Meta hat eine neue Version von data2vec veröffentlicht: data2vec 2.0.
Update vom 29. Dezember 2022:
Metas weiterentwickelter Lernalgorithmus für unterschiedliche Modalitäten ist deutlich schneller als der Vorgänger.
Knapp elf Monate nach Veröffentlichung von data2vec zeigt Metas KI-Abteilung eine verbesserte Version des multimodalen Lernalgorithmus. Mit data2vec sei es viel einfacher, Fortschritte in einem Bereich der KI-Forschung, etwa beim Textverständnis, auf andere Bereiche wie die Bildsegmentierung oder Übersetzung zu übertragen, so Meta. Data2vec 2.0 kann wie der Vorgänger Sprache, Bild und Text verarbeiten, lernt jedoch deutlich schneller.
Data2vec 2.0 sei wesentlich effizienter und übertreffe die starke Leistung der ersten Version, so das Unternehmen. Es erreiche etwa die gleiche Genauigkeit wie ein weit verbreiteter Algorithmus für Computer Vision, sei dabei aber 16-mal schneller.
Data2vec 2.0 lernt kontextualisierte Repräsentationen
Ähnlich wie der Vorgänger sagt data2vec 2.0 kontextualisierte Repräsentationen von Daten vor statt lediglich die Pixel in einem Bild, Wörter in einer Text-Passage oder den Sound in einer Sprachdatei.
Konkret lernt der Algorithmus etwa das Wort Bank basierend auf dem kompletten Satz, in dem dieses Wort vorkommt und lernt so schneller die richtige Bedeutung des Wortes zu repräsentieren - also etwa als Finanzinstitut.
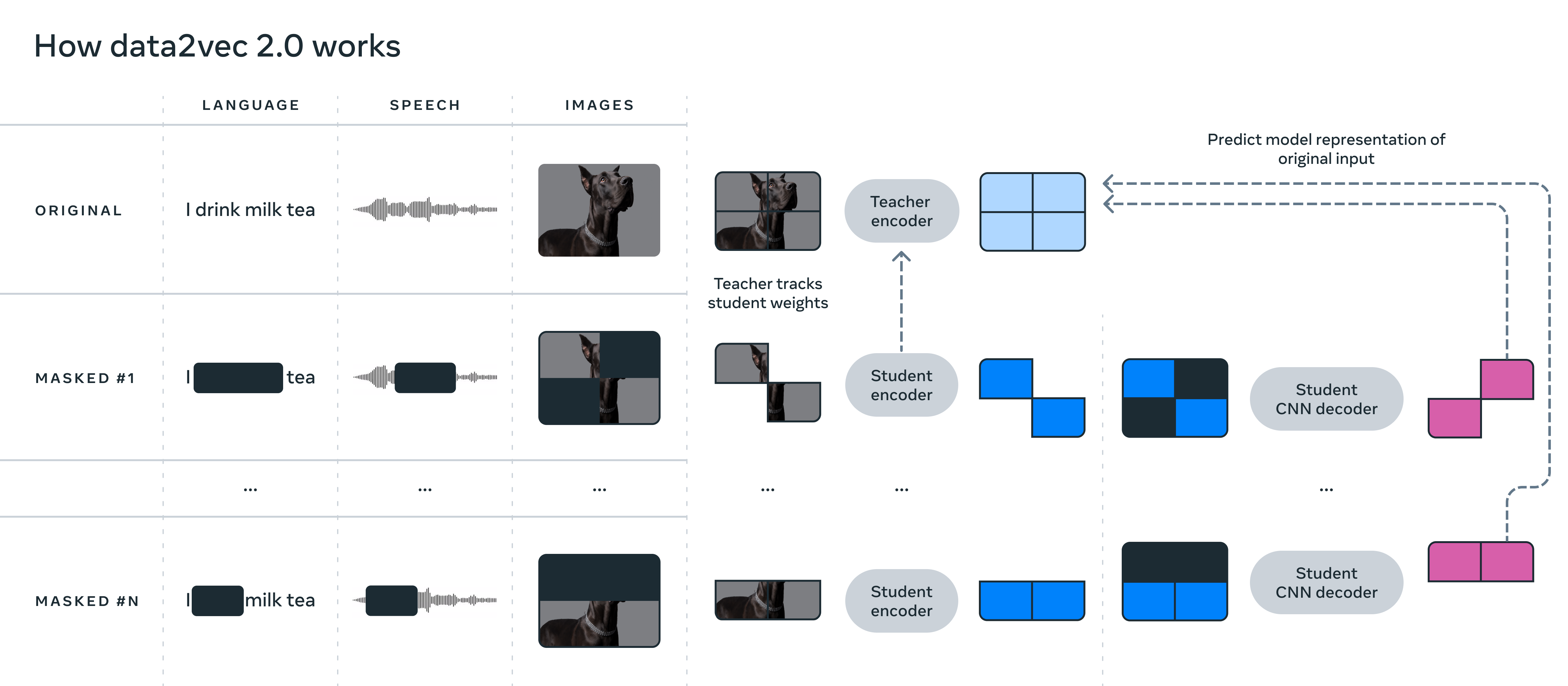
Meta vermutet, dass diese Kontextualisierung für die schnelle Lernleistung des Algorithmus verantwortlich ist. Um die Effizienz zu erhöhen, setzt das Team zudem auf Studenten-Netze, die von einem Lehrer-Netz lernen, sowie auf einen CNN- statt auf einen Transformer-Decoder.
