Metas MoCha-KI generiert komplette Charakteranimationen aus Text

Metas neues KI-System soll erstmals die Generierung vollständiger Charakteranimationen mit synchroner Sprache und natürlichen Bewegungen ermöglichen.
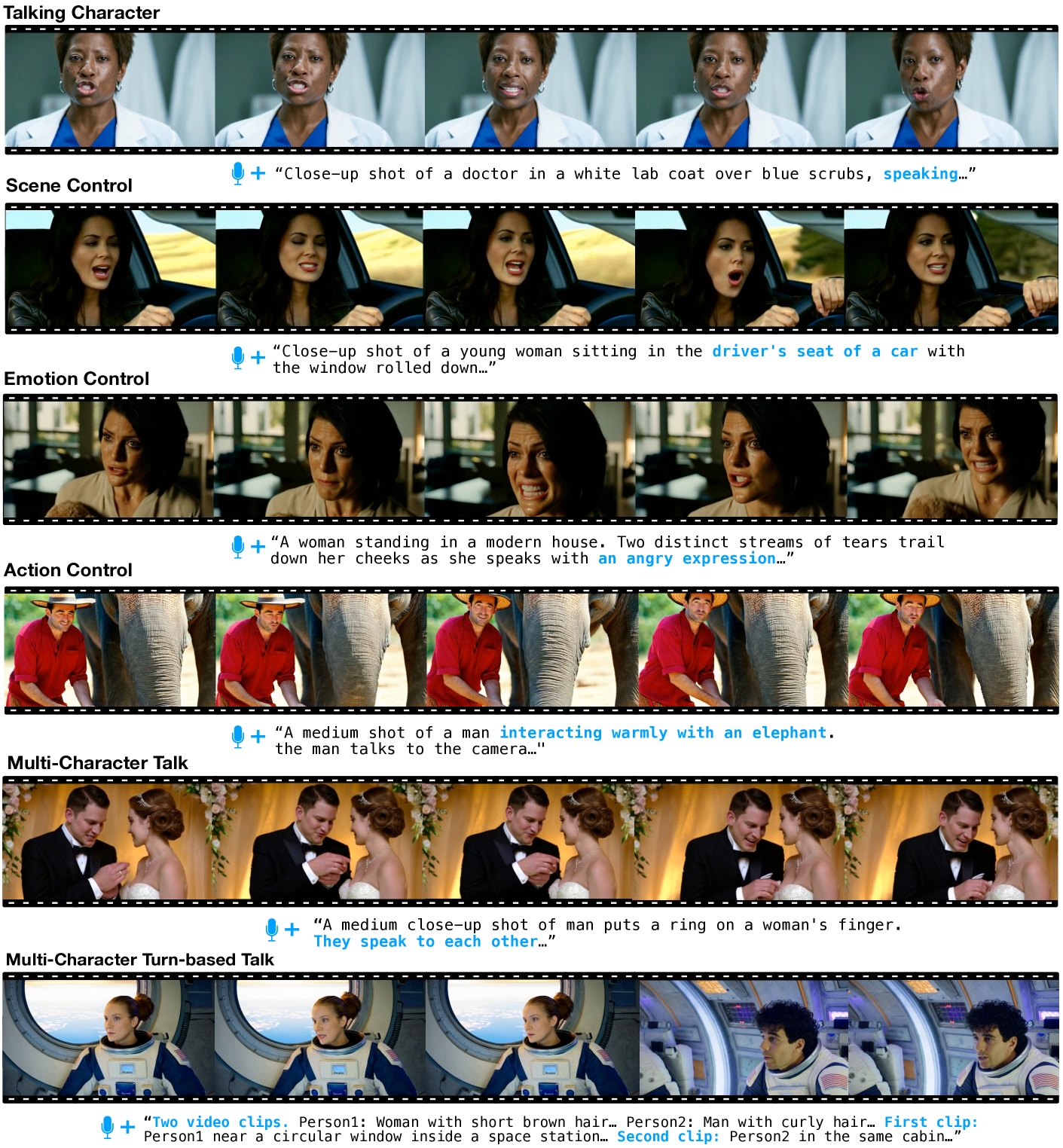
Forschende von Meta und der kanadischen University of Waterloo haben mit MoCha ein KI-System entwickelt, das einen Durchbruch in der KI-gestützten Videogenerierung darstellen könnte. Laut der Forschungsarbeit kann das System zum ersten Mal vollständige Charakteranimationen direkt aus Sprache und Text erzeugen - von der Lippensynchronisation über Gestik bis zu Interaktionen zwischen mehreren Figuren.
