Metas neue KI-Architektur soll grundlegende Schwächen heutiger KI-Systeme überwinden

Mit dem Byte Latent Transformer (BLT) will Meta ein grundlegendes Problem aktueller Sprachmodelle lösen: Sie sollen lernen, mit einzelnen Zeichen und Buchstaben umzugehen.
Aktuelle Sprachmodelle haben eine fundamentale Schwäche: Sie können nicht zuverlässig mit einzelnen Buchstaben arbeiten. Daher scheitern die Systeme an einfachen Aufgaben wie dem Zählen der Buchstaben "n" im Wort "Mayonnaise".
Der Grund liegt in der Funktionsweise der Modelle: Sie zerlegen Texte in kurze Zeichenketten, sogenannte Token, und verlieren damit den direkten Zugriff auf einzelne Buchstaben. Zudem erschwert das Token-Verfahren die Integration neuer Datenformate wie Bild und Ton. Die Industrie setzt dennoch auf Token, da das direkte Training auf Bytes rechenintensiv und teuer ist.
Bytes statt Tokens
Meta stellt nun mit dem Byte Latent Transformer (BLT) eine Alternative vor, die dieses Problem lösen soll. Statt Wörter in Tokens zu zerlegen, arbeitet der BLT direkt auf Byte-Ebene. Um den Rechenaufwand dennoch in Grenzen zu halten, fasst er die Bytes dynamisch zu Patches zusammen.
Dabei passt sich die Größe der Patches automatisch an die Komplexität der Daten an. Einfacher, vorhersehbarer Text wird in größere Patches zusammengefasst, während komplexe Textpassagen in kleinere Einheiten aufgeteilt werden. Diese kleineren Patches werden mit mehr Rechenleistung verarbeitet. So kann BLT Rechenressourcen gezielter einsetzen.
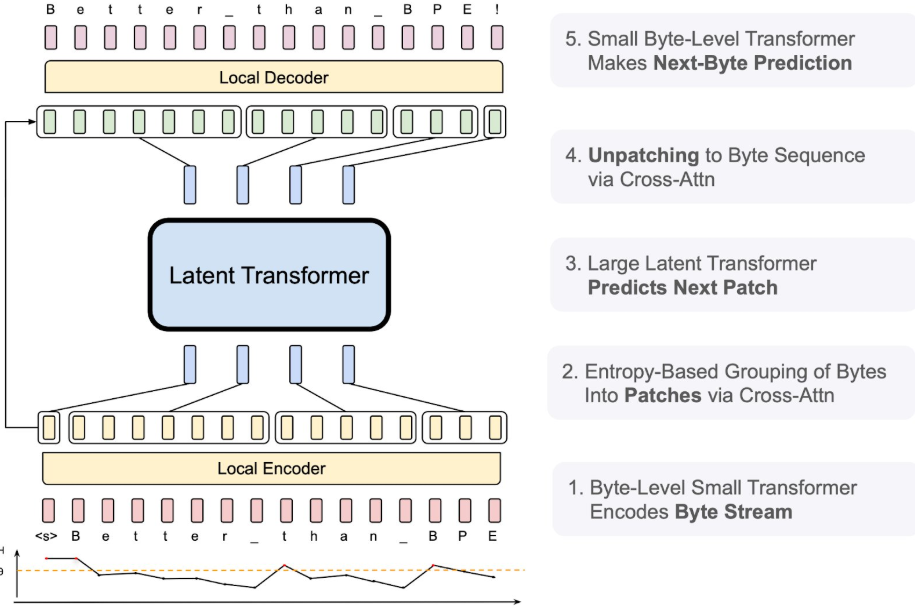
Die Patches werden in mehreren Schritten verarbeitet: Zunächst werden die Bytes durch ein lokales Modell in Patches kodiert und gruppiert. Anschließend werden diese Patches durch einen großen latenten Transformer verarbeitet, bevor sie durch ein weiteres lokales Modell wieder in Bytes dekodiert werden, wo dann ein kleinerer Transformer das nächste Byte vorhersagt.
Bessere Skalierung und Robustheit
Wie Meta berichtet, übertrifft BLT mit nur 8 Milliarden Parametern sogar das deutlich größere Llama 3.1 bei Tests, die ein Verständnis auf Zeichenebene erfordern - und das, obwohl Llama mit 16-mal mehr Daten trainiert wurde.
Die Architektur ermöglicht laut den Meta-Forschern auch eine bessere Skalierung als bisherige Ansätze. Durch gleichzeitiges Vergrößern der Patch- und Modellgröße können sie die Leistung steigern, ohne die Kosten zu erhöhen. Bei ähnlicher Leistung seien Effizienzgewinne von bis zu 50 Prozent möglich.
