Metas KI-Modell sagt Gehirnaktivität genauer vorher als ein einzelner Hirnscan
Kurz & Knapp
- Metas KI-Modell TRIBE v2 sagt auf Basis von fMRI-Trainingsdaten vorher, wie das menschliche Gehirn auf Bilder, Töne und Sprache reagiert. Es trifft die typische Hirnreaktion dabei oft besser als eine einzelne reale Messung.
- Bei kontrollierten Experimenten repliziert das Modell klassische neurowissenschaftliche Befunde am Computer, etwa die korrekte Zuordnung spezialisierter Hirnregionen für Gesichter, Orte oder Sprache. Das könnte teure Laborzeit in der Hirnforschung künftig deutlich reduzieren.
- Das Modell behandelt das Gehirn allerdings nur als passiven Empfänger, deckt lediglich drei Sinneskanäle ab und arbeitet mit der trägen zeitlichen Auflösung von fMRI. Code, Gewichte und eine interaktive Demo sind frei verfügbar.
Ein neues KI-Modell von Meta sagt voraus, wie das menschliche Gehirn auf Bilder, Töne und Sprache reagiert. In Tests traf es die typische Hirnreaktion oft besser als die Messung einer einzelnen Person.
Für jedes neue Experiment benötigt die Hirnforschung neue Aufnahmen. Das macht neurowissenschaftliche Studien langsam und teuer. KI-Forscher von FAIR bei Meta wollen diesen Engpass mit einem KI-Modell umgehen, das Gehirnaktivität vorhersagt, statt sie zu messen.
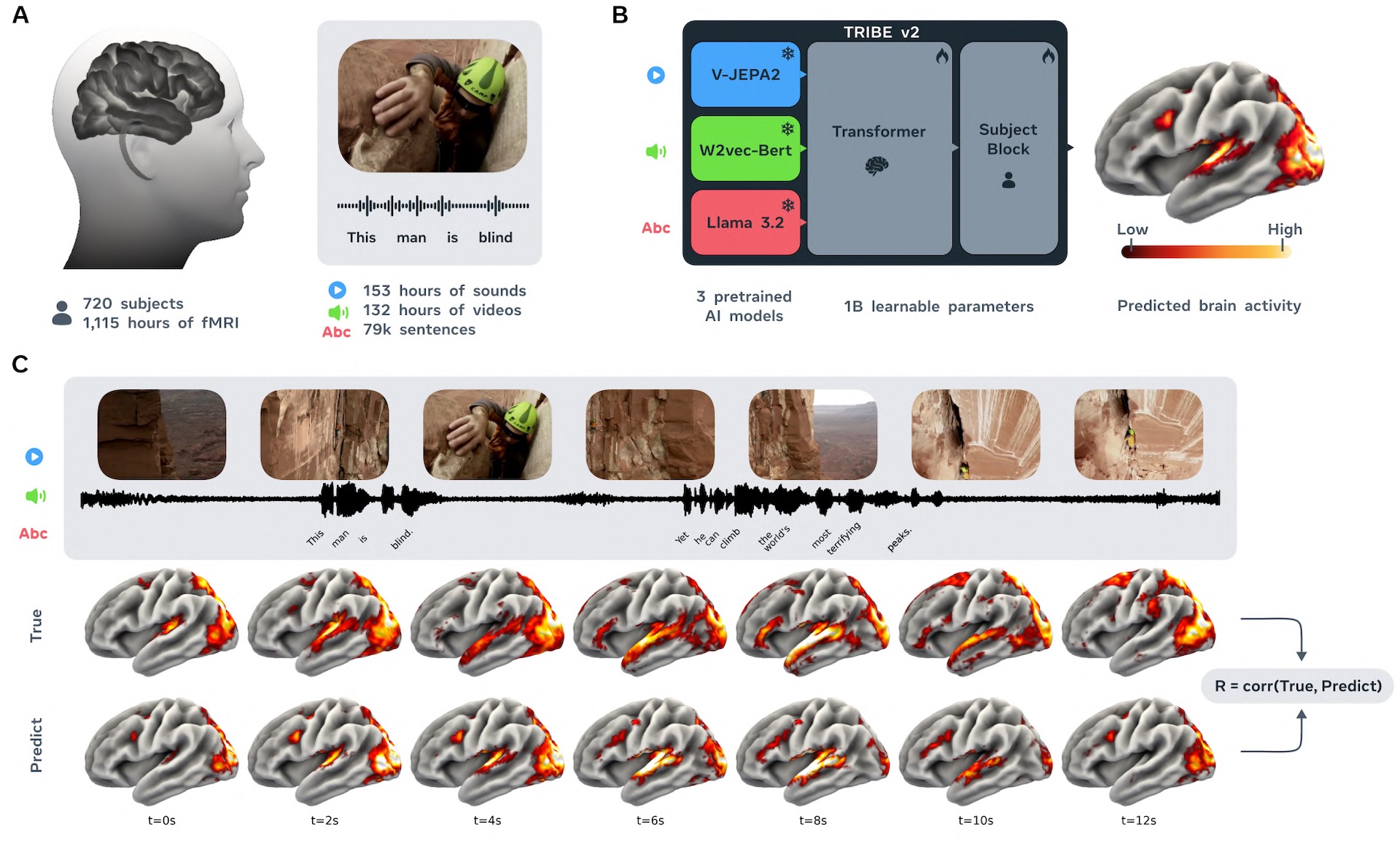
Das Modell heißt TRIBE v2 und wurde laut dem zugehörigen Paper mit mehr als 1.000 Stunden an fMRI-Daten von 720 Probanden trainiert. Die funktionelle Magnetresonanztomographie (fMRI) misst Gehirnaktivität indirekt über Veränderungen im Blutfluss und der Sauerstoffversorgung. TRIBE v2 soll auf Basis dieser Daten vorhersagen können, wie ein Gehirn auf beliebige visuelle, auditive und sprachliche Reize reagiert.