Anders als bisherige KI-Modelle beschränkt sich MoCha nicht auf reine Gesichtsanimationen. Nach Angaben der Forschenden kann das System Ganzkörperanimationen erzeugen und diese in verschiedenen Kameraperspektiven darstellen.
Die bisher gezeigten Beispielclips zeigen Menschen überwiegend in Close-up-Einstellungen oder Halbnahen. Dabei bewegen sich Arme und Oberkörper der dargestellten Personen nach Angaben der Forscher überzeugend synchron zum gesprochenen Inhalt mit.
Video: Wei et al.
Das System basiert auf einem Diffusions-Transformer-Modell mit 30 Milliarden Parametern. Es erzeugt Videos in HD-Auflösung mit einer Länge von etwa fünf Sekunden bei 24 Bildern pro Sekunde und liegt damit auf Niveau vieler aktueller Videomodelle
Neue Technik verbessert Lippensynchronisation
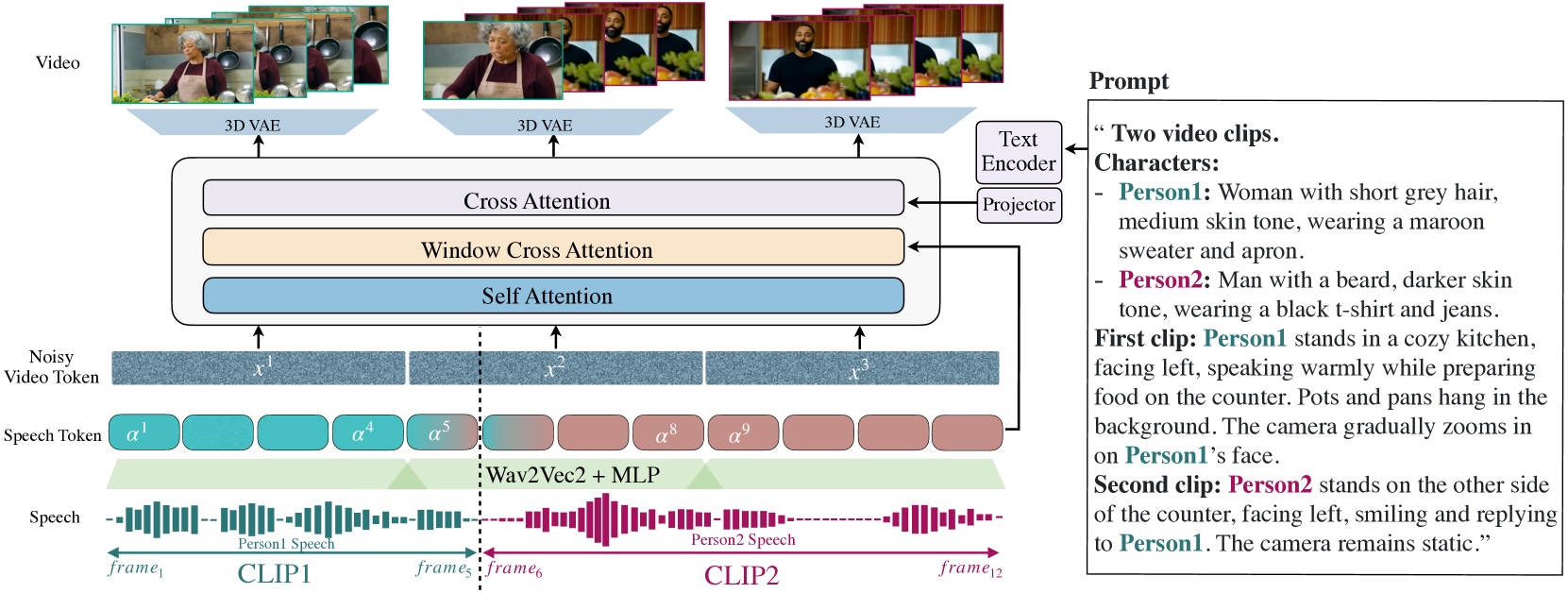
Eine zentrale Innovation ist der "Speech-Video Window Attention"-Mechanismus. Bisherige Modelle haben zwei grundlegende Probleme: Zum einen werden Videos für die Verarbeitung zeitlich komprimiert, während die Audiodaten in voller Auflösung bleiben. Zum anderen können bei der parallelen Videogenerierung die Lippenbewegungen fälschlicherweise mit Lauten aus völlig anderen Zeitpunkten verknüpft werden.
MoCha löst dies, indem jeder Videoframe nur auf ein begrenztes Zeitfenster der Audiodaten zugreifen kann. Das System berücksichtigt dabei, dass Lippenbewegungen primär von kurzen Audiosequenzen (1–2 Phoneme, die kleinste bedeutungsunterscheidende Lauteinheit in einer Sprache) abhängen, während Körperbewegungen eher dem gesamten Text folgen.
