Meta zeigt generatives KI-Modell mit Datenbankzugriff

Generative KI-Modelle wie DALL-E 2 oder Stable Diffusion speichern ihr Wissen in ihren Parametern. Meta zeigt ein Modell, dass stattdessen auf eine externe Datenbank zugreifen kann.
Aktuelle generative KI-Modelle wie DALL-E 2 generieren beeindrucken Bilder, speichern jedoch ihr Wissen in den Modell-Parametern. Verbesserungen erfordern daher immer größere Modelle und immer mehr Trainingsdaten. Forschende arbeiten daher an einer Reihe von Möglichkeiten, Modellen neue Konzepte beizubringen oder direkt Zugriff auf externe Informationen zu geben.
Die Ideen für externe Zugriffe kommen aus einem anderen Feld generativer KI-Modellen: der Verarbeitung natürlicher Sprache. OpenAI, Google oder Meta haben bereits WebGPT und andere Sprachmodelle gezeigt, die etwa auf Internet-Artikel zugreifen können, um ihre Antworten zu überprüfen.
Google und Meta setzen auf Abfragen für multimodale Modelle
Im Oktober zeigten Google-Forschende Re-Imagen (Retrieval-Augmented Text-to-Image Generator), ein generatives Modell, das auf eine externe multimodale Wissensdatenbank zugreift und dort Referenzen abruft, um Bilder zu erzeugen. Re-Imagen bezieht über die Datenbank etwa semantische und visuelle Informationen über unbekannte oder seltene Objekte und verbessert so die Genauigkeit bei der Bild-Generierung.

In einer neuen Arbeit zeigen nun Forschende von Meta, der Stanford University und der University of Washington das generative Modell RA-CM3 (Retrieval Augmented CM3), das ebenfalls auf eine externe Datenbank zugreifen kann. CM3 steht für "Causal Masked Multimodal Model" und ist ein von Meta Anfang 2022 vorgestelltes Transformer-Modell, das Bilder und Texte generieren kann.
Metas RA-CM3 setzt auf externe Datenbank und ist dadurch deutlich kleiner
Metas RA-CM3 wurde mit einem Teil des LAIONs-Datensatz trainiert, der auch für Stable Diffusion genutzt wurde. Anders als Re-Imagen kann RA-CM3 Text und Bild verarbeiten. Als Input können also Text-Prompts oder Bilder dienen.
Der Input wird von einem multimodalen Encoder verarbeitet und an einen Retriever geleitet, der relevante multimodale Daten aus einem externen Speicher abfragt, die ebenfalls von einem multimodalen Encoder verarbeitet werden.
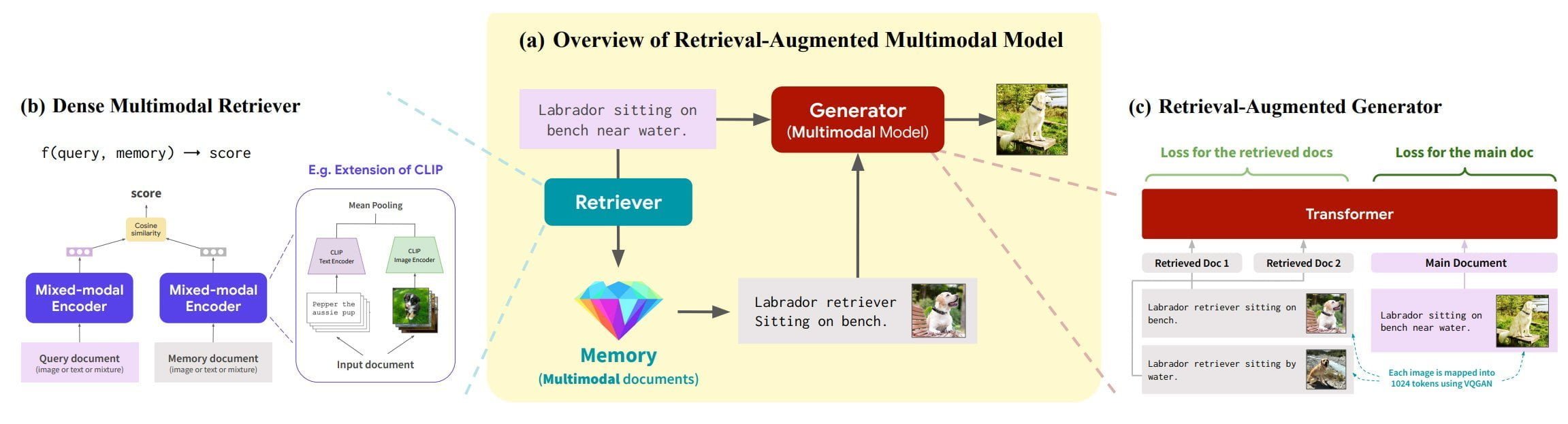
Beide Datenströme werden dann an den multimodalen Generator geleitet, der anschließend Text, Bild oder beides generiert. RA-CM3 kann die externen Bild- und Text-Daten nutzen, um etwa Bilder näher an den Anforderungen des Prompts zu generieren oder korrekte Bild-Unterschriften zu generieren. Durch die Datenbank kann das Modell etwa einen bestimmten Berg, ein bestimmtes Gebäude oder ein Monument deutlich besser in ein neues Bild verarbeiten.

Mit den externen Informationen kann das Modell zudem Bilder besser vervollständigen. RA-CM3 zeige außerdem die Fähigkeit zur One-Shot- und Few-Shot-Bildklassifizierung.

Insgesamt nutze RA-CM3 deutlich weniger Trainingsdaten und -ressourcen und sei zudem deutlich kleiner als vergleichbare Modelle, schreibt das Team. Für das größte Modell nutzten die Forschenden 150 Millionen Bilder und drei Milliarden Parameter. Die Qualität der generierten Bilder liege im Schnitt jedoch noch unter denen der deutlich größeren Modelle von OpenAI oder Google.
Allerdings zeigt sich auch bei RA-CM3 der Effekt der Skalierung: Das größte Modell liegt vor den kleineren Varianten und das Team geht davon aus, dass noch größere Modelle deutlich besser werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.