Drei Meta-Modelle liefern die Eingaben
TRIBE v2 verarbeitet drei Eingabekanäle in Form von Video, Audio und Text. Für jeden Kanal nutzt es ein bereits vortrainiertes KI-Modell von Meta als Vorverarbeitung, nämlich Llama 3.2 für Text, Wav2Vec-Bert-2.0 für Audio und Video-JEPA-2 für Video. Diese Modelle wandeln die Rohdaten in Embeddings um, die erfassen, was in einem Bild zu sehen, in einem Ton zu hören oder in einem Satz zu lesen ist.
Ein Transformer verarbeitet diese Darstellungen dann gemeinsam. Er lernt dabei Muster, die über einzelne Stimuli, Aufgaben und Personen hinweg gelten. Eine letzte, personenspezifische Schicht übersetzt das Ergebnis in eine Gehirnkarte mit 70.000 Voxeln. Voxel sind die dreidimensionalen Bildpunkte, aus denen ein fMRI-Scan besteht.
Weniger Rauschen als echte Hirnscans
Einzelne fMRI-Aufnahmen sind von Natur aus verrauscht. Herzschlag, Kopfbewegungen und Geräteartefakte verzerren das Signal. Wenn Forscher wissen wollen, wie ein Gehirn typischerweise auf einen bestimmten Reiz reagiert, müssen sie deshalb viele Aufnahmen mitteln.
TRIBE v2 umgeht dieses Problem, indem es direkt eine bereinigte Durchschnittsreaktion vorhersagt. In den Tests korrelierte diese Vorhersage stärker mit dem tatsächlichen Gruppendurchschnitt als die Aufnahme der meisten einzelnen Probanden. Am deutlichsten zeigte sich das im Datensatz des Human Connectome Project, der mit einem 7-Tesla-Scanner aufgenommen wurde und damit eine deutlich höhere Signalqualität bietet als die üblichen 3-Tesla-Geräte. Hier erreichte TRIBE v2 eine doppelt so hohe Korrelation mit der Gruppenantwort wie der Median der Einzelprobanden.