Für jeden generierten Frame werden neben den direkt zugehörigen Audiodaten auch jeweils ein Token davor und danach einbezogen. Dies sorgt für flüssigere Übergänge zwischen den Frames und eine präzisere Lippensynchronisation.
Für das Training des Systems nutzte das Forschungsteam nach eigenen Angaben 300 Stunden sprachgesteuertes Videomaterial, das aufwendig gefiltert wurde. Die Herkunft der ursprünglichen Videos wird in der Forschungsarbeit nicht offengelegt.
Um die Vielfalt der möglichen Bewegungen zu erhöhen, kombinierten die Forschenden diese Daten mit textbasierten Videosequenzen. Diese Mischung soll es MoCha ermöglichen, ein breites Spektrum an Ausdrucksformen und Interaktionen zu erlernen.
Mehrere Charaktere in einer Szene
MoCha kann auch Szenen mit mehreren Charakteren erstellen. Dafür entwickelten die Forschenden ein spezielles Prompt-System: Die Charaktere werden einmal mit ihren Eigenschaften definiert und dann mit einfachen Tags wie 'Person1' oder 'Person2' markiert. Diese Tags können in den verschiedenen Szenen wiederverwendet werden, was lange, wiederholte Beschreibungen der Charaktere überflüssig machen und die Steuerung vereinfachen soll.
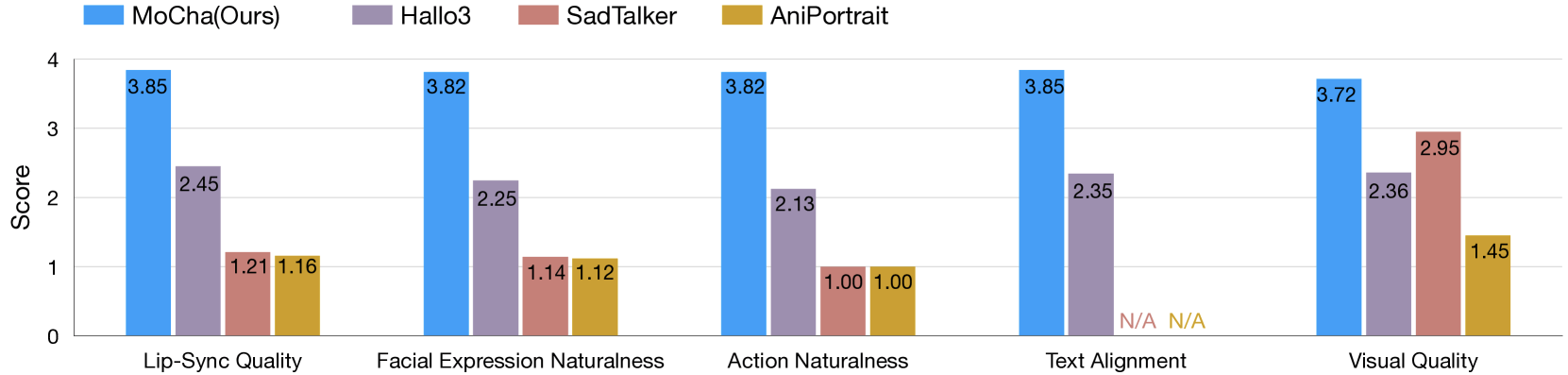
Nach Angaben der Forschenden schnitt MoCha in Tests mit 150 verschiedenen Szenarien besser ab als vergleichbare Systeme. Die Überlegenheit zeigte sich sowohl bei der Lippensynchronisation als auch bei der Natürlichkeit der Bewegungen. Unabhängige Tester bewerteten die generierten Videos als realitätsnah.
Metas KI-Abteilung forscht bereits seit einiger Zeit an Videomodellen. Zuletzt hat das US-Unternehmen mit Movie Gen eine große Ausgabe zur Videosynthese präsentiert. Auch der Social-Media-Konzern ByteDance entwickelt parallel verschiedene KI-Systeme zur Animation menschlicher Gesichter. Dazu gehören nach Angaben des Unternehmens die Modelle INFP, OmniHuman-1 und Goku.
Laut der Forschungsarbeit sehen die Entwickler für MoCha verschiedene kommerzielle Einsatzmöglichkeiten. Das System könnte bei der Entwicklung digitaler Assistenten und virtueller Avatare zum Einsatz kommen. Auch Anwendungen in der Werbung und im Bildungsbereich seien denkbar.
Ob Meta das System quelloffen veröffentlichen oder es bei einer Forschungsdemo bleiben wird, ist bisher nicht bekannt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.