Meta hofft, dass effizientere Algorithmen wie data2vec 2.0 zu Maschinen führen werden, die extrem komplexe Daten verstehen können wie den Inhalt eines ganzen Films.
Beispiele und Code gibt es auf Github.

Ursprünglicher Artikel vom 22. Januar 2022:
Meta stellt einen Lernalgorithmus vor, der selbstüberwachtes Lernen für unterschiedliche Modalitäten und Aufgaben ermöglicht.
Die meisten KI-Systeme lernen noch immer überwacht mit gelabelten Daten. Doch die Erfolge des selbstüberwachten Lernens bei großen Sprachmodellen wie GPT-3 und jüngst Bildanalyse-Systemen wie Metas SEER oder Googles Vision Transformer zeigen deutlich, dass Künstliche Intelligenz, die selbstständig die Strukturen von Sprachen oder Bildern lernt, flexibler und leistungsfähiger sind.
Bisher benötigen Forschende jedoch noch verschiedene Trainingsregimes für unterschiedliche Modalitäten, die nicht miteinander kompatibel sind: GPT-3 vervollständigt im Training Sätze, ein Vision Transformer Bildausschnitte und ein Spracherkennungssystem sagt fehlende Geräusche voraus. Alle KI-Systeme arbeiten daher mit anderen Datentypen, mal Pixel, mal Wörter, mal Audio-Wellenform. Diese Diskrepanz hat etwa zur Folge, dass Forschungsfortschritte für eine Art von Algorithmus sich nicht automatisch auf einen anderen übertragen lassen.
Metas data2vec verarbeitet verschiedene Modalitäten
Forschende von Metas AI Research stellen jetzt einen einzelnen Lernalgorithmus vor, mit dem ein KI-System mit Bildern, Text oder gesprochener Sprache trainiert werden kann. Der Algorithmus trägt den Namen"data2vec", eine Anspielung auf den word2vec-Algorithmus, der eine Grundlage für die Entwicklung großer Sprachmodelle darstellt. Data2vec vereint den Trainingsprozess der drei Modalitäten und erreicht in Benchmarks die Leistung bestehender Alternativen für einzelne Modalitäten.