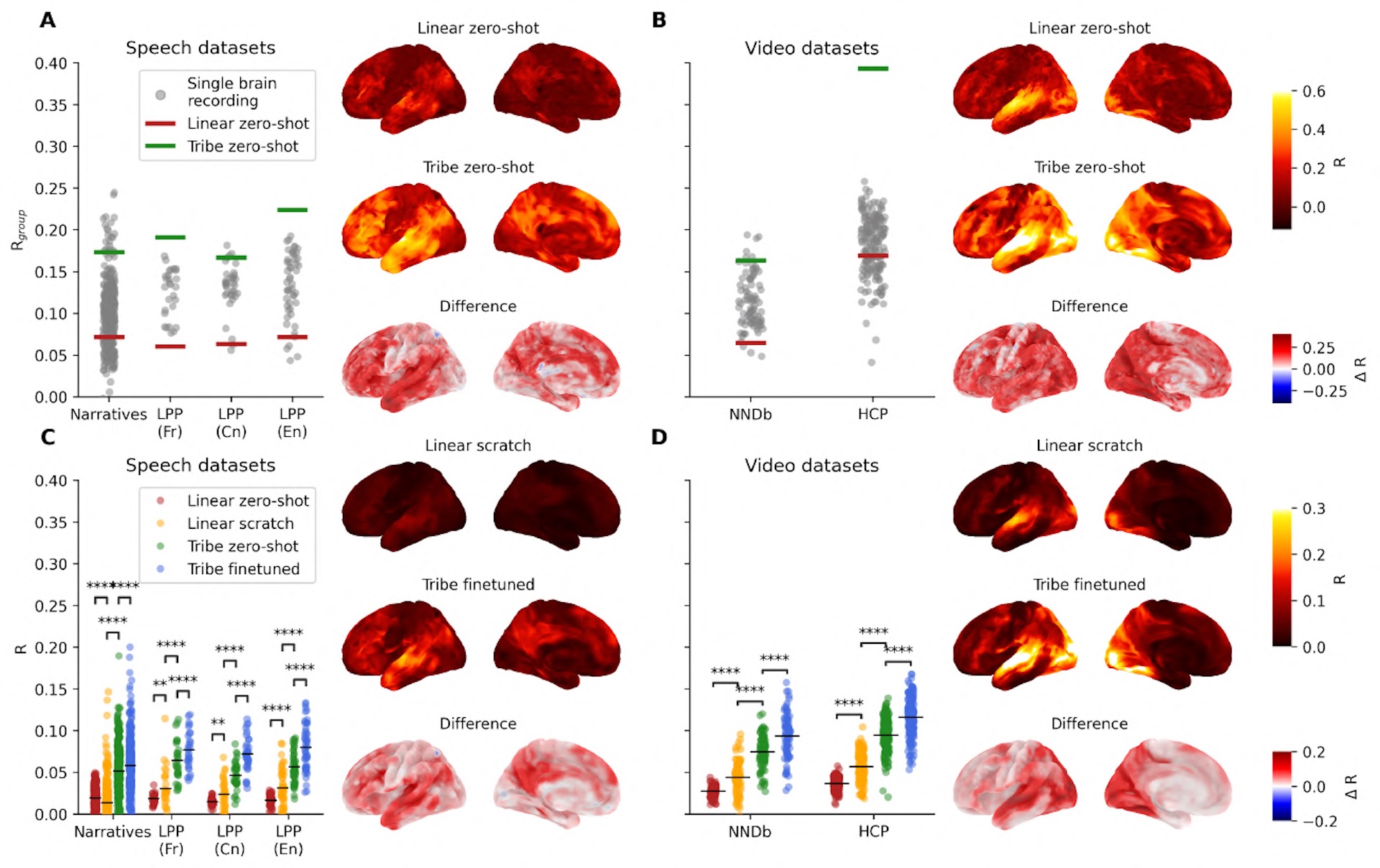
Gegenüber optimierten linearen Modellen, dem bisherigen Standardverfahren für solche Vorhersagen, erzielte TRIBE v2 laut dem Paper signifikante Verbesserungen über alle Datensätze hinweg. Bereits die Vorgängerversion TRIBE v1, die nur mit vier Probanden trainiert wurde und lediglich 1.000 statt 70.000 Voxel vorhersagte, hatte den Algonauts 2025 Wettbewerb als bestes von 263 Teams gewonnen.