Der vielleicht wichtigste Vorteil der neuen Architektur liegt laut Meta in ihrer Robustheit und Flexibilität. Die Forscher berichten von deutlich besseren Ergebnissen bei der Verarbeitung seltener Textsequenzen. Auch bei gestörten oder fehlerhaften Texten zeigt sich BLT resistenter als herkömmliche Modelle. Im folgenden Beispiel sieht man, wie sich die Zeichenfolge in einzelnen Wörtern per Prompt steuern lässt.
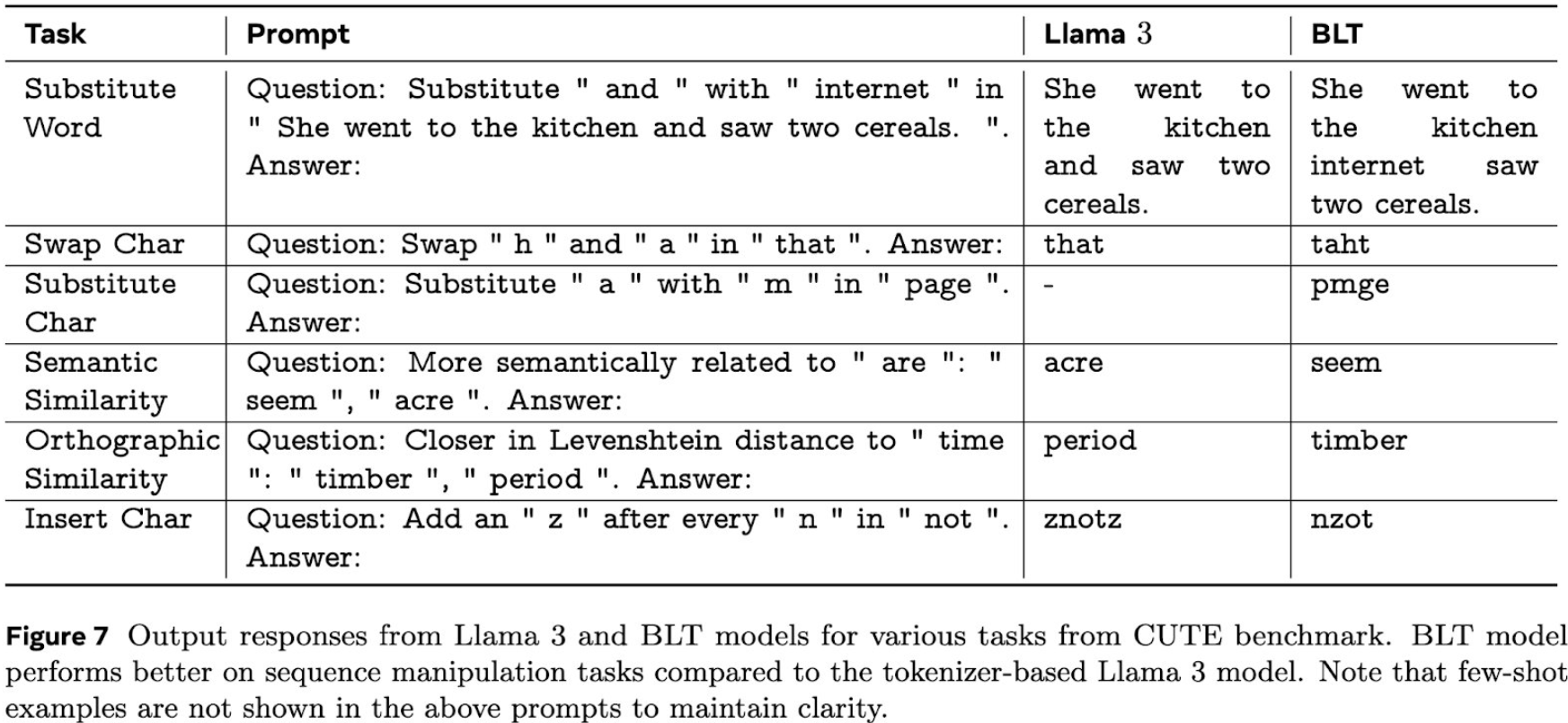
Die Entwicklung von BLT ist nicht der erste Versuch, die Nachteile von Tokenizern zu überwinden. Bereits im Mai 2023 stellte Meta mit MegaByte eine ähnliche, aber weniger dynamische Methode vor.
Der renommierte KI-Entwickler Andrej Karpathy bezeichnete die Abschaffung von Tokenizern schon damals als wichtiges Ziel für die Entwicklung von Sprachmodellen. Bisher konnte sich das Verfahren allerdings nicht durchsetzen.
Meta hat den Code und die Forschungsergebnisse bei Github veröffentlicht. Das Unternehmen hofft, damit Fortschritte in Bereichen wie der Verarbeitung von ressourcenarmen Sprachen, Programmcode und der Faktentreue von KI-Systemen zu beschleunigen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.