Data2vec umgeht die Notwendigkeit verschiedener Trainingsregimes für unterschiedliche Modalitäten mit zwei Netzwerken, die zusammenarbeiten. Das sogenannte Teacher-Netz berechnet zuerst eine interne Repräsentation etwa eines Hunde-Bildes. Interne Repräsentationen bestehen unter anderem aus den Gewichtungen im neuronalen Netz. Anschließend maskieren die Forschenden einen Teil des Hunde-Bildes und lassen das Student-Netz ebenfalls eine interne Repräsentation des Bildes berechnen.
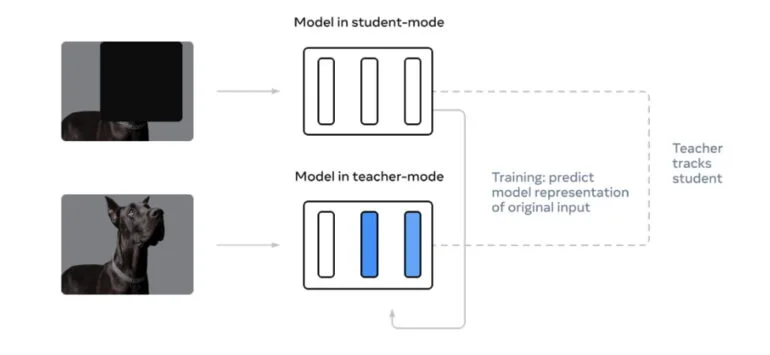
Das Student-Netz muss jedoch die Repräsentation des vollständigen Bildes vorhersagen. Doch statt mit weiteren Bildern zu lernen, wie etwa der Vision Transformer, lernt das Student-Netz, stattdessen die Repräsentationen des Teacher-Netzes vorherzusagen.
Da dieses das komplette Bild verarbeiten konnte, erlernt das Student-Netz mit zahlreichen weiteren Trainingsdurchgängen immer besser, die Teacher-Repräsentationen und damit die kompletten Bilder vorherzusagen.
Da das Student-Netz nicht direkt die Pixel im Bild vorhersagt, sondern stattdessen die Repräsentationen des Teacher-Netzes, aus denen dann Pixel rekonstruiert werden können, funktioniert die gleiche Methode auch für andere Daten wie Sprache oder Text. Durch diesen Zwischenschritt über Repräsentationsprognosen ist Data2vec für alle Modalitäten geeignet.
Data2vec soll KI helfen, allgemeiner zu lernen
Im Kern geht es den Forschenden darum, allgemeiner zu lernen: "KI sollte in der Lage sein, viele verschiedene Aufgaben zu lernen, auch solche, die ihr völlig fremd sind. Wir wollen, dass eine Maschine nicht nur die in ihren Trainingsdaten gezeigten Tiere erkennt, sondern sich auch an neue Lebewesen anpassen kann, wenn wir ihr sagen, wie sie aussehen", schreibt das Team von Meta. Die Forschenden folgen damit der Vision von Metas KI-Chef Yann LeCun, der im Frühjahr 2021 das selbstüberwachte Lernen als die "dunkle Materie der Intelligenz" bezeichnete.
Meta steht mit seinen Bemühungen, selbstüberwachtes Lernen für mehrere Modalitäten zu ermöglichen, nicht allein da. Im März 2021 veröffentlichte Deepmind Perceiver, ein Transformer-Modell, das Bilder, Audio, Video und Cloud-Point-Daten verarbeiten kann. Das wurde allerdings noch überwacht trainiert.
Im August 2021 stellte Deepmind dann Perceiver IO vor, eine verbesserte Variante, die aus verschiedenen Eingangsdaten eine Vielzahl von Ergebnissen erzeugt und sich so für den Einsatz in der Sprachverarbeitung, der Bildanalyse oder dem Verstehen multimodaler Daten wie Videos eignet. Perceiver IO verwendet allerdings noch unterschiedliche Trainingsregimes für verschiedene Modalitäten.
Metas Forschende planen nun weitere Verbesserungen und wollen möglicherweise die data2vec-Lernmethode mit Deepminds Perceiver IO kombinieren. Vortrainierte Modelle von data2vec gibt es auf Metas Github.