Die Vorhersagegenauigkeit von TRIBE v2 steigt stetig mit der Menge der Trainingsdaten und hat noch kein Plateau erreicht. Das deutet darauf hin, dass das Modell von wachsenden fMRI-Datenbanken weiter profitieren wird. Dieses Muster erinnert an die Skalierungsgesetze großer Sprachmodelle, bei denen mehr Trainingsdaten ebenfalls vorhersagbar zu besseren Ergebnissen führen.
Jahrzehnte an Laborergebnissen am Computer repliziert
Die Forscher testeten TRIBE v2 mit alltagsnahen Reizen wie Filmen und Podcasts, bei denen viele Sinneseindrücke gleichzeitig auf das Gehirn einströmen, und zusätzlich mit gezielt isolierten Reizen, wie sie in der klassischen Hirnforschung üblich sind. Bei solchen kontrollierten Experimenten wird etwa ein einzelnes Bild für eine Sekunde eingeblendet, um die Reaktion einer bestimmten Hirnregion zu messen. Dafür nutzten die Forscher Versuchsprotokolle aus dem Individual Brain Charting Datensatz, einer Sammlung etablierter neurowissenschaftlicher Experimente, und ließen das Modell vorhersagen, welche Hirnareale aktiv werden sollten.
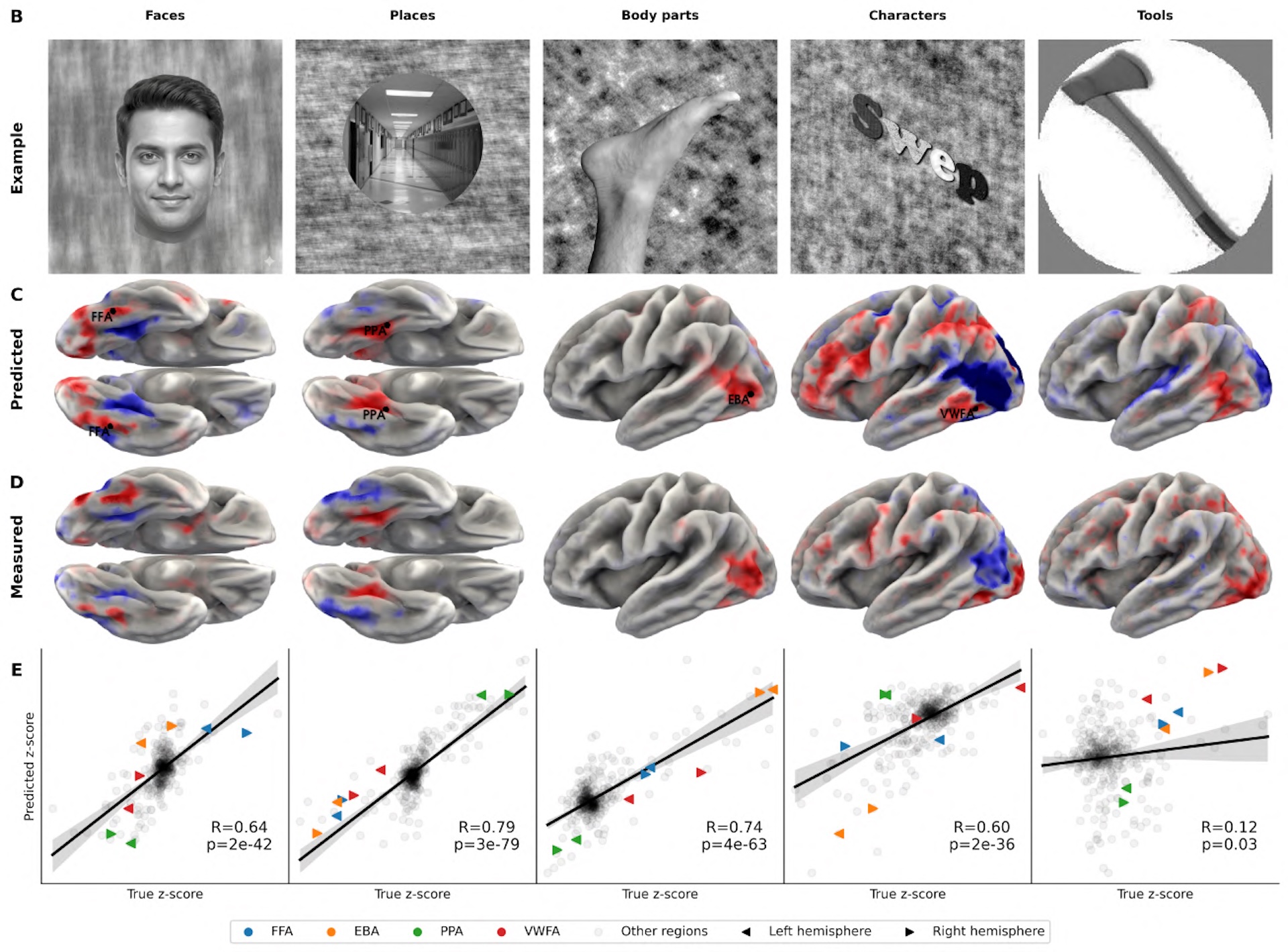
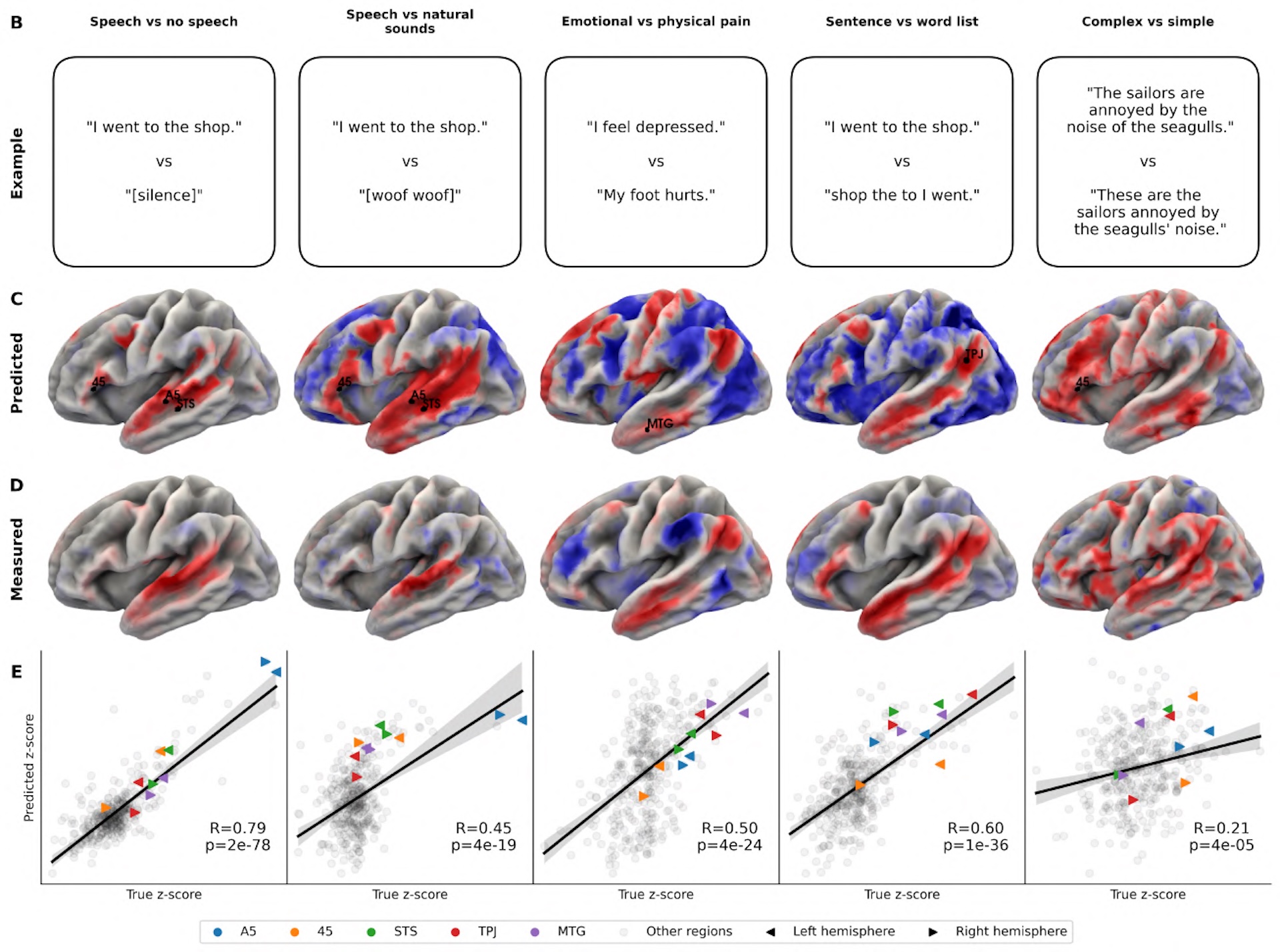
Bei visuellen Experimenten, in denen Bilder von Gesichtern, Orten, Körpern und Schriftzeichen gezeigt wurden, identifizierte TRIBE v2 die jeweils bekannten spezialisierten Hirnregionen korrekt. Bei Sprachexperimenten lokalisierte es das Sprachnetzwerk, unterschied die Verarbeitung von emotionalem und physischem Schmerz und zeigte die erwartete stärkere Aktivierung der linken Hirnhälfte bei ganzen Sätzen im Vergleich zu Wortlisten.
