Tuning).
Anschließend durchlaufen sie eine Phase, in der sie aus Rückmeldungen lernen und für gute Antworten belohnt werden (Online Reinforcement Learning). Meta entwickelte hierfür ein vollständig asynchrones Online-RL-Trainingssystem, was zu einer etwa zehnfachen Verbesserung der Trainingseffizienz gegenüber früheren Generationen führte.
Zum Schluss folgt eine gezielte Feinabstimmung, die darauf abzielt, die Qualität der Antworten weiter zu erhöhen (Direct Preference Optimization). Ein besonderer Fokus liegt dabei auf schwierigen Aufgabenstellungen: Leicht lösbare Beispiele wurden konsequent aussortiert – beim Modell Llama 4 Maverick mehr als zur Hälfte, beim besonders großen Behemoth-Modell sogar zu 95 Prozent. Auf diese Weise will Meta sicherstellen, dass die Modelle auch bei komplexen Fragen, etwa im Bereich Argumentation oder Bildverstehen, zuverlässig und präzise reagieren.
EU darft Llama-4 nicht nutzen
Die Llama-4-Modelle werden unter der bekannten Llama-Lizenz veröffentlicht - mit einer Neuerung für die EU: Die Nutzung der multimodalen Modelle ist für Unternehmen mit Sitz in der EU oder für Einzelpersonen mit Wohnsitz in der EU ausgeschlossen. Die Restriktion bezieht sich nicht auf Endverbraucher.

Es war bereits bekannt, dass die Llama 4 Modelle wegen "regulatorischer Unsicherheiten" vorerst nicht in der EU erscheinen werden. Es handelt sich um einen Machtkampf zwischen Meta und der EU um die Regeln des EU-AI-Acts, die Meta aufweichen will oder mehr Klarheit fordert - je nach Sichtweise.
Ansonsten müssen Entwickler sichtbare Hinweise wie „Built with Llama“ anbringen und dürfen nur Modellnamen verwenden, die mit "Llama" beginnen. Große Plattformanbieter mit mehr als 700 Millionen monatlich aktiven Nutzern benötigen eine Sondergenehmigung von Meta.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.