Diese Ergebnisse stimmen qualitativ mit Befunden überein, die in Jahrzehnten empirischer Forschung mit echten Probanden gewonnen wurden. Für die Neurowissenschaft könnte das bedeuten, dass sich Experimente künftig am Computer vorplanen lassen, bevor teure Laborzeit eingesetzt wird.
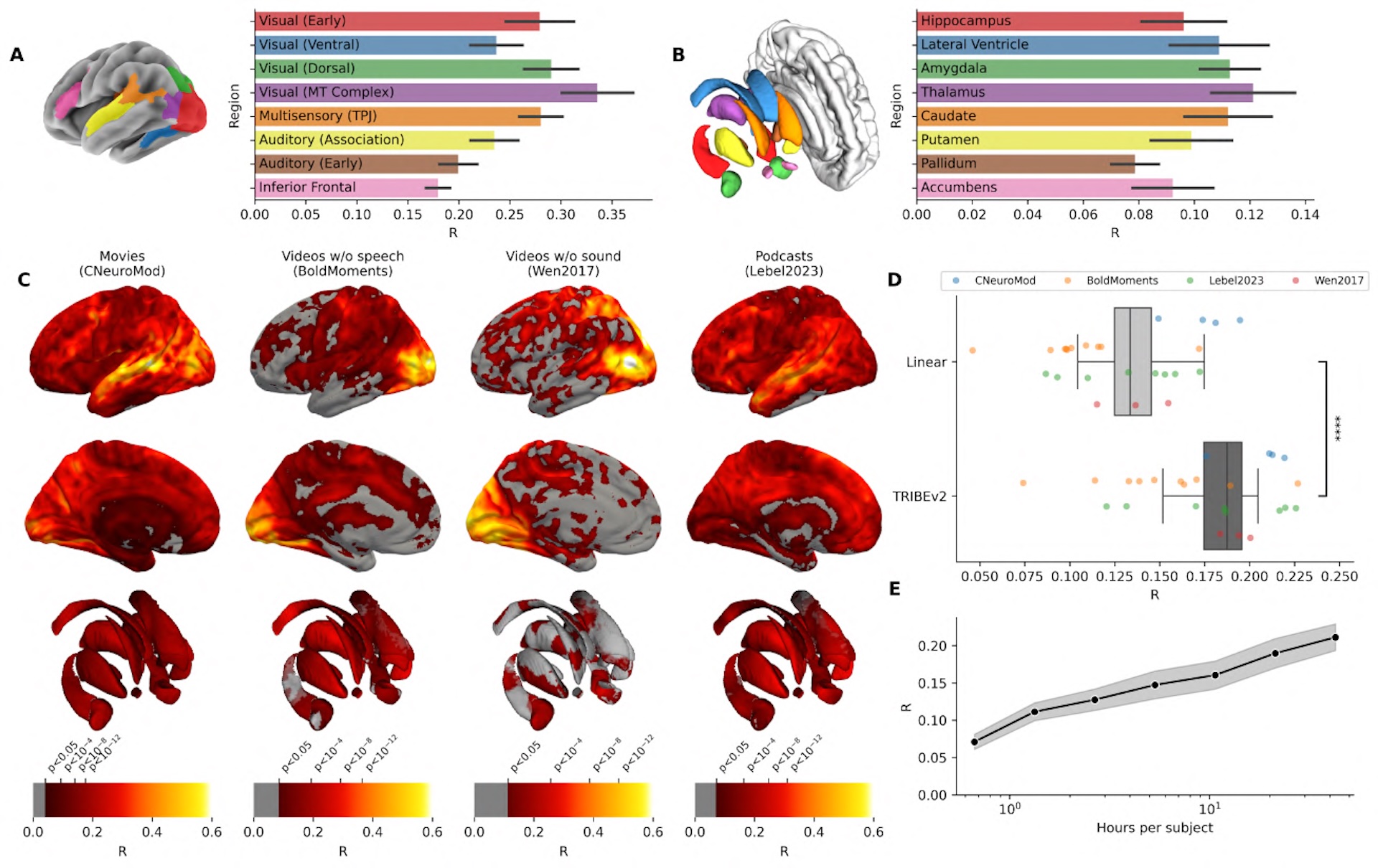
Welcher Sinneskanal welche Hirnregion anspricht
Durch das gezielte Abschalten einzelner Eingabekanäle lässt sich mit TRIBE v2 nachvollziehen, wie stark jeder Sinneskanal einzelne Hirnregionen beeinflusst. Die Ergebnisse decken sich mit dem, was aus der Hirnforschung bekannt ist. Audio sagt die Aktivität nahe dem Hörzentrum am besten vorher, Video die der Sehrinde, Text die der Sprachareale und von Teilen des Stirnhirns.
Dort, wo das Gehirn Informationen aus mehreren Sinneskanälen zusammenführt, bringt die Kombination aller drei Eingaben den größten Gewinn. An der Schnittstelle zwischen Schläfen-, Scheitel- und Hinterhauptslappen verbessert sich die Vorhersage um bis zu 50 Prozent gegenüber einzelnen Kanälen.
Eine statistische Zerlegung der letzten Modellschicht ergab zudem fünf Muster, die bekannten funktionellen Netzwerken des Gehirns entsprechen, darunter das primäre Hörzentrum, das Sprachnetzwerk, die Bewegungserkennung, das sogenannte Default-Mode-Netzwerk und das visuelle System. Das Default-Mode-Netzwerk ist unter anderem bei Tagträumen und Selbstreflexion aktiv.
Passiver Beobachter mit begrenztem Sensorium
Die Einschränkungen von TRIBE v2 sind noch immer erheblich: fMRI misst Gehirnaktivität nur indirekt über den Blutfluss und mit einer Verzögerung von mehreren Sekunden. Die schnelle Dynamik neuronaler Signale im Millisekundenbereich bleibt unsichtbar. Das Modell erfasst zudem nur drei von vielen Sinneskanälen. Geruch, Tastsinn und Gleichgewicht fehlen.
Eine grundlegendere Einschränkung ist, dass TRIBE v2 das Gehirn als passiven Empfänger von Sinneseindrücken behandelt. Es modelliert nicht, wie das Gehirn aktiv Entscheidungen trifft oder Handlungen steuert. Auch Entwicklungsverläufe und klinische Krankheitsbilder kann das Modell bislang nicht abbilden, was laut den Forschern ein vorrangiges Ziel für künftige Versionen bleibt.
Meta sieht drei Anwendungsfelder für das Modell, nämlich die Planung neurowissenschaftlicher Experimente, die Entwicklung hirnähnlicherer KI-Architekturen und langfristig die Diagnostik von Hirnerkrankungen. Code, Modellgewichte und eine interaktive Demo sind frei zugänglich.
Metas KI-Forschungsabteilung FAIR arbeitet seit Jahren an der Schnittstelle zwischen Gehirn und KI. Vor einem Jahr zeigte das Team, dass ein KI-Modell getippte Sätze allein aus nicht-invasiven Gehirnaufnahmen mit bis zu 80 Prozent Genauigkeit rekonstruieren kann.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren